






前言:
终于,Stability AI发布了自家最强的模型Stable Diffusion 3.5,而且是一个全家桶,包含三个版本。
链接:https://huggingface.co/stabilityai
Stable Diffusion 3.5 可以满足科研人员、业务爱好者、初创公司和企业的多样化需求,其中包括:
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

Stable Diffusion 3.5 Large:该基础模型拥有 80 亿参数,性能优于竞品模型并且响应迅速,是 Stable Diffusion 系列中最强大的模型。该模型非常适合 1 百万像素分辨率的专业用例。
Stable Diffusion 3.5 Large Turbo:该模型是 Stable Diffusion 3.5 Large 的蒸馏版本,只需四步即可生成高质量图像,速度远快于Stable Diffusion 3.5 Large。
Stable Diffusion 3.5 Medium:该模型拥有 25亿参数,采用改进的MMDiT-X架构和训练方法,可在消费级硬件上「开箱即用」,在质量和定制易用性之间实现了平衡。该模型能够生成分辨率在0.25到2百万像素之间的图像。
可以看到,以上模型均有较大幅度的升级。Stability AI 表示,在今年 6 月发布Stable Diffusion 3 Medium后发现模型没有满足社区的期望。因此在听到反馈意见后没有采取快速修复措施,而是「花时间进一步开发了一个新版本,以推进改造视觉媒体的使命。」
模型开发技巧
在开发模型时,Stability AI优先考虑可定制性,以提供灵活的构建基础。为了实现这一点,他们将Query-Key Normalization集成到transformer块中,稳定了模型训练过程并简化了进一步的微调和开发。
为了支持下游灵活性,Stability AI还必须做出一些权衡。使用不同种子的同一提示可能会产生很大的输出差异,这是有意为之,因为它有助于在基础模型中保留更广泛的知识库和多样化的风格。不过,缺乏特异性的提示可能会导致输出不确定性增加,并且美学水平可能会有所不同。
尤其是针对Medium版本,Stability AI 对架构和训练协议进行了一些调整,以提高质量、连贯性和多分辨率生成能力。
模型的优势
据介绍,Stable Diffusion 3.5各版本模型在以下多个方面表现出色:
可定制性:轻松微调模型以满足特定创作需求,或根据定制的工作流程构建应用程序。
高效性能:经过优化,均可在标准消费级硬件上运行,尤其是 Stable Diffusion 3.5 Medium 和 Stable Diffusion 3.5 Large Turbo 型号。
多样化输出:无需大量提示,即可创建代表全世界的图像,而不仅仅是一种肤色和特征的人。

风格多样:能够生成各种风格和美感的图片,如 3D、摄影、绘画、线条艺术以及几乎任何可以想象到的视觉风格。

可见,在这一代的模型中,Stability AI已经提前考虑好了手机等设备的运行。
此外,Stability AI表示,Stable Diffusion 3.5 Large在prompt adherence方面处于领先地位,并且在图像质量方面可与更大的型号相媲美。
Stable Diffusion 3.5 Large Turbo在同类模型中,推理速度最快,同时在图像质量和及时性方面保持了高度竞争力,即使与类似尺寸的非蒸馏模型相比也是如此。
Stable Diffusion 3.5 Medium 的表现优于其他中型型号,在prompt adherence和图像质量之间实现了平衡,使其成为高效、高质量性能的首选。
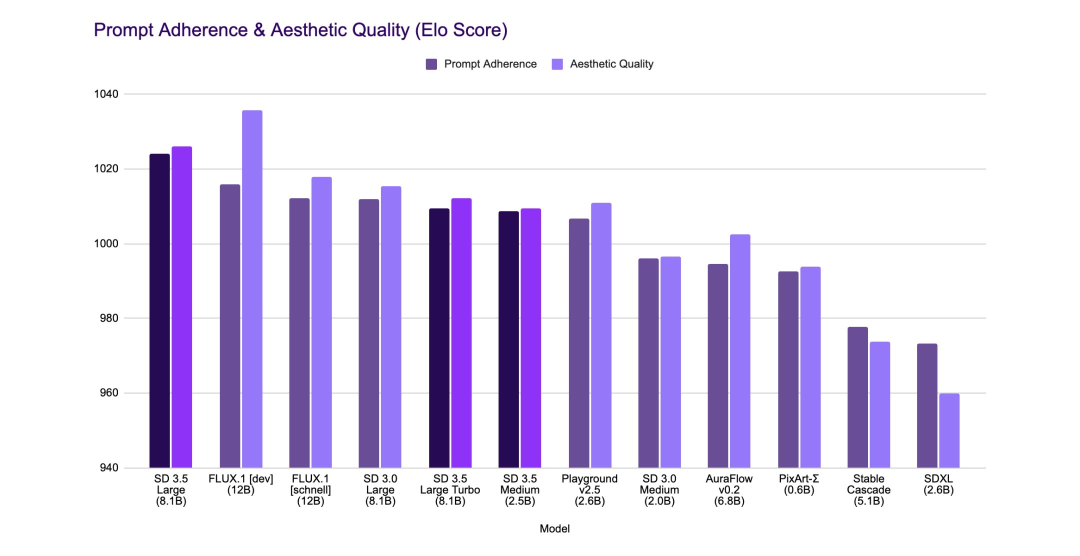

有人第一时间对比了Stable Diffusion 3.5 Large与FLUX 1.1 pro的生图效果。

除了Hugging Face上托管的模型以外,还有更多访问新模型的方式:
-
Stability AI API:https://platform.stability.ai/docs/api-reference#tag/Generate/paths/1v2beta1stable-image1generate1sd3/post
-
Replicate:https://replicate.com/stability-ai/stable-diffusion-3.5-large
-
ComfyUI:https://blog.comfy.org/sd3-5-comfyui/
-
以及DeepInfra
此外,在新版本模型中,Stability AI 从开发的早期阶段就引入了安全、负责任的 AI 实践。
最后,Stability AI 表示,Stable Diffusion 3.5 Medium 将在 10 月 29 日公开发布。不久之后,ControlNets 也将推出,为各种专业用例提供高级控制功能。
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









