










 本文提出用于目标检测的relation model,通过物体外观和几何特征交互建模物体关系,可嵌入现有网络。该模块受NLP注意力模块启发,引入几何权重。可提高目标检测性能,在去重步骤代替NMS,还能应用于多种视觉任务,作者进行了多组对比实验。
本文提出用于目标检测的relation model,通过物体外观和几何特征交互建模物体关系,可嵌入现有网络。该模块受NLP注意力模块启发,引入几何权重。可提高目标检测性能,在去重步骤代替NMS,还能应用于多种视觉任务,作者进行了多组对比实验。
1. 摘要
目前所有主流的目标检测系统仍然只是单独的识别目标,不利用它们之间的关系。作者提出了一个relation model,通过objects的外观特征和几何形状的interaction来对物体之间的关系建模。模块不改变特征维数,可以嵌入到目前各种网络结构。
主要应用:
- 提高目标检测性能。
- 应用在去重步骤,代替NMS,避免NMS需要手动设置参数的问题。
实现了第一个端到端的目标检测器。
2. 研究背景
目前主流的目标检测方法大多遵循 R-CNN模式,找到一组稀疏的候选区域,对候选区域执行目标分类和边界框回归,最后用NMS消除重复检测。
relation module进展缓慢的原因之一是物体和物体之间的关系存在很多不规范的问题,物体以不同的类别、不同的尺寸,位于图像的任意位置,其数量也可能因不同图像而异。
本文提出的方法受到NLP领域的attention module启发,主要区别在于原先的注意力权重扩展到两个部分:外观特征权重和几何权重。
relation module不限于目标检测中的应用,在其它视觉任务中如实例分割、行为识别、对象关系检测、字幕、VQA(视觉问答)等领域也可以广泛应用。
3. 相关工作
Object relation in post-processing:
作为后续处理步骤,通过考虑物体关系,对检测到的物体重新打分,如联合出现。相关工作有尝试更复杂的关系模型,并额外考虑了位置和大小。这些方法在早期的深度学习时代取得很大成功,但在深层卷积网络中效果不好。可能是因为深度卷积网络通过大的感受野隐含的考虑了上下文关系。
Sequential relation modeling:
序列模型,如LSTM和SMN,早期检测到的对象用于帮助寻找下一个对象,训练方法通常很复杂,而且没有证明改进了当前最先进的检测方法,只是简单的前馈网络。我们的方法可以并行处理多个物体。
Human centered scenarios:
很多工作关注人和物体之间的关系,一般需要对关系的额外注释,如人的运动。我们的方法通用与对象和对象之间的关系,而且不需要额外的监督信息。
Duplicate removal:
该步骤最有效的方法仍然是启发式的需要手动设置参数的NMS。这个过程很明显需要使用关系模型,如NMS使用了简单的bounding box之间的关系,分数之间的关系。
Attention modules in NLP and physical system modeling:
注意力模块最近已经成功地应用于NLP领域和物理系统建模中。注意力模块可以很好地捕获这些问题的长期依赖关系。在NLP中,最近有一种趋势是通过注意力模型来取代重复的神经网络,支持并行化的方法和更有效的学习。
我们的方法是受这些工作的启发。将注意力模块扩展到对象检测的问题上。对于视觉对象关系的建模,它们的位置,或者一般意义上的几何特征,扮演着一个复杂而重要的角色。因此,模块引入了一个新的几何权重来捕获对象之间的空间关系。新的几何权重是平移不变的,对于视觉模型这是一个很重要的性质。
4. object relation module
Algorithm:
Input: N objects ( f A n , f G n ) n = 1 N {(f_A^n, f_G^n)}_{n=1}^N (fAn,fGn)n=1N
- hyper param: number of relations N r N_r Nr
- hyper param d k d_k dk: key feature dimension
- hyper param d g d_g dg: geometric feature embedding dimension
- learnt wights: { W K r , W Q r , W V r , W G r } r = 1 N r \{W_K^r,W_Q^r, W_V^r,W_G^r\}_{r=1}^{N_r} {WKr,WQr,WVr,WGr}r=1Nr
- for every ( n , r ) (n, r) (n,r) do:
- \qquad compute { W G m n , r } m = 1 N \{W_G^{mn,r}\}_{m=1}^N {WGmn,r}m=1N using Eq.(5)
- \qquad compute { W A m n , r } m = 1 N \{W_A^{mn,r}\}_{m=1}^N {WAmn,r}m=1N using Eq.(4)
- \qquad compute { W m n , r } m = 1 N \{W^{mn,r}\}_{m=1}^N {Wmn,r}m=1N using Eq.(3)
- \qquad compute f R r ( n ) f_R^r(n) fRr(n) using Eq.(2)
- end for
- output new feature { f A n } n = 1 N \{f_A^n\}_{n=1}^N {fAn}n=1N using Eq.(6)
模块示意图如下:
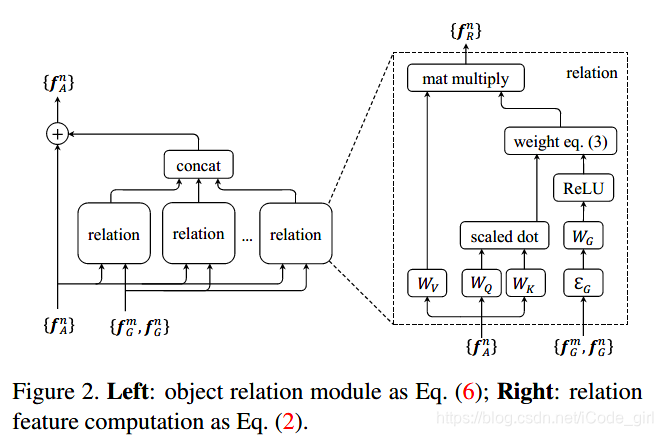
详细解释:
f
A
n
f_A^n
fAn代表第n个物体的apperance特征,即物体自身的颜色、大小、形状等外观特征。
f
G
n
f_G^n
fGn对应第n个物体的geometry特征,即物体的位置和大小(bounding box)。
这里有多个relation模块,可以类比神经网络中每层都会有很多不同的通道,以便于学习不同种类的特征。每个relation模块都用所有 object 的两个特征做输入,得到不同的relation 特征后再concat,和原来的外观特征以加法融合,作为物体的最终特征。

f
R
(
n
)
f_R(n)
fR(n) 表示第n个物体和所有物体集合的关系,是所有其它物体的外观权重经过
W
V
W_V
WV线性变换以后的加权和。
w
m
n
w^{mn}
wmn即为物体和物体之间的关系权重,几何特征的作用体现在在关系权重中。

公式分母是个归一化的项,重点看分子,
ω
m
n
ω_{mn}
ωmn主要第m个物体对于当前第n个物体在geometry上的权重
ω
G
m
n
ω^{mn}_G
ωGmn和在apperance上的权重
ω
A
m
n
ω^{mn}_A
ωAmn,它们各自的求法如下:

W
K
W_K
WK和
W
Q
W_Q
WQ是矩阵,起到变化维度的作用,把原始矩阵映射到子空间中,用点积衡量两个object的apperance特征关系。映射后的特征维度为
d
k
d_k
dk。

w
G
m
n
w_G^{mn}
wGmn 类似于ReLU操作,首先进行升维,将4维的几何特征(关于x,y,w,h的公式)升到
d
g
d_g
dg维空间。,
ε
G
ε_G
εG是attention module提出了可以在变换中保持不变性的操作向量。
参数计算:
在 Eq(2) 中的每个关系函数都由四个矩阵(WK、WQ、WG、WV)参数化,总共
4
N
r
4N_r
4Nr个。让
d
f
d_f
df表示输入特征
f
A
f_A
fA的维数.参数的数量是:
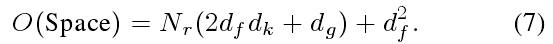
5. 应用
现在大多数目标检测器,可以分为以下四步:
- 生成全图特征;
- 生成局部特征;
- 执行实例识别;
- 执行去重操作。
目标关系模块在第二模块中可以直接应用到FC层之后,即从原来的:

改变为:

框架图:

r
1
,
r
2
r_1, r_2
r1,r2 代表重复次数。关系模块也需要所有候选的“边界框”作为输入。这个符号在这里被忽略了。
添加关系模块可以有效地提高实例识别的准确性。
目标关系模块可以在去重步骤中,代替NMS。

作者把duplicate removal当成一个二分类问题,对于每个ground truth,只有一个detected object被归为correct类,而其余的都是duplicate。
这个模块的输入是instance recognition模块的output,也就是一系列的detected objects,它们每个都有1024-d的特征,分类分数 s 0 s_0 s0还有bbox。而输出则是 s 0 ∗ s 1 s_0∗s_1 s0∗s1得到的最终分类分数。
那么 s 1 s_1 s1是怎么算的呢?首先,对于detected objects作者按照它们的scores对它们进行排名,然后将scores转化为rank,据作者说这样更加有效,随后rank信息会按照类似εG的求法映射到高维特征,然后这个rank特征和原先的appearence 特征通过 W f R W_{fR} WfR和 W f W_f Wf函数转变为128维特征,最后和输入的box特征相加,作为relation module的输入,输出通过sigmoid函数,得到 s 1 s_1 s1。
如何判断哪个detected object是correct,而哪些是duplicate?在这里,作者设置了一个阈值ηη,凡是IoU超过该阈值的样本都会被选择;接着,在选择的样本中,IoU值最大的为correct,其余为duplicate。当对定位要求比较高的时候,可以设置较高的ηη,相应的被选择的样本就会发生变化, s 1 s_1 s1也会发生变化,直接影响最终的分数。
作者认为这样做的好处如下:
- output的时候,NMS需要一个预设置的参数;而duplicate removal模块是自适应学习参数的。
- 通过设置不同的η,可以将模块变成多个二分类问题,并取其中最高的值作为输出,作者经过试验,证明这种方式较单一阈值的方式更可靠。
- 学习和检测使用同一个阈值时,效果最好。例如mAP0.5在η为0.5时的效果最好,mAP0.7同理。
- 最后,就是η的含义问题。之前也发过邮件和作者沟通,对方的回复是,η本质上代表的是分类和定位问题的权重,它的值设置得越高,说明网络越看重定位的准确性。
6. Experiment
作者主要使用了ResNet 50和101,用两个fc层作为baseline进行了很多对比实验。
包括:
- geometric feature特征的使用;
- N r N_r Nr的数量;
- relation modules的重复次数
- 效果的提升是源于relation module还是只是因为多加了几个层
- NMS和SoftNMS
- end2end和分阶段训练哪个更好
- etc…
[1] 全文翻译:https://www.cnblogs.com/Ann21/p/9787715.html
[2] 一些地方的理解:https://blog.youkuaiyun.com/qq_21949357/article/details/80369848
[3] https://blog.youkuaiyun.com/u013010889/article/details/79495029
[4] https://blog.youkuaiyun.com/tommorrow12/article/details/80755443
[5] 源码解读:https://blog.youkuaiyun.com/u014380165/article/details/80779712
最后:
目标检测算法综述: https://zhuanlan.zhihu.com/p/47474868
晚上去看了 比悲伤更悲伤的故事 ,贼适合减压。
比悲伤更悲伤的故事是一望无际的学海。
算是看完了吧。三月最后一天了。

















 5195
5195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









