介绍 🍒 Cherry Studio 是一款支持多种人工智能大型语言模型的桌面客户端,支持快速模型切换,并针对问题提供不同的模型响应。它兼容 Windows 和 Mac 平台💻,开源且免费,可帮助您提高工作和学习效率。 系列文章 《本地电脑搭建 StreamDiffusion:用眼睛见证实时人工智能创意 利用交互式高速扩散技术彻底改变图像生成》权重1,本地类 《使用本地 Llama 2 模型和向量数据库建立私有检索增强生成 (RAG) 系统 LangChain》权重1,llama类、本地类 《如何在自己的电脑上构建大语言模型,使用 LangChain(而不是 OpenAI)回答关于您的文档的问题》 权重2,本地类








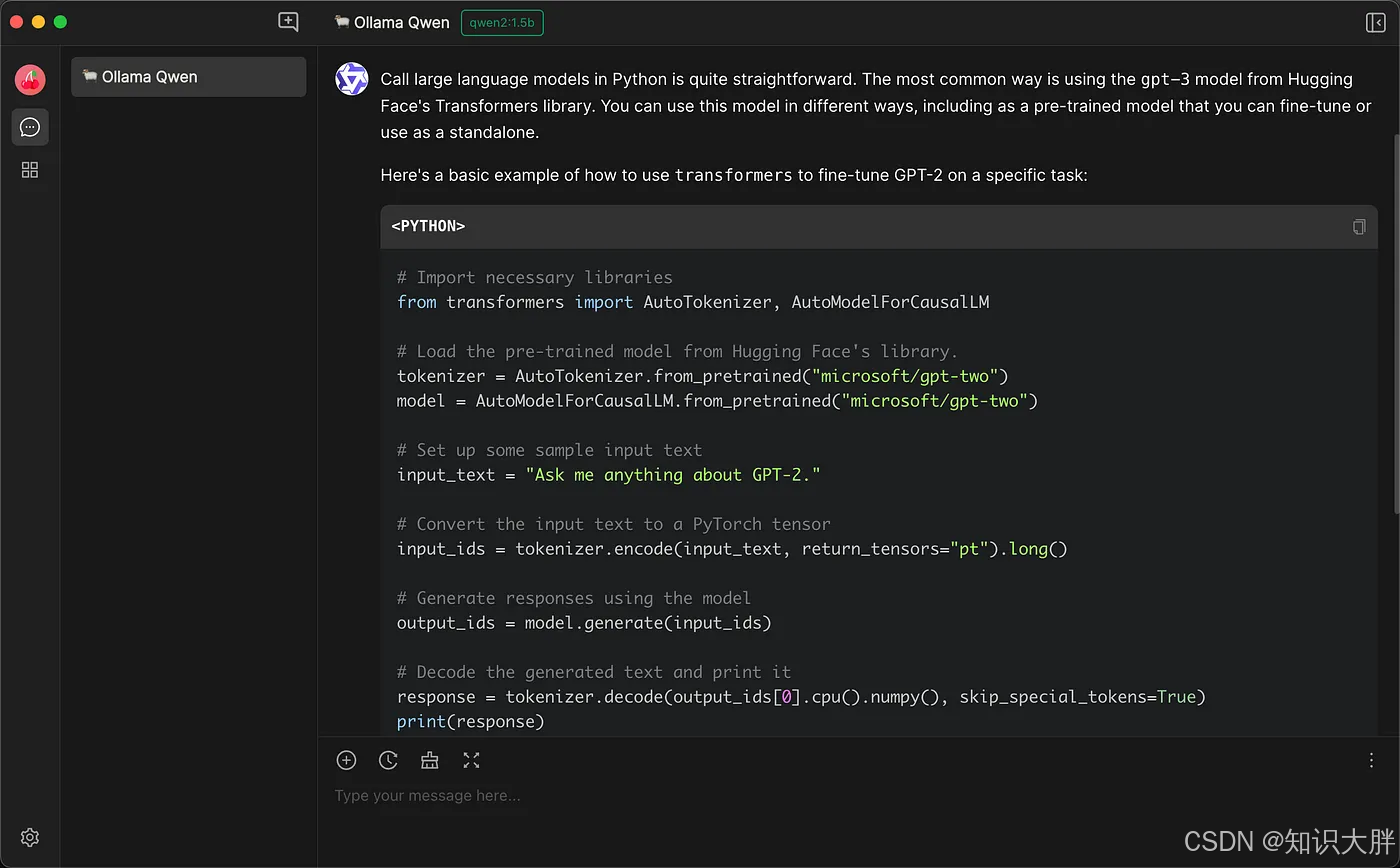

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 8589
8589
8589
8589
8589
8589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











