








1、概述
官网:https://hudi.apache.org
gitee:https://gitee.com/apache/Hudi
1.1 架构
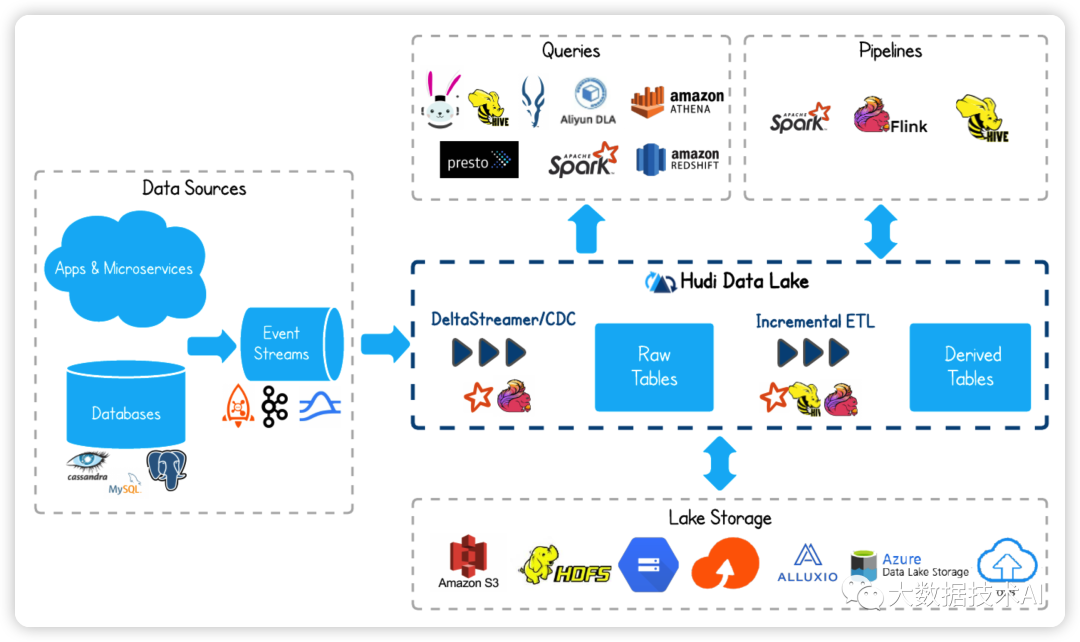
1.2 特点
-
Upserts, Deletes with fast, pluggable indexing.
-
Incremental queries, Record level change streams
-
Transactions, Rollbacks, Concurrency Control.
-
SQL Read/Writes from Spark, Presto, Trino, Hive & more
-
Automatic file sizing, data clustering, compactions, cleaning.
-
Streaming ingestion, Built-in CDC sources & tools.
-
Built-in metadata tracking for scalable storage access.
-
Backwards compatible schema evolution and enforcement
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









