




买回来的树莓派5只用CPU跑yolo还是很吃力,帧率只是个位数字。CPU连同GPU算力加在一起可能不到1TOPS。
正好看到树莓派有Hailo-8的AI加速扩展,于是买回来玩一玩。Hailo-8和Hailo-8L算力分别26TOPS和13TOPS。还是那个思路,够用就好。考虑到树莓派5 PCIE只有1条Lane,电源只有27W,还是Hailo-8L最合适。于是决定继续折腾一下。




经过测量原外壳正好,只需要把买的扩展板自带的螺丝柱换成一面带螺纹的螺丝柱,漏出部分16mm。安装完之后,扩展板下部分和散热片没干涉,盖上上盖空间正好。上电后指示灯正常,跑个示例成功加速识别。
BOM:
树莓派5 8G裸板 525
原装27瓦电源108
散热器+外壳29
铜螺柱 3.8
Hailo8L 579



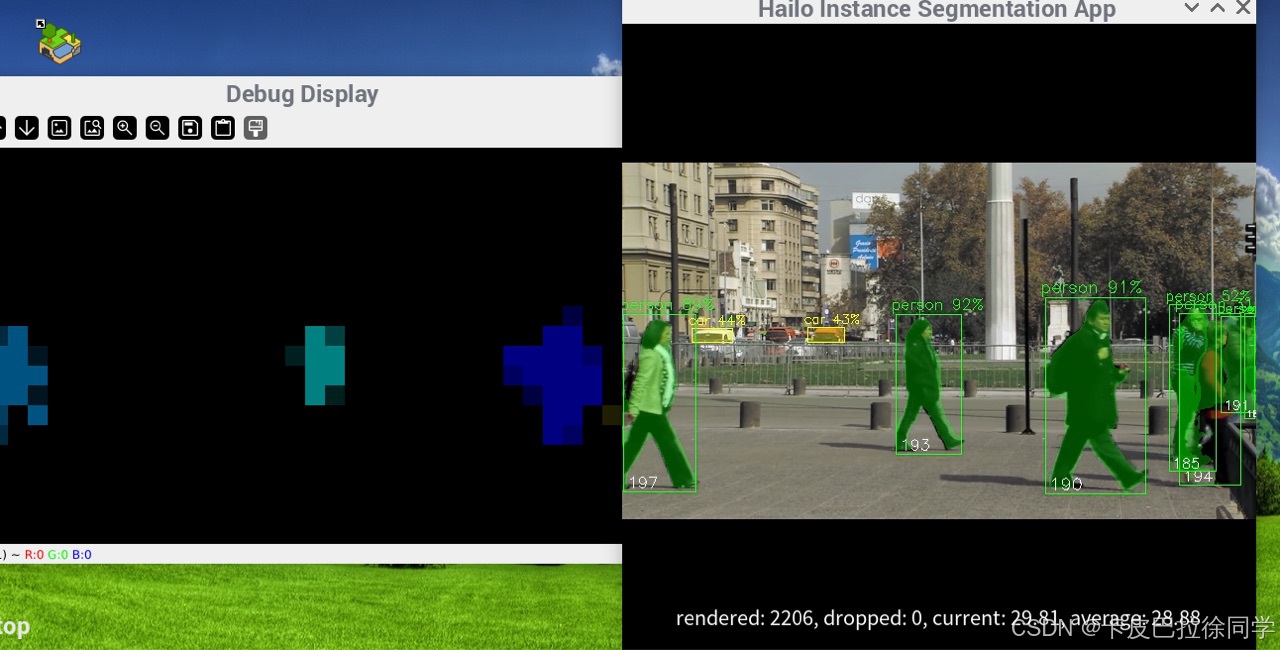
效果还是相当满意,毕竟在低功耗下能做到这样的推理速度还是很不可思议的。 测试例子帧率有些可以接近30fps。
不过需要注意Hailo-8L应用场景是边缘计算,加速低功耗设备具备AI推理能力。但是无法加速神经网络训练。
因为Hailo-8L 的架构针对推理任务进行了优化,采用了数据流计算和定制化硬件加速器,专门为高效执行神经网络的前向传播任务而设计。
而训练任务需要大量的反向传播和梯度计算,这些操作对硬件的要求与推理不同,需要较高能耗,而且与低功耗场景相违背。另外hef模型本身已经编译为只读测试,无法支持迭代式训练。
如果想学习机器学习,减少训练时间还是果断选择N卡GPU。如果是边缘计算AI应用,还是比较推荐。后续我会和FPGA加速方案再做一些横向的对比。
HAILO8目前官方对LLM是不支持的,编译器无法处理大语言模型,资源无法满足。不过我这边有一些思路去做混合推理的加速,大概思路就是实现一个lamacpp框架,去支持混合推理,对模型进行切分,CPU端实现理由机制,结合hailo8的pipeline机制,加速推理。需要做的东西很多,慢慢鼓捣,希望能够把deepseek7B模型跑起来。


















 5115
5115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









