




 本文详细介绍了Apache Flink 7.2 Hadoop版本的下载、本地及集群启动,WordCount示例,Hadoop单机和集群部署,文件操作,以及Flink在Hadoop集群中的YARN部署。还涵盖了问题排查和配置要点,如端口占用、目录管理等。
本文详细介绍了Apache Flink 7.2 Hadoop版本的下载、本地及集群启动,WordCount示例,Hadoop单机和集群部署,文件操作,以及Flink在Hadoop集群中的YARN部署。还涵盖了问题排查和配置要点,如端口占用、目录管理等。
Flink下载:
根据自己想要下载的版本,下载指定版本我下载的是7.2hadoop版本
解压后启动:
本地启动
[root@node01 flinkhadoop1.7.2]# bin/start-scala-shell.sh local
本地提交一个job
scala> benv.readTextFile("/home/admin/word.txt").flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1).print()

单机集群启动:
[root@node01 flinkhadoop1.7.2]# bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node01.
Starting taskexecutor daemon on host node01.
[root@node01 flinkhadoop1.7.2]# jps
28417 StandaloneSessionClusterEntrypoint
29013 Jps
28858 TaskManagerRunner
页面查看启动集群
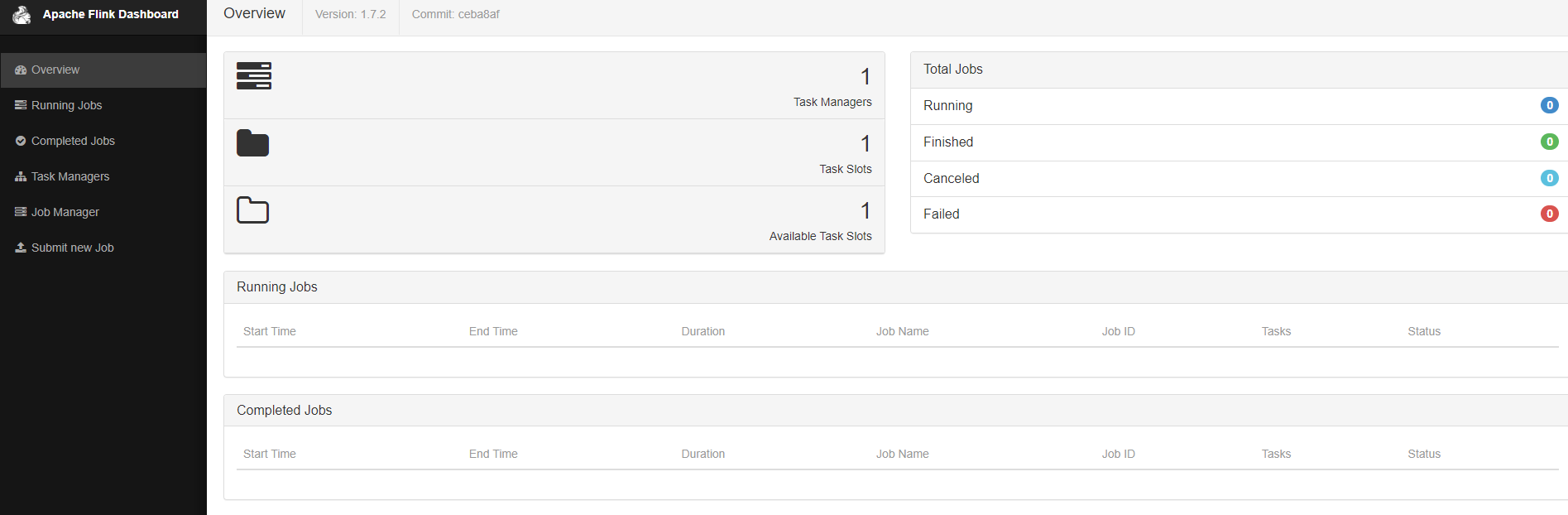
提交任务到flink 单节点集群
[root@node01 flinkhadoop1.7.2]# bin/flink run /home/admin/flinkhadoop1.7.2/examples/batch/WordCount.jar --input /home/admin/word.txt --output /home/admin/out

前端查看上传的任务
执行计划:
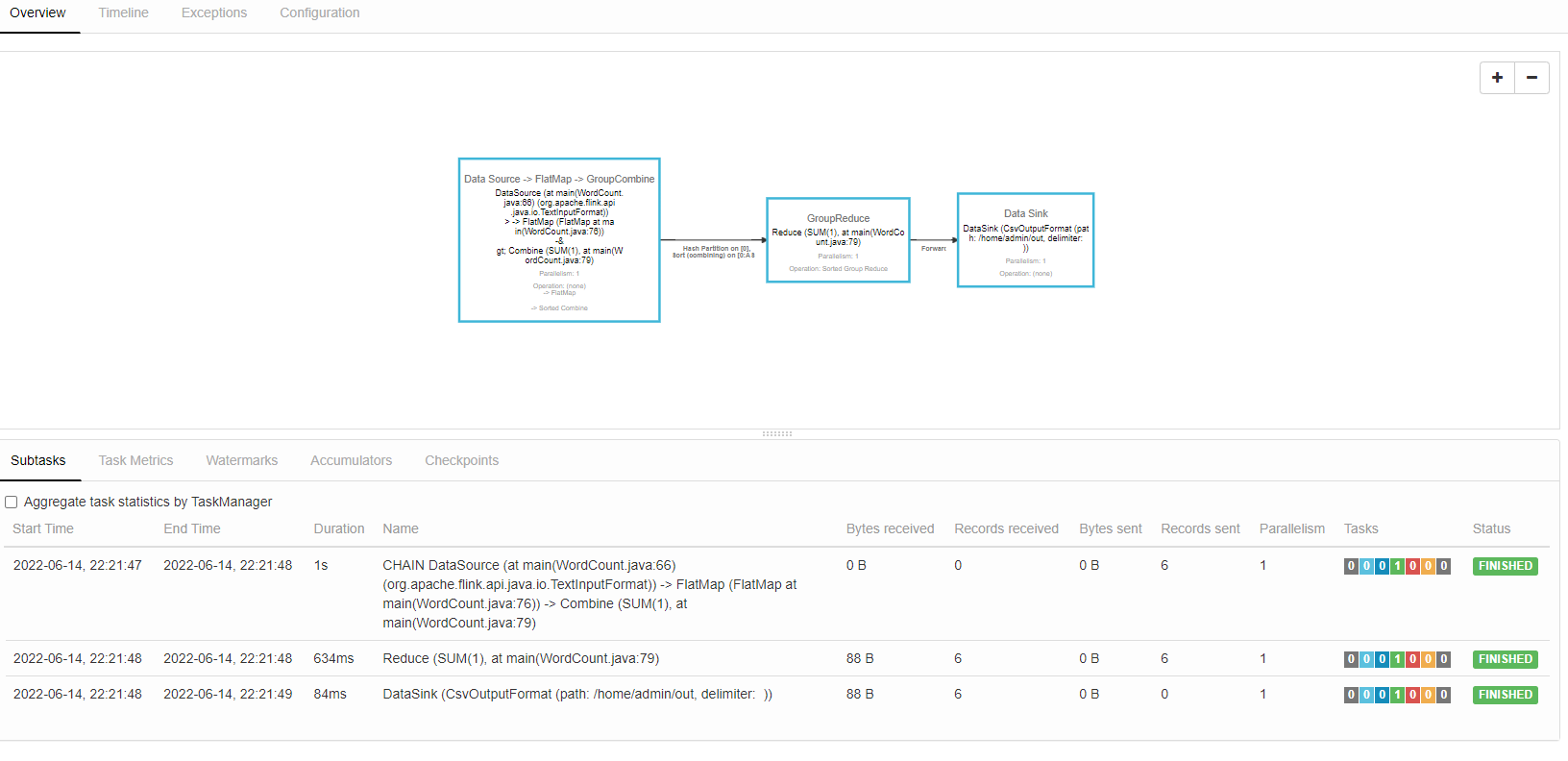

输出文件展示
[root@node01 flinkhadoop1.7.2]# cat /home/admin/out flink 1 hello 6 java 1 storm 1 stream 2 world 1
停止集群:
bin/stop-cluster.sh

jobmanager.rpc.address: node01
jobmanager.rpc.port: 6123
jobmanager.heap.size: 1024
taskmanager.heap.size: 1024
taskmanager.numberOfTaskSlots: 2
taskmanager.memory.preallocate: false
parallelism.default: 1
jobmanager.web.port: 8081
taskmanager.tmp.dirs: /home/user/apps/flink/tmp
#页面提交
web.submit.enable: true
[root@node01 flinkhadoop1.7.2]# vim conf/masters 192.168.36.138:8081
[root@node01 flinkhadoop1.7.2]# vim conf/slaves 192.168.36.138 192.168.36.139 192.168.36.140
hadoop下载
https://archive.apache.org/dist/hadoop/core/hadoop-2.7.5/
hadoop集群部署:
保姆级Hadoop集群部署_程序员小王java的博客-优快云博客
单机部署hadoop:
单机部署hadoop2.7.3_程序员小王java的博客-优快云博客_hadoop2.7.3
hadoop访问:
http://node01:50070/dfshealth.html#tab-overview
/usr/soft/hadoop-2.7.3/sbin/stop-dfs.sh /usr/soft/hadoop-2.7.3/sbin/start-dfs.sh
hadoop创建文件: hdfs dfs -mkdir -p /word #1. 查看hdfs文件系统目录文件 hdfs dfs -ls /word #2.上传: hdfs dfs -put 本地文件目录 HDFS文件目录 hdfs dfs -put /usr/apps/word/words.txt /word #3.删除文件 hdfs dfs -rm -r HDFS文件路径 hdfs dfs -rm -r /word
 https://blog.youkuaiyun.com/weixin_44385486/article/details/124197370?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165552127416782388044840%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=165552127416782388044840&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-3-124197370-null-null.nonecase&utm_term=flink&spm=1018.2226.3001.4450
https://blog.youkuaiyun.com/weixin_44385486/article/details/124197370?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165552127416782388044840%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=165552127416782388044840&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-3-124197370-null-null.nonecase&utm_term=flink&spm=1018.2226.3001.4450集群搭建过程中,可能出现的问题:
- 端口被占用,我们需要手动杀掉占用端口的程序;
- 目录找不到或者文件找不到,我们在 flink-conf.yaml 中配置过 io.tmp.dirs ,这个目录需要手动创建
flink -hadoop高可用集群和yarn需要 对应的flink-hadoop依赖,下载地址
命令:
./bin/flink run -m yarn-cluster -yid application_xxxx ./examples/batch/WordCount.jar
yarn上运行任务./bin/flink run -yjm 1024m -ytm 4096m -ys 2 ./examples/batch/WordCount.jar
启动集群
bin/start-cluster.sh
停止集群
bin/stop-cluster.sh
附件FLink技术数据可以参考:



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











