




 文章讨论了GPU和TPU在硬件加速深度学习中的差异,强调了GPU的并行处理能力和专门的tensorcore。在软件方面,重点介绍了PyTorch的自动梯度计算、Module模块化设计以及动态图和静态图的概念。PyTorch的自动Grad功能简化了反向传播过程,而nn.Module和dataloader等功能则方便了网络构建和数据处理。此外,文章还提到了Tensorboard在训练过程中的可视化作用。
文章讨论了GPU和TPU在硬件加速深度学习中的差异,强调了GPU的并行处理能力和专门的tensorcore。在软件方面,重点介绍了PyTorch的自动梯度计算、Module模块化设计以及动态图和静态图的概念。PyTorch的自动Grad功能简化了反向传播过程,而nn.Module和dataloader等功能则方便了网络构建和数据处理。此外,文章还提到了Tensorboard在训练过程中的可视化作用。
1. 硬件
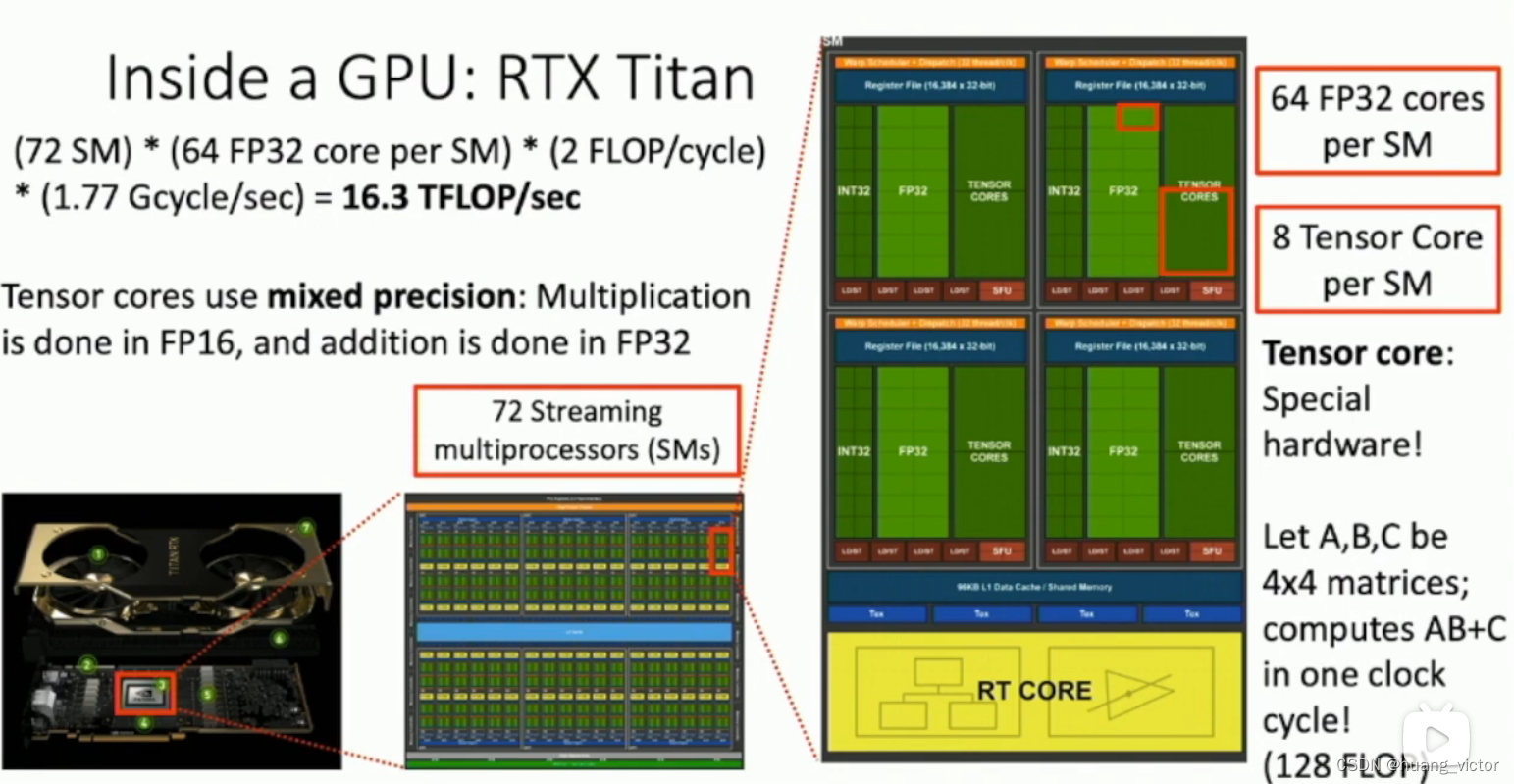
Nvidia GPU
Goolgle TPU
1. GPU,核心数量很多,单核相对较慢。CPU,核心数量少,单核很快很强。
2. GPU中有针对deep learning特殊设计的tensor core,可以进行大量的并行的矩阵运算
3. GPU的内存和带宽都影响训练的速度

2. 软件
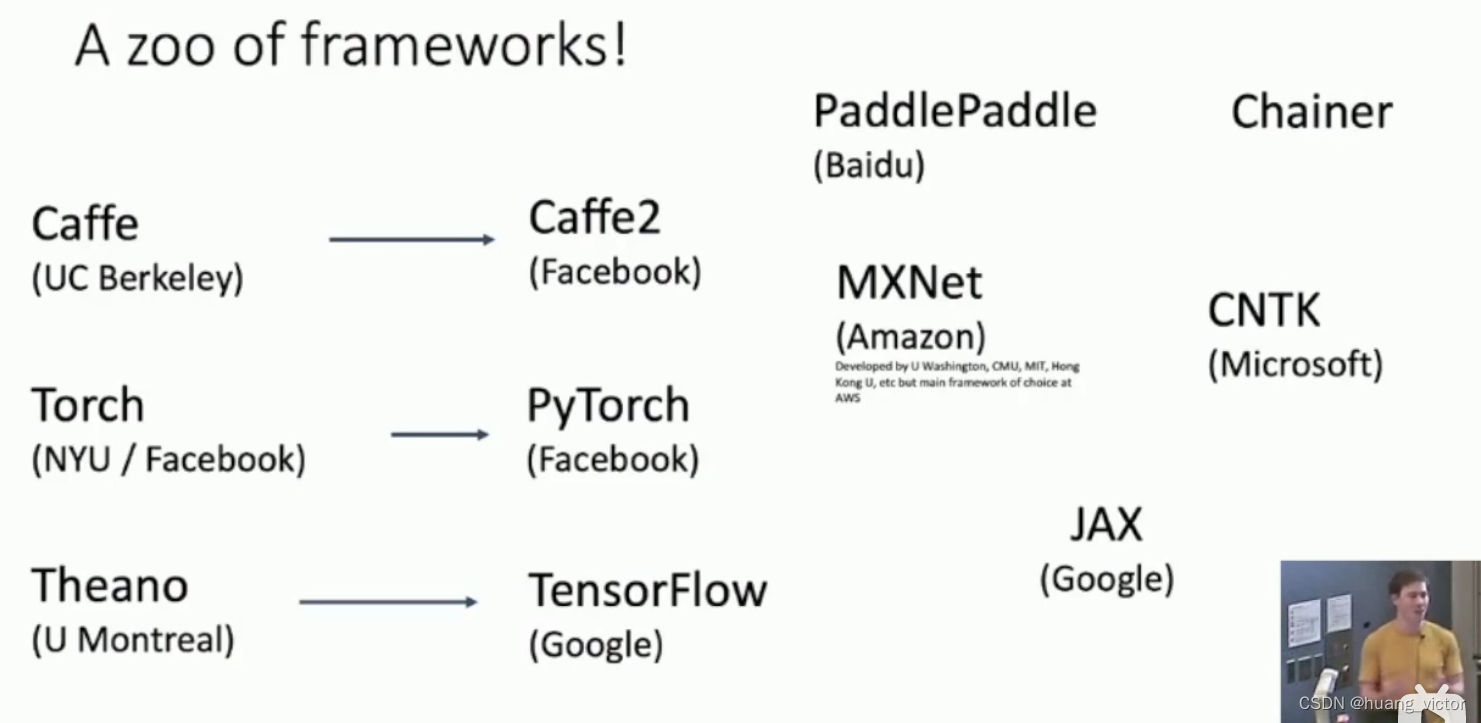
当年很多的框架,
3. Pytorch
网络结构,梯度计算,反向传播
Tensor, 类似于Numpy array,可以在gpu上进行运算的矩阵。
完全手动实现所有的,梯度计算,loss计算,梯度反向传播,权重更新。

AutoGrad,可以建立计算图,并自动的计算梯度,可以用于反向传播。

requires_grad=True # 选择这个flag,涉及到这个变量的计算就会自动计算梯度
with torch.no_grad(): # 一般用在反向梯度传播,不需要计算梯度
backprop
xxx.grad.zero_() # 要清零
可以自定义函数,并自定义梯度的计算,这样pytorch在使用这个函数的时候,整个函数就变成一个单独的节点,而不是拆散变为基本的计算单元。

Module,可以模块化设计的网络结构,可以保存weight和状态。
torch.nn,定义网络结构,定义loss,定义optimizer,high level的api,大部分常用的网络结构都可以这么操作。
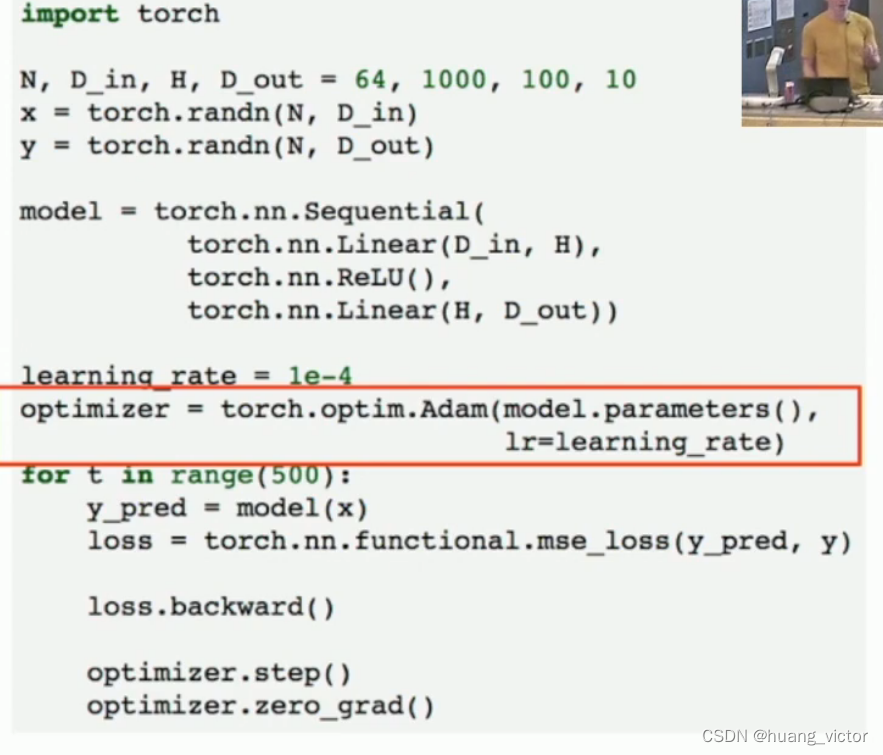
利用了nn.Sequential(),nn.functional.mse_loss(),手写梯度更新

利用了nn.Sequential(), nn.functional.mse_loss(),torch.optim.Adam():调用adam optimizer,不用手动更新
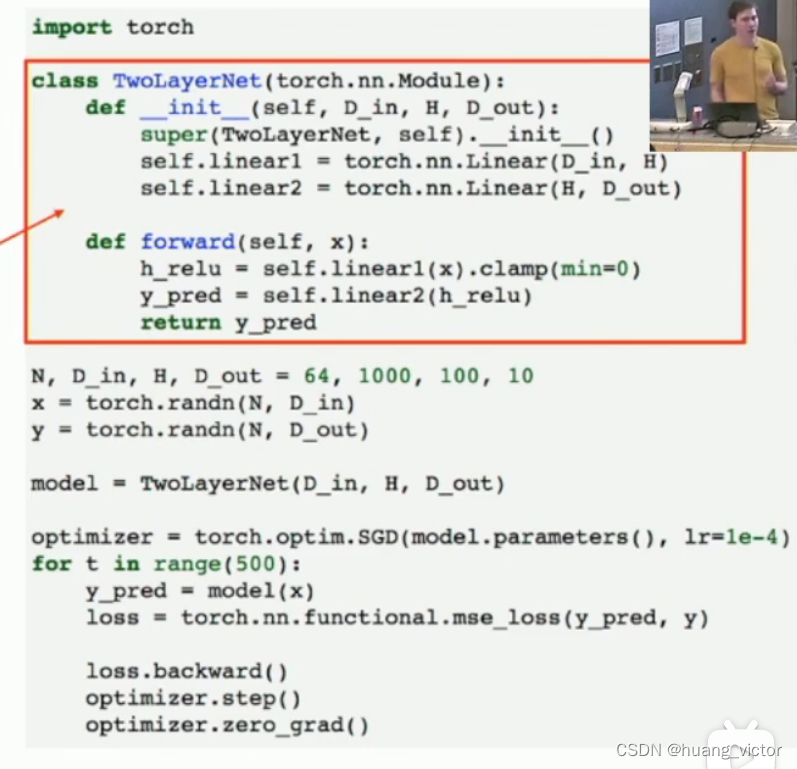
继承nn.module,
__init__定义网络结构,
forward(),定义前向传播,
训练迭代:前向传播,计算loss,loss梯度计算,调用optimizer,更新weights,循环。
定义一些block,然后直接用block建立完整的网络
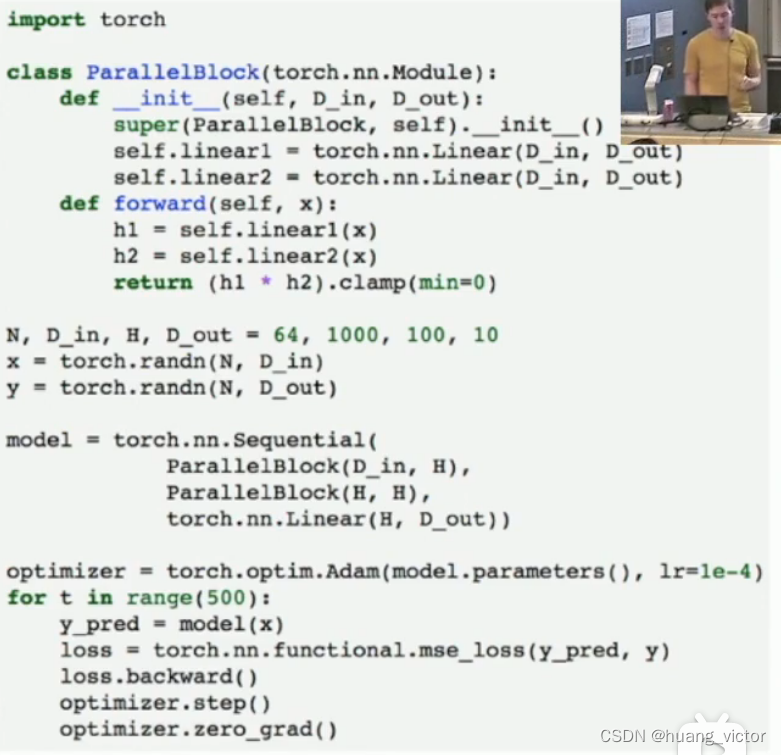
数据输入,
dataloader
静态图,动态图,
1. pytorch 默认是动态图,每一次前向传播,建立动态图,反向传播之后,扔掉计算图并重新建立。更灵活,更适合尝试一些idea,但是计算资源会被浪费。
2. 可以支持静态图,jit, just in time
graph = torch.jit.script(model),动态图转化为静态图
或者通过修饰器的方法来实现。
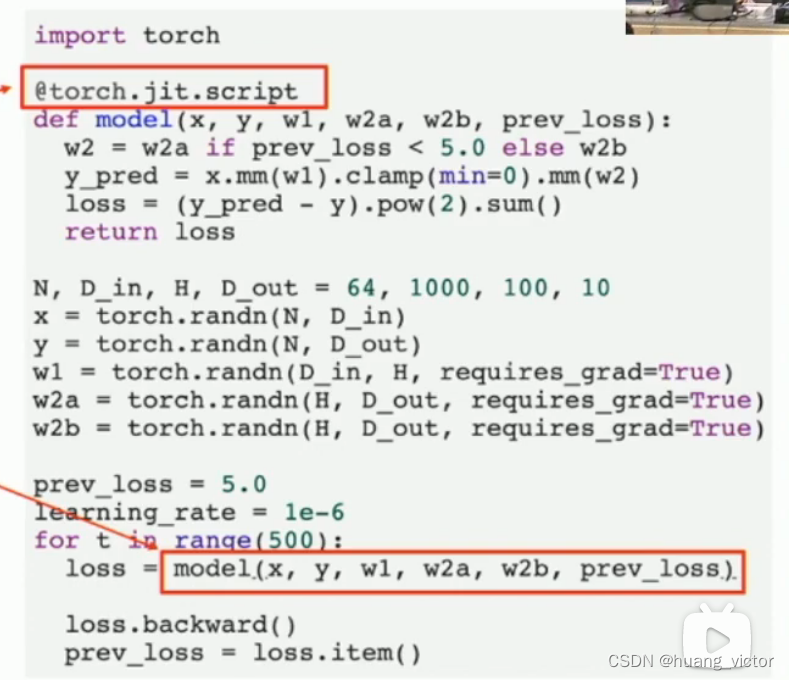
3. 静态图更适合C++部署
4. 动态图方便调试
Tensorboard,
loss, learning rate等训练过程数据的logging和可视化


















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









