




课件相关内容:http://cs231n.stanford.edu/2017/syllabus.html
文章目录
概述
人工智能是在数据的基础上所实现的,数据在一定程度上与模型的性能成正相关(过拟合之前),然而数据越多,也必然有随之产生的挑战:1. 模型尺寸变大,计算量过大,造成延迟、高能耗,不便于移动设备的无线传输;2. 训练速度提高一倍,准确率反而不会有过多的提高;3. 能量(电能等)的损耗,产热过高。如下所示



cs231n 15讲通过以下的四象限,讲述了算法和硬件在模型推断(前向传播)和训练(反向传播)上有效加快深度学习的方法。(硬件方面简单略过)
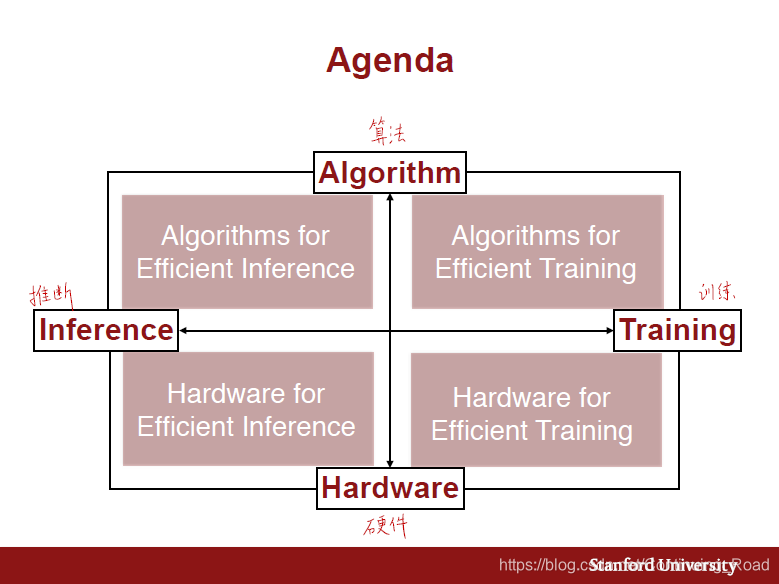
高效推断的算法
1. 修剪树枝

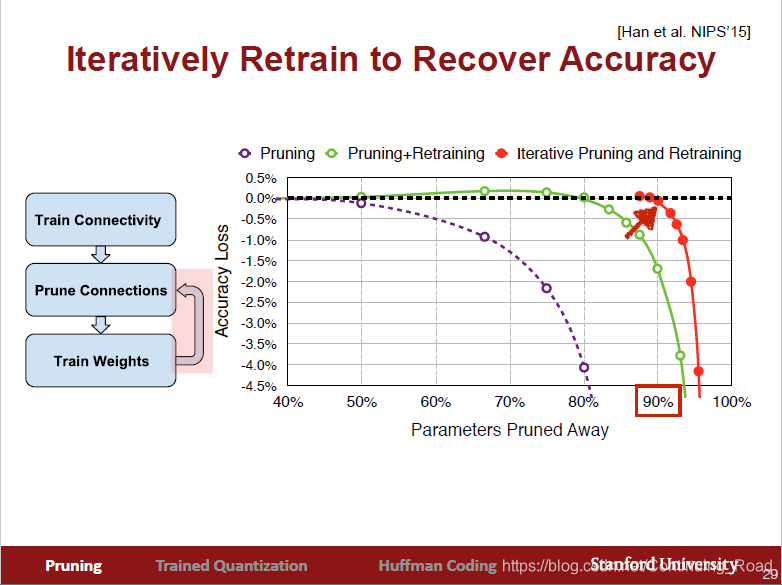
剪掉大部分的神经元和突触,留下权重最大的那部分,进而以修剪后的模型作为基模型重新推断,再进行修剪、推断,得到一个更轻量但性能不减的模型
2. 权重合并
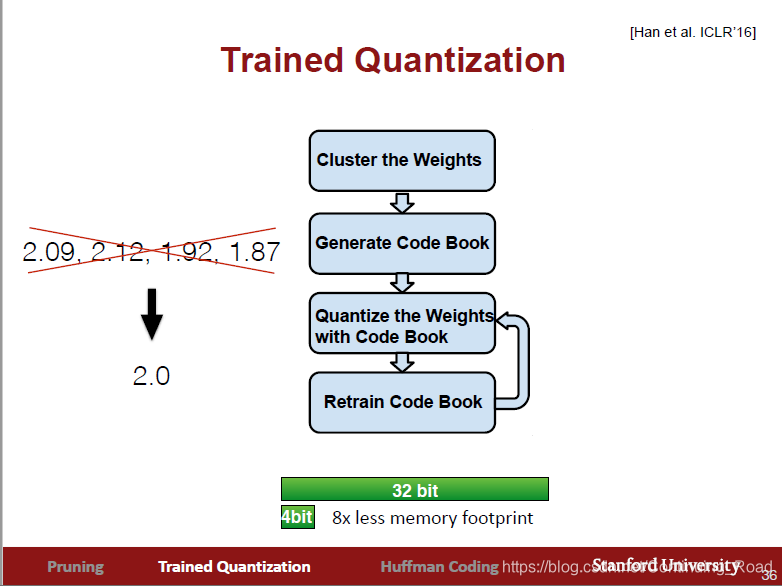
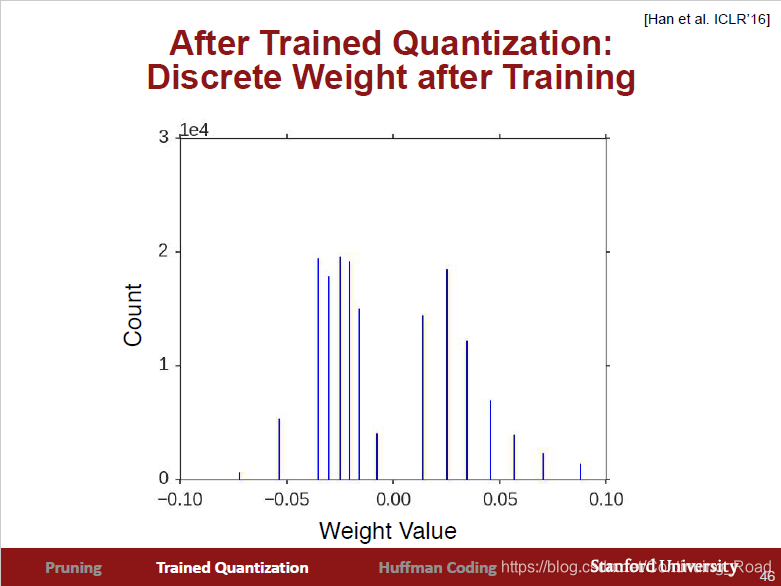
通过将权重里一些接近的值合并为一个值,使权重值离散化,减少权重值的个数,进而可以用更小的比特表示权重。如上所示,通过权重合并能将权重值个数从32位变为4位,整整减小至原来的1/8。
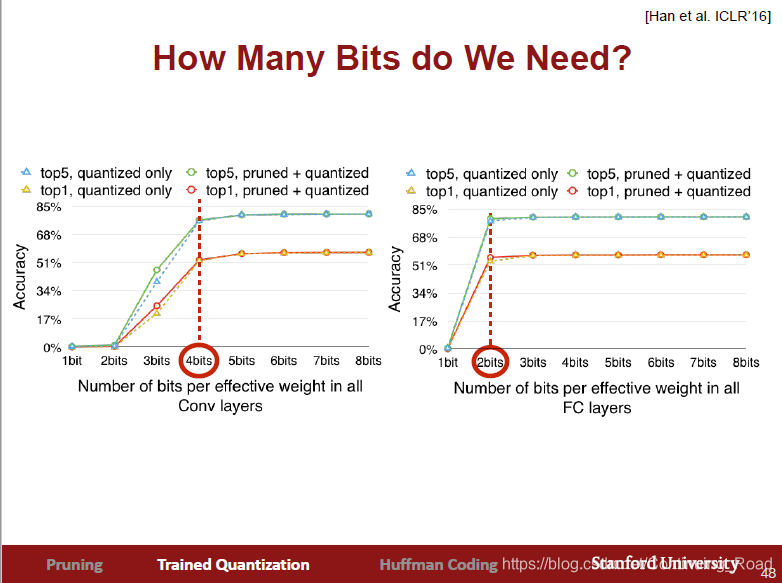
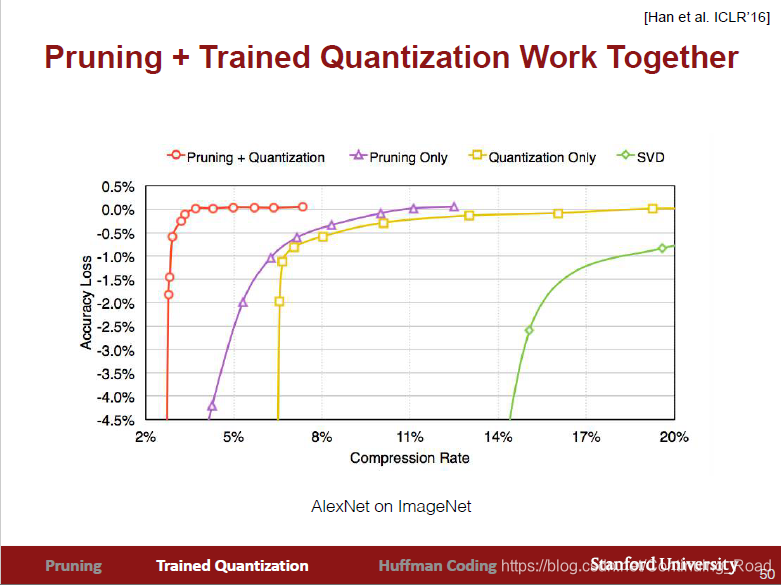
根据经验所示,权重值合并后个数在卷积层和全连接层分别到4位和2位是一个不错的选择,同时修剪树枝和权重合并方法在模型压缩率效果可从下图看出,两者综合使用效果最佳。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









