









最近在训练GANs的时候遇到挺多问题,想系统的看一下GANs发展进程中遇到的问题和解决方案,顺便总结一下。
(严重参考:https://blog.youkuaiyun.com/a312863063/article/list/3)
https://www.cnblogs.com/Allen-rg/p/10305125.html
GAN
理论基础
1. 生成模型和判别模型
https://blog.youkuaiyun.com/zouxy09/article/details/8195017
监督学习可以分为生成方法和判别方法,所学到的模型称为生成模型和判别模型。
生成模型:由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,P(Y|X)= P(X,Y)/ P(X)
判别模型:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)
2. GAN基本思想
生成对抗网络包含两个模型,一个生成模型和一个判别模型。判别模型用于判断一个给定的图片是否为真实图片,生成模型是去生成一个看上去像真实图片的图片。
两个模型进行对抗训练,生成模型生成一张图片去使判别模型认为这张图片为真实图片,判别模型尽力去将生成模型生成的图片判断为假图片(生成得到的图片)。两个模型交替训练,希望最终两个模型的能力都很强,达到稳定状态。
min
G
max
D
V
(
D
,
G
)
=
E
x
∼
p
data
(
x
)
[
log
D
(
x
)
]
+
E
z
∼
p
z
(
z
)
[
log
(
1
−
D
(
G
(
z
)
)
)
]
\min _{G} \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))]
GminDmaxV(D,G)=Ex∼pdata (x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
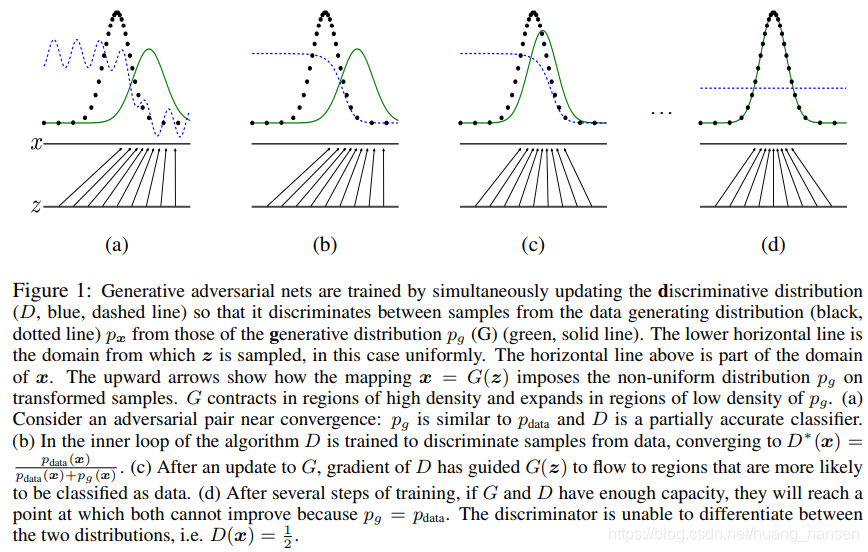
蓝色线表示判别分布,绿色为生成分布,黑色为真实数据分布。从左到右为不断迭代,图d表示,当生成分布和真实分布重叠时,判别器无法分辨两个分布。

伪代码中,每迭代k次判别器,迭代一次生成器(在我的实验中,效果相反,判别器迭代一次,生成器需迭代很多次才能使判别器不过快达到完美,遗留问题)
存在问题
JS-divergence
J
S
(
P
r
,
P
g
)
=
K
L
(
P
r
∥
P
m
)
+
K
L
(
P
g
∥
P
m
)
J S\left(\mathbb{P}_{r}, \mathbb{P}_{g}\right)=K L\left(\mathbb{P}_{r} \| \mathbb{P}_{m}\right)+K L\left(\mathbb{P}_{g} \| \mathbb{P}_{m}\right)
JS(Pr,Pg)=KL(Pr∥Pm)+KL(Pg∥Pm)
香农信息量表示随机变量X=x时,消除信息不确定性所需要的信息量,p是一件事情发生的概率,p越大,不确定性越小:
−
log
p
(
x
)
=
log
1
p
(
x
)
-\log p(x)=\log \frac{1}{p(x)}
−logp(x)=logp(x)1
信息熵则表示随机变量的总体香农信息量,即香农信息量的期望,用于刻画消除不确定性所需的信息量,信息熵可以看做对X进行编码所需的编码长度的期望值:
H ( X ) = − ∑ x ∈ X p ( x ) log p ( x ) H(X)=-\sum_{x \in \mathcal{X}} p(x) \log p(x) H(X)=−x∈X∑p(x)logp(x)
信息熵指在真实分布p中,所需的编码长度的期望H( p):
∑
i
p
(
i
)
log
1
p
(
i
)
\sum_{i} p(i) \log \frac{1}{p(i)}
i∑p(i)logp(i)1
而交叉熵指,在非真实分布p中所需的编码长度的期望H(p,q):
∑
i
p
(
i
)
log
1
q
(
i
)
\sum_{i} p(i) \log \frac{1}{q(i)}
i∑p(i)logq(i)1
交叉熵和信息熵的概念,可以引出相对熵也叫KL散度:
K
L
=
H
(
p
,
q
)
−
H
(
p
)
\mathrm{KL}=\mathrm{H}(\mathrm{p}, \mathrm{q})-\mathrm{H}(\mathrm{p})
KL=H(p,q)−H(p)
∑
i
p
(
i
)
∗
log
p
(
i
)
q
(
i
)
\sum_{i} p(i) * \log \frac{p(i)}{q(i)}
i∑p(i)∗logq(i)p(i)
用于衡量两个分布的差异,差异越大,相对熵越大
在机器学习中,由于真实分布是固定的,因此H(p,q)交叉熵越大时,相对熵就越大,因此交叉熵可以用来做损失函数。
KL散度是不对称的,不能表示距离而JS散度是对称的,可以用于表示两分布之间的差异,用于生成对抗网络的公式推导。
https://zhuanlan.zhihu.com/p/49827134
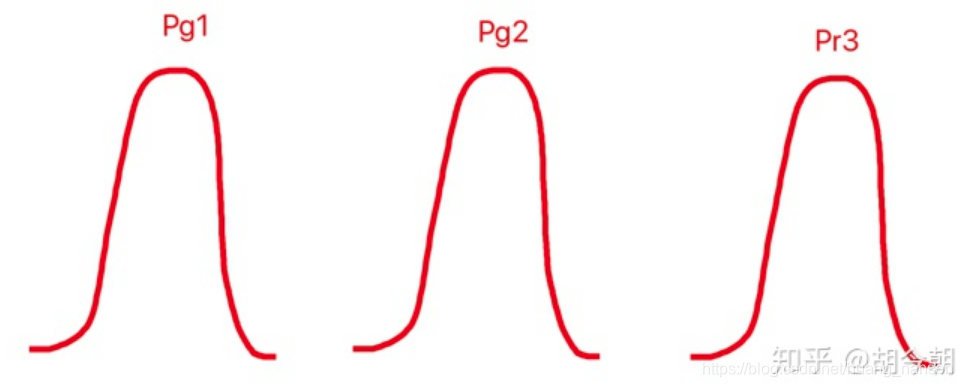
但是JS散度也存在缺陷:
如上图所示,JS(Pg1||Pg2)==JS(Pg1||Pg3),但实际上Pg1和Pg2之间的距离应该要小于Pg1和Pg3的距离。
在原始GAN中提出两种损失函数:
第一种损失函数:
−
E
x
∼
P
r
[
log
D
(
x
)
]
−
E
x
∼
P
g
[
log
(
1
−
D
(
x
)
)
]
-\mathbb{E}_{x \sim P_{r}}[\log D(x)]-\mathbb{E}_{x \sim P_{g}}[\log (1-D(x))]
−Ex∼Pr[logD(x)]−Ex∼Pg[log(1−D(x))]
第二种损失函数:
将生成器损失改为:
E
x
∼
P
g
[
−
log
D
(
x
)
]
\mathbb{E}_{x \sim P_{g}}[-\log D(x)]
Ex∼Pg[−logD(x)]
在第一种损失函数中,当判别器在越接近完美状态(完美判断是生成图或真实图)时,最小化生成器的loss近似等价于最小化JS(real||predict)。而当两个分布不重叠时,JS永远是-log2,所以梯度为0,生成器将面临梯度消失的问题。
在第二种损失函数中,最小化生成器的损失,等价于最小化一个不合理的距离衡量:
K
L
(
P
g
∥
P
r
)
−
2
J
S
(
P
r
∥
P
g
)
K L\left(P_{g} \| P_{r}\right)-2 J S\left(P_{r} \| P_{g}\right)
KL(Pg∥Pr)−2JS(Pr∥Pg)
既要最小化KL也要最大化JS,导致梯度不稳定,引起训练不稳定(training instability)问题。
在KL散度项的问题还有:
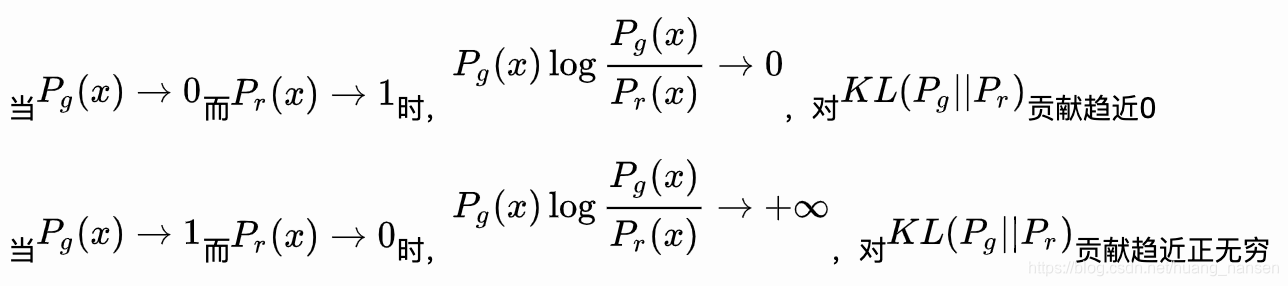
两者梯度不同,生成器趋向于生成安全的样本,缺乏多样性,导致模式坍塌(mode collapse)问题。
WGAN
原始GAN使用JS divergence:
J
S
(
P
r
,
P
g
)
=
K
L
(
P
r
∥
P
m
)
+
K
L
(
P
g
∥
P
m
)
J S\left(\mathbb{P}_{r}, \mathbb{P}_{g}\right)=K L\left(\mathbb{P}_{r} \| \mathbb{P}_{m}\right)+K L\left(\mathbb{P}_{g} \| \mathbb{P}_{m}\right)
JS(Pr,Pg)=KL(Pr∥Pm)+KL(Pg∥Pm)
WGAN引入EM距离或称为Wasserstein-1:
W
(
P
r
,
P
g
)
=
inf
γ
∈
Π
(
P
r
,
P
g
)
E
(
x
,
y
)
∼
γ
[
∥
x
−
y
∥
]
W\left(\mathbb{P}_{r}, \mathbb{P}_{g}\right)=\inf _{\gamma \in \Pi\left(\mathbb{P}_{r}, \mathbb{P}_{g}\right)} \mathbb{E}_{(x, y) \sim \gamma}[\|x-y\|]
W(Pr,Pg)=γ∈Π(Pr,Pg)infE(x,y)∼γ[∥x−y∥]
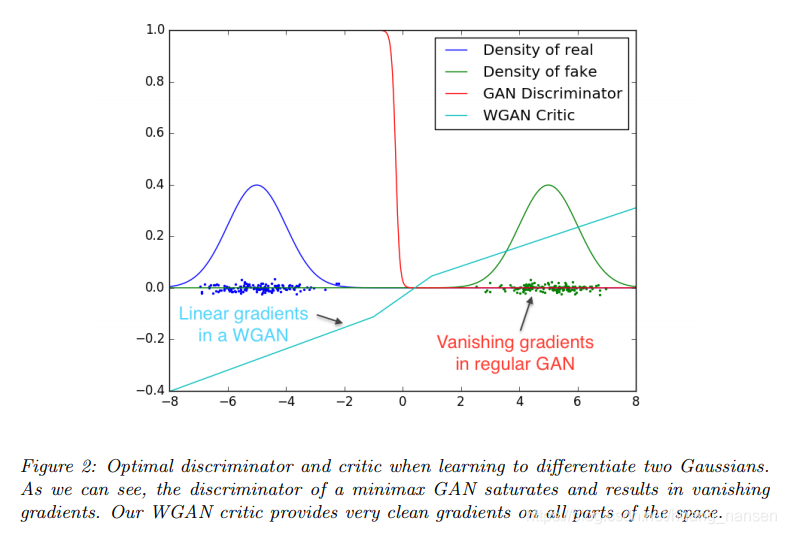
Wasserstein距离相对于JS散度和KL散度的优势在于,即便两个分布不存在重叠时,也能表示两个分布之间的远近。
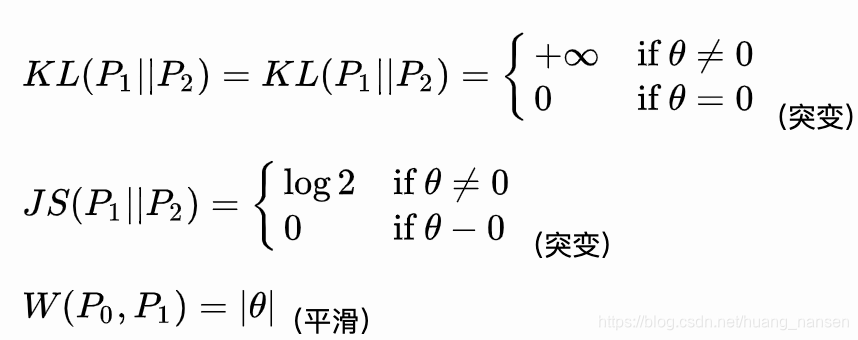
KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的。
WGAN将GAN的损失函数修改为:

为满足Lipschitz连续条件(保证模型对输入扰动不敏感,提高繁华性能),WGAN采用weight clipping的方式,每更新一次判别器的参数后,对参数进行clip,保证判别器对两个略微不同的样本的判别上不会有很大的差异。
具体操作为:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
同时,Wasserstein距离也可以作为一个可靠的训练进程指标,与生成样本的质量高度相关。
https://zhuanlan.zhihu.com/p/25071913
WGAN-GP
由于WGAN使用weight-clipping(-0.01, 0.01)去实现Lipschitz限制,判别器希望尽可能拉大真实样本和生成样本的距离,因此判别器的参数集中在最大最小值,容易引起梯度爆炸或梯度消失。
L
=
E
x
~
∼
P
g
[
D
(
x
~
)
]
−
E
x
∼
P
r
[
D
(
x
)
]
+
λ
E
x
∼
P
α
[
(
∥
∇
x
^
D
(
x
^
)
∥
2
−
1
)
2
]
L=\underset{\tilde{\boldsymbol{x}} \sim \mathbb{P}_{g}}{\mathbb{E}}[D(\tilde{\boldsymbol{x}})]-\underset{\boldsymbol{x} \sim \mathbb{P}_{r}}{\mathbb{E}}[D(\boldsymbol{x})]+\lambda \underset{\boldsymbol{x} \sim \mathbb{P}_{\boldsymbol{\alpha}}}{\mathbb{E}}\left[\left(\left\|\nabla_{\hat{\boldsymbol{x}}} D(\hat{\boldsymbol{x}})\right\|_{2}-1\right)^{2}\right]
L=x~∼PgE[D(x~)]−x∼PrE[D(x)]+λx∼PαE[(∥∇x^D(x^)∥2−1)2]
前半部分为原始的损失函数,即计算推土距离,后一半为新增的正则限制。
WGAN-GP提出,添加gradient penalty,使判别器参数尽可能的小,达到Lipschitz条件。
x
~
←
G
θ
(
z
)
x
^
←
ϵ
x
+
(
1
−
ϵ
)
x
~
\begin{array}{l} \tilde{\boldsymbol{x}} \leftarrow G_{\theta}(z) \\ \hat{\boldsymbol{x}} \leftarrow \epsilon \boldsymbol{x}+(1-\epsilon) \tilde{\boldsymbol{x}} \end{array}
x~←Gθ(z)x^←ϵx+(1−ϵ)x~
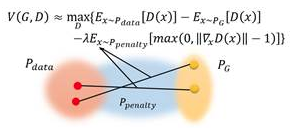
在伪代码中有这么两句,解释如下:
data和G(z)共同组成了一个很大的高纬空间x,我们要做的事情是f(x,w)在这个x的条件下找到一组最优的w使得f(x,w)完成特定的任务,当我们给w加惩罚的时候应该加在所有的x对应w上,所以我们就在x和x^ (即上图中Pdata和PG)的中间值上取一个来代表全体的x和x,在x上的w加惩罚。
https://zhuanlan.zhihu.com/p/50168473
LSGAN
Least Squares Generative Adversarial Networks
min
D
V
L
S
G
A
N
(
D
)
=
1
2
E
x
∼
p
d
a
t
a
(
x
)
[
(
D
(
x
)
−
b
)
2
]
+
1
2
E
z
∼
p
z
(
z
)
[
(
D
(
G
(
z
)
)
−
a
)
2
]
min
G
V
L
S
G
A
N
(
G
)
=
1
2
E
z
∼
p
z
(
z
)
[
(
D
(
G
(
z
)
)
−
c
)
2
]
\begin{array}{l} \min _{D} V_{\mathrm{LSGAN}}(D)=\frac{1}{2} \mathbb{E}_{\boldsymbol{x} \sim p_{\mathrm{data}}(\boldsymbol{x})}\left[(D(\boldsymbol{x})-b)^{2}\right]+\frac{1}{2} \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}\left[(D(G(\boldsymbol{z}))-a)^{2}\right] \\ \min _{G} V_{\mathrm{LSGAN}}(G)=\frac{1}{2} \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}\left[(D(G(\boldsymbol{z}))-c)^{2}\right] \end{array}
minDVLSGAN(D)=21Ex∼pdata(x)[(D(x)−b)2]+21Ez∼pz(z)[(D(G(z))−a)2]minGVLSGAN(G)=21Ez∼pz(z)[(D(G(z))−c)2]
也是用于JS散度无法拉近真实分布和生成分布的问题,使用最小二乘法作为损失函数。默认a=0,b=1, c=1
BEGAN
Boundary Equilibrium GANs
https://zhuanlan.zhihu.com/p/26394806
与传统GANs相比,BEGAN的优化目标不同了。传统GAN希望让生成图像分布逼近真实图像分布,BEGAN目标是让生成图像的重构误差趋近于真实图像的重构误差,这是因为作者发现,每个像素的重构误差都是独立同分布的,也近似正态分布,根据中心极限定理,图像的重构误差也近似服从正态分布。
根据GAN对抗性的原则,D的目标是拉大两个分布的距离,也就是最大化[公式],而G的目标则是拉进两个分布的距离。
根据WGAN的启发,BEGAN优化如下距离,D拉大W距离,G缩小W距离:
W
(
μ
1
,
μ
2
)
2
=
(
m
1
−
m
2
)
2
+
(
c
1
+
c
2
−
2
c
1
c
2
)
W\left(\mu_{1}, \mu_{2}\right)^{2}=\left(m_{1}-m_{2}\right)^{2}+\left(c_{1}+c_{2}-2 \sqrt{c_{1} c_{2}}\right)
W(μ1,μ2)2=(m1−m2)2+(c1+c2−2c1c2)
W
(
μ
1
,
μ
2
)
∝
∣
m
1
−
m
2
∣
W\left(\mu_{1}, \mu_{2}\right) \propto\left|m_{1}-m_{2}\right|
W(μ1,μ2)∝∣m1−m2∣
由上式可以看出,BEGAN的目标是最小化下面两式:
L
D
=
L
(
x
,
θ
D
)
−
L
(
G
(
z
,
θ
G
)
,
θ
D
)
\mathcal{L}_{D}=\quad \mathcal{L}\left(x, \theta_{D}\right)-\mathcal{L}\left(G\left(z, \theta_{G}\right), \theta_{D}\right)
LD=L(x,θD)−L(G(z,θG),θD)
L
G
=
L
(
G
(
z
,
θ
G
)
,
θ
D
)
\mathcal{L}_{G}=\quad \mathcal{L}\left(G\left(z, \theta_{G}\right), \theta_{D}\right)
LG=L(G(z,θG),θD)
同时,作者提出了一个收敛指标:
M
=
L
(
x
)
+
∣
γ
L
(
x
)
−
L
(
G
(
z
)
)
\mathcal{M}=\mathcal{L}(x)+\mid \gamma \mathcal{L}(x)-\mathcal{L}(G(z))
M=L(x)+∣γL(x)−L(G(z))
在满足上面LD和LG的同时,尽量保证:
γ
=
E
z
(
L
(
G
(
z
)
)
)
E
x
(
L
(
x
)
)
\gamma=\frac{\mathbb{E}_{z}(\mathcal{L}(G(z)))}{\mathbb{E}_{x}(\mathcal{L}(x))}
γ=Ex(L(x))Ez(L(G(z)))
用于平衡D和G的能力,当[公式]较小时,D致力于最小化真实样本的重构误差,相对来说,而对生成样本的关注较少,这将导致生成样本的多样性降低。作者称这个超参数为diversity ratio,它控制生成样本的多样性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









