







数据竞赛-“达观杯”文本智能处理-Day1
1.竞赛简介
大赛链接点击 此处
a) 任务
建立模型通过长文本数据正文(article),预测文本对应的类别(class)
b) 数据
链接: https://pan.baidu.com/s/11AOOn0xlv0TZjGeFfRc3Rw 提取码: 58r9
数据包含2个csv文件:
- train_set.csv:
此数据集用于训练模型,每一行对应一篇文章。文章分别在“字”和“词”的级别上做了脱敏处理。共有四列:
第一列是文章的索引(id),第二列是文章正文在“字”级别上的表示,即字符相隔正文(article);第三列是在“词”级别上的表示,即词语相隔正文(word_seg);第四列是这篇文章的标注(class)。
注:每一个数字对应一个“字”,或“词”,或“标点符号”。“字”的编号与“词”的编号是独立的! - test_set.csv:
此数据用于测试。数据格式同train_set.csv,但不包含class。
注:test_set与train_test中文章id的编号是独立的。
c) 评分标准
评分算法
binary-classification
采用各个品类F1指标的算术平均值,它是Precision 和 Recall 的调和平均数。
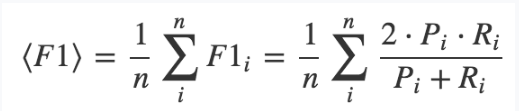
其中,Pi是表示第i个种类对应的Precision, Ri是表示第i个种类对应Recall。
AB榜的划分方式和比例:
【1】评分采用AB榜形式,提交文件必须包含测试集中所有用户的预测值。排行榜显示A榜成绩,竞赛结束后2小时切换成B榜单。B榜成绩以选定的两次提交或者默认的最后两次提交的最高分为准,最终比赛成绩以B榜单为准。
【2】此题目的AB榜是随机划分,A榜数据占50%,B榜使用全量测试集,即占100%。
2.读取数据,观察数据
import pandas as pd
file_path = 'new_data/train_set.csv'
df_train = pd.read_csv(file_path)
print(df_train.head())
数据文件new_data和py文件位于同一目录
运行结果:

3.训练集数据划分
import pandas as pd
from sklearn.model_selection import train_test_split
file_path = 'new_data/train_set.csv'
df_train = pd.read_csv(file_path)
print(df_train.head())
x = df_train.drop(['id','class'], axis=1)
y = df_train['class']
x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.1, random_state=1)
print('x_train info')
print(x_train.info())
print('------------------------')
print('x_valid info')
print(x_valid.info())
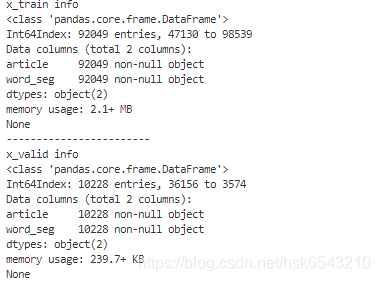
运行结果:
4.对数据以及赛题的理解和发现
待补充


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









