







 超级会员免费看
超级会员免费看
目录
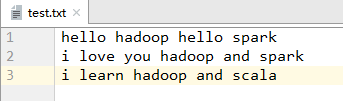
1、文本文件test.txt
2、登录hadoop虚拟机
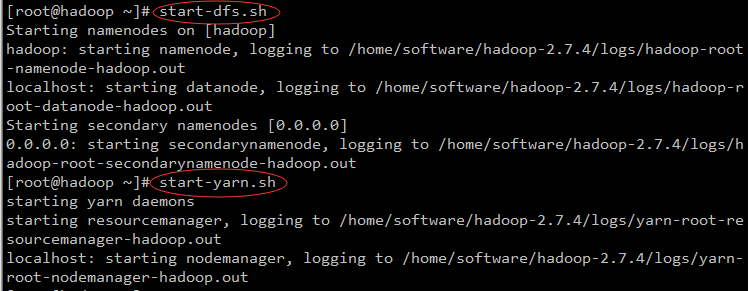
3、启动hadoop
[root@hadoop ~]# start-dfs.sh
[root@hadoop ~]# start-yarn.sh
 本博客通过一个实际案例展示了如何在Hadoop环境中使用Hive进行词频统计。首先,介绍了准备文本文件test.txt,然后登录并启动Hadoop集群,接着将文件上传到HDFS的word目录。随后启动Hive服务,并为/word目录下的文件创建外部表test。最后,详细讲解了如何执行SQL查询来统计每个单词的出现次数。
本博客通过一个实际案例展示了如何在Hadoop环境中使用Hive进行词频统计。首先,介绍了准备文本文件test.txt,然后登录并启动Hadoop集群,接着将文件上传到HDFS的word目录。随后启动Hive服务,并为/word目录下的文件创建外部表test。最后,详细讲解了如何执行SQL查询来统计每个单词的出现次数。
目录

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文



















 4470
4470







