




1. 实战概述
- 本次实战利用 PySpark 读取 HDFS 上的网站访问日志 CSV 文件,通过 Spark SQL 提取日期字段中的年月信息,按
yyyy-M格式分组统计每月访问量,并按访问量降序排序输出结果,完整实现了网站月度流量分析任务。
2. 实战步骤
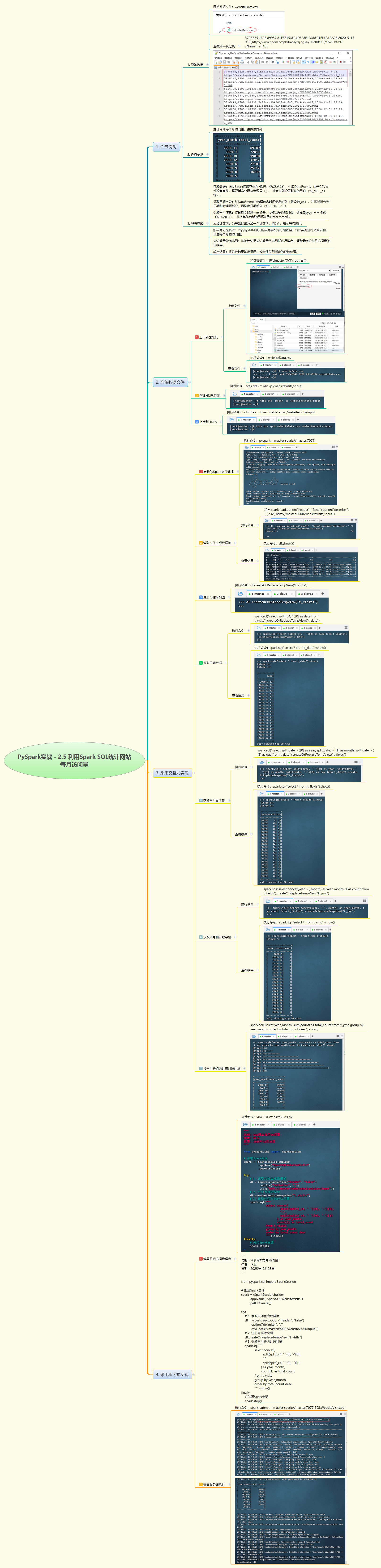
3. 实战总结
- 本次实战基于 Spark SQL 完成了网站每月访问量的统计分析。首先将原始日志文件上传至 HDFS,使用 PySpark 读取无表头 CSV 数据生成 DataFrame;接着通过嵌套
split()函数从时间字段_c4中提取年份和月份,并拼接为统一格式;随后直接使用count(1)聚合函数按年月分组统计访问次数,避免了中间视图的冗余操作;最终按访问量降序展示结果。整个过程体现了 Spark 分布式计算在日志分析中的高效性与简洁性,同时验证了 Spark SQL 在结构化数据处理中的强大能力。代码结构清晰、可扩展性强,适用于大规模 Web 日志的周期性分析场景。


















 1362
1362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











