




1. 实战概述
- 本次实战基于 Spark SQL 对 HDFS 上的文本文件进行词频统计,通过 DataFrame API 读取数据、使用
split与explode函数拆分单词,并结合临时视图与 SQL 语句完成分组计数与排序,最终将结果以 CSV 格式写回 HDFS,完整展示了 PySpark 中结构化数据处理的典型流程。
2. 实战步骤
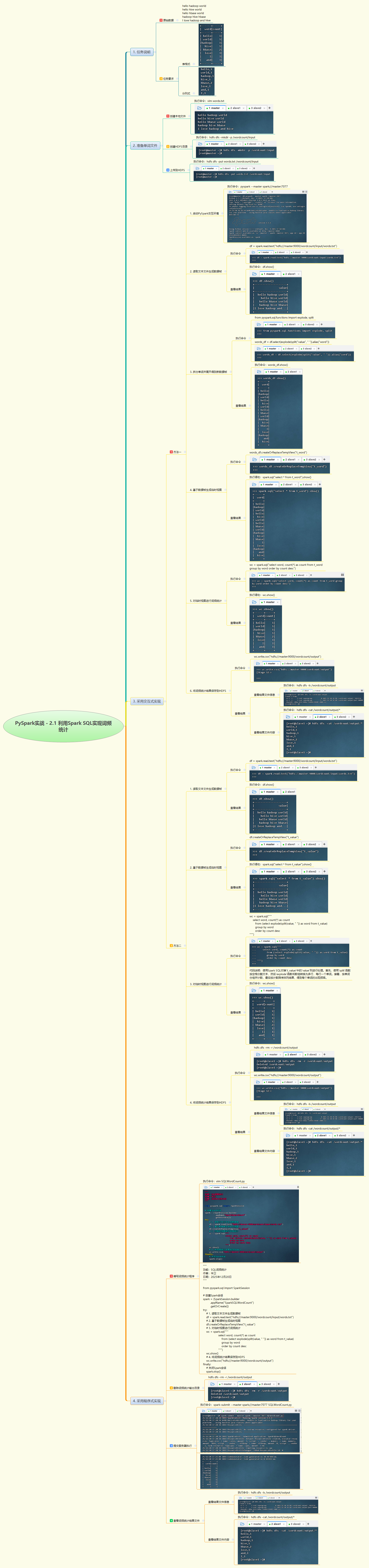
3. 实战总结
- 本次实战通过交互式与程序式两种方式,成功实现了基于 Spark SQL 的词频统计任务。利用
spark.read.text()读取原始日志,通过split和explode将每行文本展开为单词记录,再借助临时视图和标准 SQL 语法完成高效聚合与排序。程序采用SparkSession.builder(无括号)正确初始化会话,并在finally块中确保资源释放。整个过程体现了 Spark SQL 在简化大数据分析逻辑、提升开发效率方面的优势,同时验证了 PySpark 应用从本地调试到集群提交(spark-submit)的完整部署能力,为后续复杂数据处理任务奠定坚实基础。


















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











