




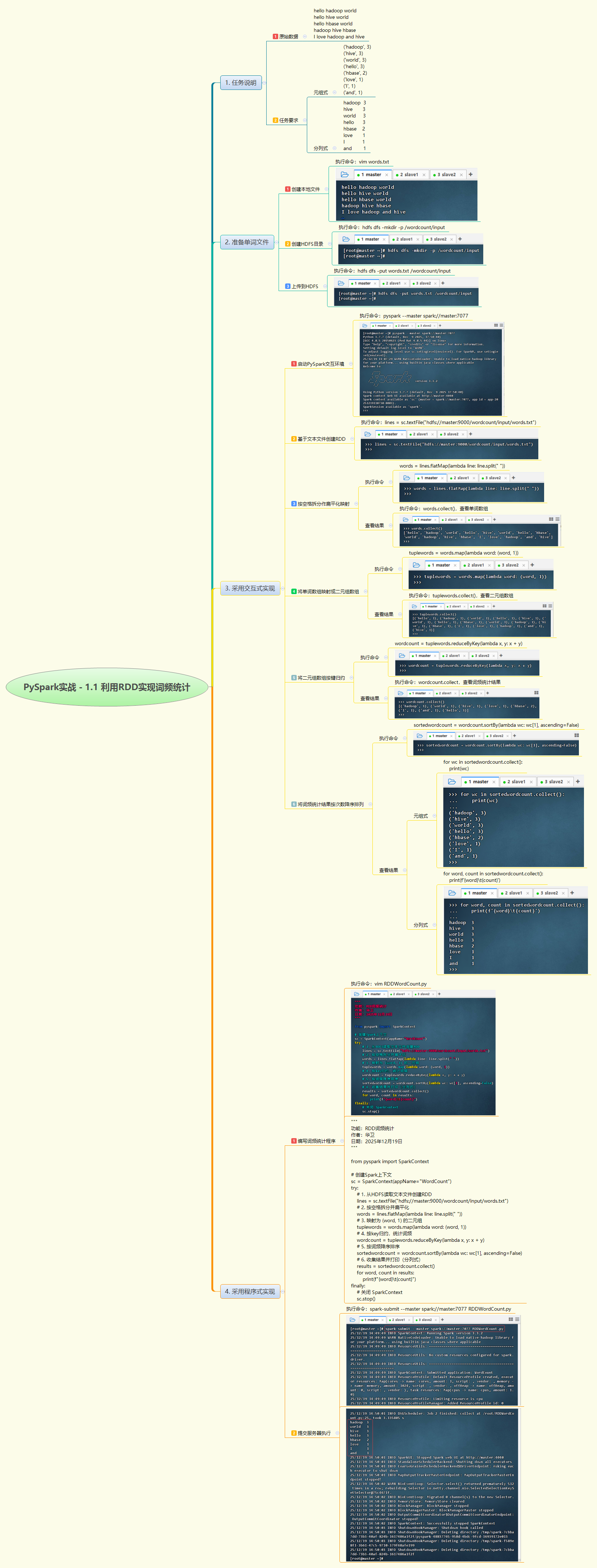
1. 实战概述
- 本次实战基于 PySpark 的 RDD 编程模型,实现分布式词频统计。通过读取 HDFS 上的文本文件,利用
flatMap拆分单词、map构建键值对、reduceByKey聚合计数,并按频次降序排序,最终以分列式输出结果,完整展示了 Spark 批处理作业的开发与执行流程。
2. 实战步骤
3. 实战总结
- 本次实战通过交互式与程序式两种方式,深入理解了 RDD 的核心转换操作(Transformation)与动作操作(Action)。从 HDFS 读取数据、拆分扁平化、构建键值对、归约聚合到排序输出,每一步都体现了函数式编程与分布式计算的思想。程序成功提交至 Spark Standalone 集群并正确输出词频结果,验证了代码逻辑与集群环境的协同工作能力。同时,日志显示任务在多个 Executor 上并行执行,体现了 Spark 的分布式处理优势。该实验为后续复杂数据处理任务奠定了坚实基础。


















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











