







 超级会员免费看
超级会员免费看
 本文详细介绍了如何构建Spark机器学习系统,包括启动Spark集群、加载数据和探索数据的过程。首先讲解了Spark运行模式和SparkShell的使用,然后演示了数据的下载、上传至HDFS以及转化为数据帧的操作,最后在数据探索部分展示了获取数据统计信息和进行数据质量分析的步骤。
本文详细介绍了如何构建Spark机器学习系统,包括启动Spark集群、加载数据和探索数据的过程。首先讲解了Spark运行模式和SparkShell的使用,然后演示了数据的下载、上传至HDFS以及转化为数据帧的操作,最后在数据探索部分展示了获取数据统计信息和进行数据质量分析的步骤。
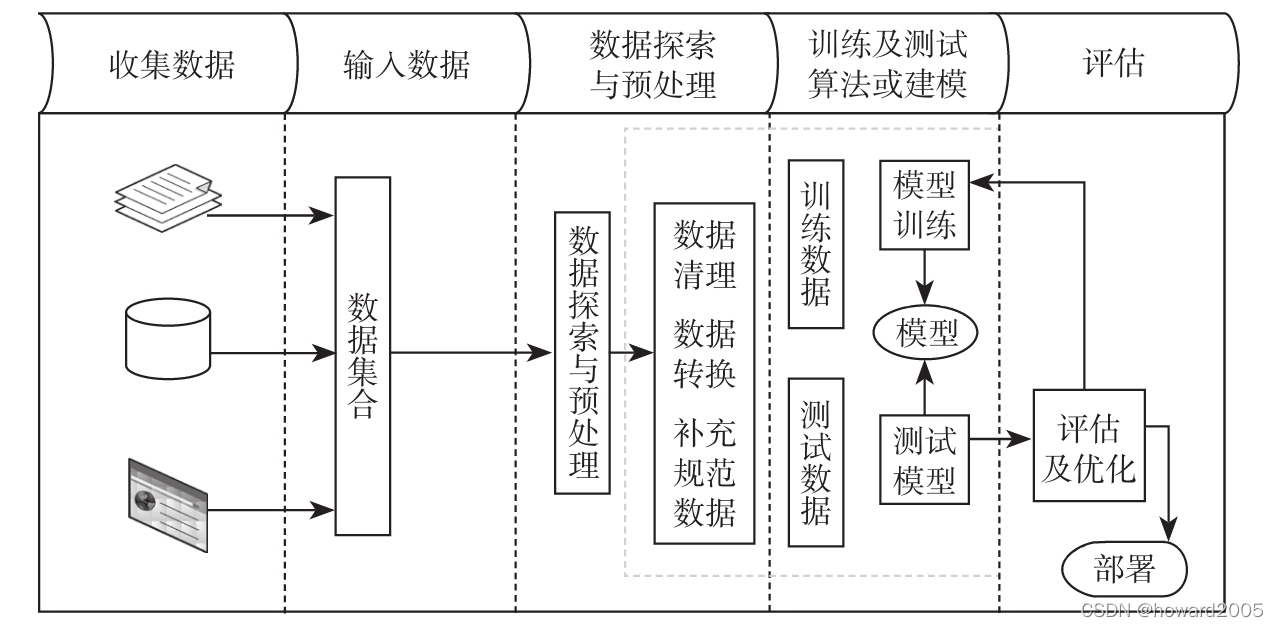
- 构建机器学习系统的方法,根据业务需求和使用工具的不同,可能会有些区别,不过主要流程差别不大,基本包括数据抽取、数据探索、数据处理、建立模型、训练模型、评估模型、优化模型、部署模型等阶段。在构建系统前,我们需要考虑系统的扩展性,与其他系统的整合,系统升级及处理方式等。
一、机器学习系统架构
- Spark机器学习系统的架构图:数据探索与预处理、训练及测试算法或建模阶段可以组装成流水线方式,模型评估及优化阶段可以采用自动化方式。
二、启动Spark集群
(一)Spark运行模式
- Spark运行方式有本地模式和集群模式。本地模式所有处理都运行在同一个JVM中,而集群模式,可以运行在不同节点上。
| 运行模式 | 含义 |
|---|---|
| local | 使用单线程在本机上运行Spark任务 |
| local[K] | 使用K个工作线程在 |

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











