







 超级会员免费看
超级会员免费看
 本文详细介绍了Spark中RDD的持久化及其必要性,通过案例展示了如何使用persist()和cache()方法进行持久化操作,以及如何选择合适的存储级别以平衡内存使用和CPU效率。同时,文章还探讨了如何利用Spark WebUI查看RDD的缓存状态,包括创建、修改存储级别以及删除缓存的RDD。
本文详细介绍了Spark中RDD的持久化及其必要性,通过案例展示了如何使用persist()和cache()方法进行持久化操作,以及如何选择合适的存储级别以平衡内存使用和CPU效率。同时,文章还探讨了如何利用Spark WebUI查看RDD的缓存状态,包括创建、修改存储级别以及删除缓存的RDD。
文章目录
零、本讲学习目标
- 理解RDD持久化的必要性
- 了解RDD的存储级别
- 学会如何查看RDD缓存
一、RDD持久化
(一)引入持久化的必要性
- Spark中的RDD是懒加载的,只有当遇到行动算子时才会从头计算所有RDD,而且当同一个RDD被多次使用时,每次都需要重新计算一遍,这样会严重增加消耗。为了避免重复计算同一个RDD,可以将RDD进行持久化。
- Spark中重要的功能之一是可以将某个RDD中的数据保存到内存或者磁盘中,每次需要对这个RDD进行算子操作时,可以直接从内存或磁盘中取出该RDD的持久化数据,而不需要从头计算才能得到这个RDD。
(二)案例演示持久化操作
1、RDD的依赖关系图
- 读取文件,进行一系列操作,有多个RDD,如下图所示。
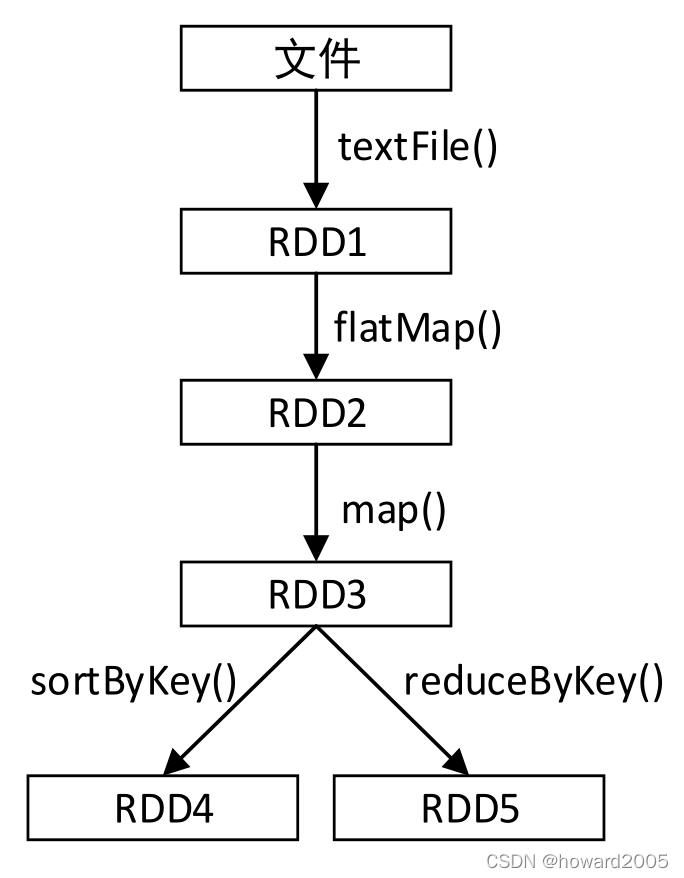
2、不采用持久化操作
- 在上图中,对RDD3进行了两次算子操作,分别生成了RDD4和RDD5。若RDD3没有持久化保存,则每次对RDD3进行操作时都需要从textFile(

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











