







 超级会员免费看
超级会员免费看
 本文详细记录了如何在CentOS7环境下搭建一个高可用的Hadoop集群,包括克隆虚拟机、设置主机名和静态IP、配置免密登录、安装JDK和ZooKeeper、搭建Hadoop集群及启动过程。通过这些步骤,实现了一个包含NameNode、DataNode、JournalNode等组件的高可用Hadoop环境。
本文详细记录了如何在CentOS7环境下搭建一个高可用的Hadoop集群,包括克隆虚拟机、设置主机名和静态IP、配置免密登录、安装JDK和ZooKeeper、搭建Hadoop集群及启动过程。通过这些步骤,实现了一个包含NameNode、DataNode、JournalNode等组件的高可用Hadoop环境。
文章目录
- 一、准备工作
- 二、搭建高可用Hadoop集群
-
- 1、Hadoop集群架构图
- 2、在三台虚拟机上安装与配置JDK
- 3、搭建ZooKeeper集群
-
- (1)下载apache-zookeeper-3.5.6-bin.tar.gz
- (2)将apache-zookeeper-3.5.6-bin.tar.gz上传到master
- (3)将apache-zookeeper-3.5.6-bin.tar.gz解压到指定位置
- (4)进入zookeeper安装目录,创建数据子目录
- (5)进入zookeeper配置目录,编辑配置文件zoo.cfg
- (6)进入zookeeper数据目录,创建myid文件
- (7)给zookeeper配置环境变量
- (8)让master上的环境配置生效
- (9)将master上的zookeeper远程拷贝到slave1与slave2
- (10)编辑slave1与slave2的myid文件
- (11)将master上的环境配置文件远程拷贝到slave1与slave2
- (12)让slave1与slave2的环境配置生效
- (13)启动zookeeper集群
- (14)关闭zookeeper集群
- 4、搭建hadoop集群
-
- (1)下载hadoop-2.10.0.tar.gz
- (2)将hadoop-2.10.0.tar.gz上传到master节点
- (3)将hadoop-2.10.0.tar.gz解压到指定位置
- (4)给hadoop配置环境变量
- (5)编辑环境配置文件hadoop-env.sh
- (6)编辑核心配置文件core-site.xml
- (7)编辑HDFS配置文件hdfs-site.xml
- (8)编辑映射归并配置文件mapred-site.xml
- (9)编辑资源调度器配置文件yarn-site.xml
- (10)编辑数据节点配置文件slaves
- (11)将master上的hadoop远程拷贝到slave1与slave2
- (12)将master上的环境配置文件远程拷贝到slave1与slave2
- 三、启动高可用Hadoop集群
-
- 1、启动ZooKeeper集群
- 2、格式化ZooKeeper集群leader节点
- 3、启动JournalNode集群
- 4、格式化master节点的NameNode
- 5、启动master节点的NameNode(active)——主名称节点
- 6、将slave1节点上的NameNode设置为standby
- 7、启动slave1节点的NameNode(standby)——热备名称节点
- 8、在master节点上启动DataNode(数据节点——工作节点)
- 9、在master和slave1节点上启动zkfc(FailOverController)
- 10、在master和slave2节点上启动yarn
- 11、对照集群结构图查看三个节点进程
- 12、在Windows系统里做三个节点IP与主机名映射
- 四、测试高可用Hadoop集群
- 五、小结Hadoop集群启动步骤
一、准备工作
1、由CentOS7克隆三个虚拟机
2、设置虚拟机主机名
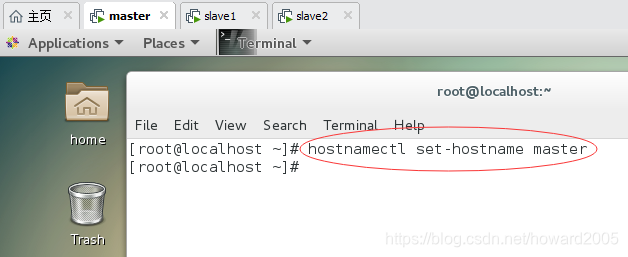
(1)设置虚拟机master主机名
hostnamectl set-hostname master
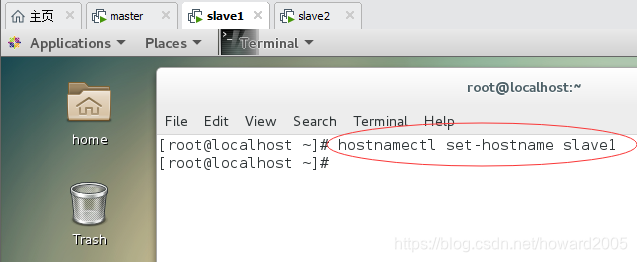
(2)设置虚拟机slave1主机名
hostnamectl set-hostname slave1
(3)设置虚拟机slave2主机名
hostnamectl set-ho

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











