




一、什么是MoE架构?
核心定义
MoE是混合专家系统的缩写,是一种通过组合多个"专家"网络来构建更大模型的技术。每个专家都是相对较小的神经网络,而门控网络负责根据输入动态选择最相关的专家。
生动比喻:医院专科会诊系统
- 传统大模型:像全科神医
-
- 一个人掌握所有医学知识
- 每次看病都动用全部知识
- 成长困难:要学新知识就得重新学习所有内容
- MoE架构:像现代化医院
-
- 心脏科、神经科、骨科等各领域专家
- 根据病情分诊到最合适的专家
- 新专家可以随时加入,不影响其他科室
MoE的基本工作原理
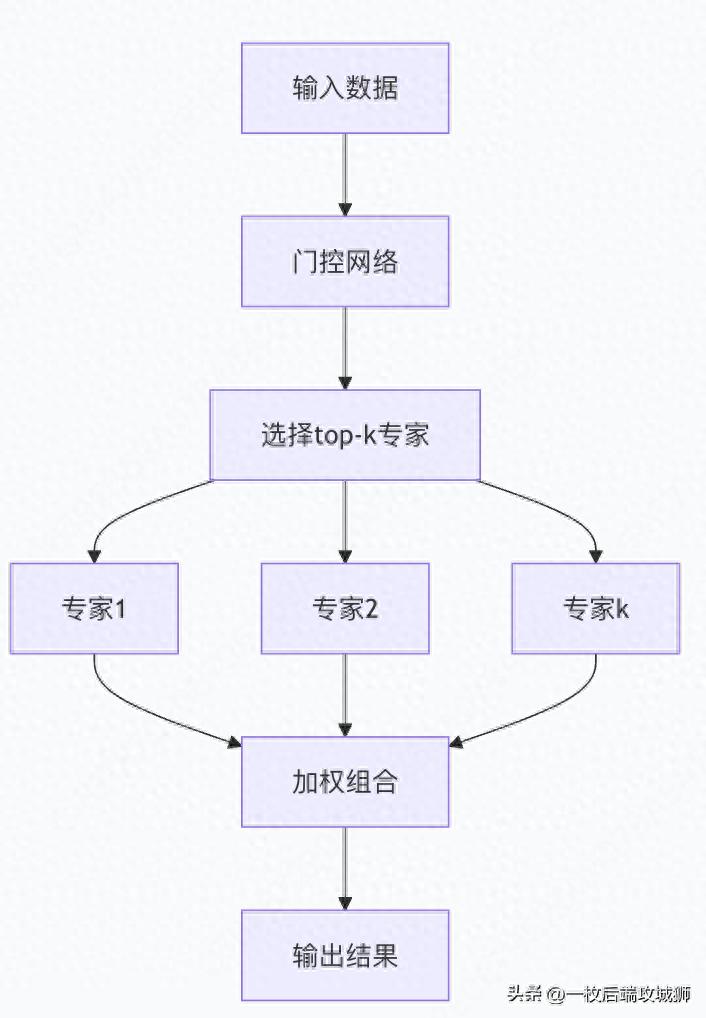
代码实现基础MoE层
import torch
import torch.nn as nn
import torch.nn.functional as F
class MoELayer(nn.Module):
def __init__(self, input_dim, output_dim, num_experts, k=2):
super().__init__()
self.num_experts = num_experts
self.k = k # 每次激活的专家数量
# 创建专家网络
self.experts = nn.ModuleList([
nn.Linear(input_dim, output_dim) for _ in range(num_experts)
])
# 门控网络
self.gate = nn.Linear(input_dim, num_experts)
def forward(self, x):
batch_size, seq_len, hidden_dim = x.shape
# 门控网络计算每个专家的权重
gate_scores = self.gate(x) # [batch_size, seq_len, num_experts]
# 选择top-k专家
topk_weights, topk_indices = torch.topk(
gate_scores, self.k, dim=-1
)
topk_weights = F.softmax(topk_weights, dim=-1)
# 初始化输出
output = torch.zeros_like(x)
# 对每个选中的专家计算贡献
for i in range(self.k):
expert_mask = topk_indices == i
expert_output = self.experts[i](x)
# 加权累加
weight = topk_weights[:, :, i:i+1]
output += expert_output * weight
return output
# 使用示例
moe_layer = MoELayer(
input_dim=512,
output_dim=512,
num_experts=8,
k=2
)
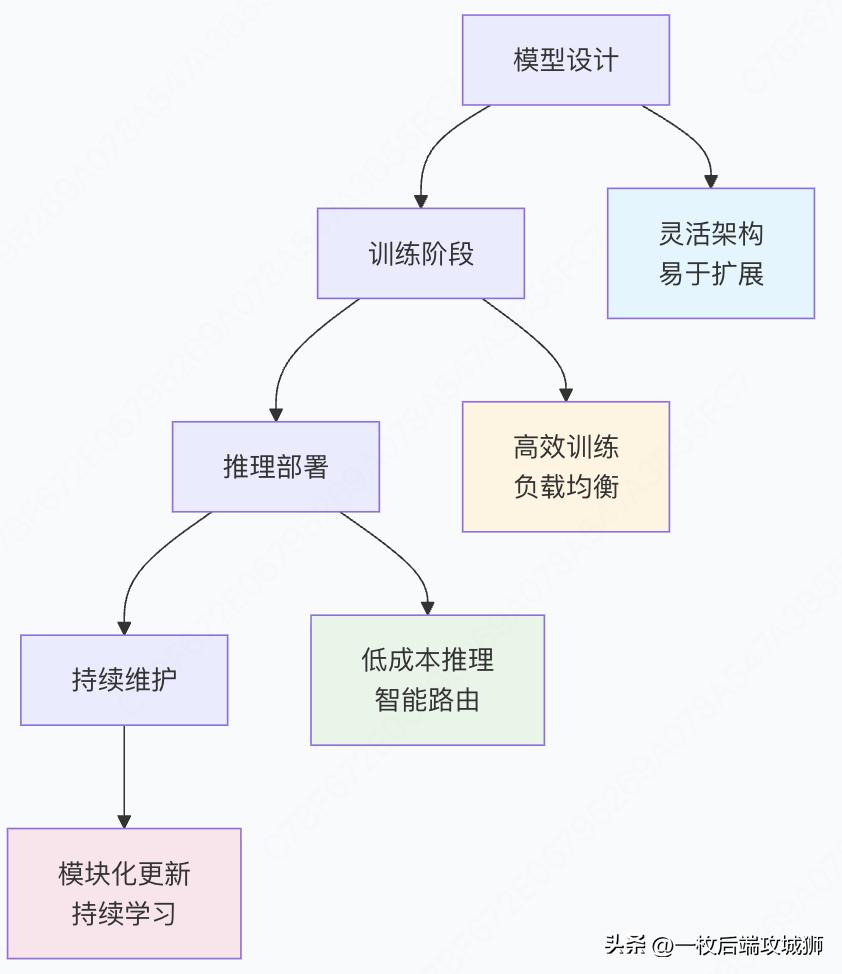
二、MoE架构的优点与全链路优势
MoE的核心优势
1.计算效率的革命

数学表达:
传统模型计算量: O(N) # N为参数量 MoE模型计算量: O(N/k × k) = O(N) # 但常数项更小 实际效果: 总参数↑,激活参数→
2.专家专业化
每个专家可以专注于不同的数据模式或任务领域:
# 专家专业化的直观示例
def visualize_expert_specialization():
experts_specialization = {
"expert_1": "处理数学推理和逻辑",
"expert_2": "处理文学创作和修辞",
"expert_3": "处理科学知识和事实",
"expert_4": "处理编程代码",
"expert_5": "处理多语言理解",
"expert_6": "处理常识推理",
"expert_7": "处理创造性思维",
"expert_8": "处理分析性思考"
}
return experts_specialization
全链路优势分析
阶段1:模型设计与训练
训练效率提升:
# 传统模型 vs MoE模型训练对比
class TrainingComparison:
def __init__(self):
self.traditional_model = {
"total_params": "175B",
"active_params": "175B", # 所有参数都激活
"training_memory": "极高",
"training_speed": "慢"
}
self.moe_model = {
"total_params": "1.7T", # 10倍参数量
"active_params": "~20B", # 每次只激活少量专家
"training_memory": "中等", # 类似20B模型
"training_speed": "较快" # 并行训练专家
}
负载均衡技术:
class LoadBalancingLoss:
"""
MoE训练中的负载均衡损失,确保专家利用率均衡
"""
def __init__(self, num_experts, importance_weight=0.01):
self.num_experts = num_experts
self.importance_weight = importance_weight
def __call__(self, gate_scores, expert_usage):
# 计算专家利用率方差
usage_variance = torch.var(expert_usage)
# 计算重要性损失(防止门控网络总是选择相同专家)
importance = gate_scores.sum(dim=0)
importance_loss = torch.var(importance)
return self.importance_weight * (usage_variance + importance_loss)
# 在训练循环中使用
def moe_training_step(model, batch, load_balance_loss):
outputs = model(batch)
task_loss = outputs.loss
# 获取门控网络输出和专家使用情况
gate_scores = outputs.gate_scores
expert_usage = outputs.expert_usage
# 计算负载均衡损失
balance_loss = load_balance_loss(gate_scores, expert_usage)
# 总损失
total_loss = task_loss + balance_loss
return total_loss
阶段2:推理与部署
推理成本优化:
# 推理时资源需求对比
inference_comparison = {
"traditional_gpt3": {
"parameters": "175B",
"gpu_memory": "350GB+", # 假设2字节/参数
"inference_speed": "较慢",
"cost_per_token": "高"
},
"moe_model": {
"total_parameters": "1.7T",
"active_parameters": "20B", # 每次激活2个专家
"gpu_memory": "40GB", # 大幅减少
"inference_speed": "较快",
"cost_per_token": "低"
}
}
动态专家选择:
class SmartMoEInference:
"""
智能MoE推理,根据输入内容选择最相关专家
"""
def __init__(self, moe_model, tokenizer):
self.model = moe_model
self.tokenizer = tokenizer
self.expert_profiles = self.analyze_expert_specialization()
def analyze_expert_specialization(self):
"""分析每个专家的专业领域"""
# 通过分析训练数据中每个专家处理的内容
# 建立专家能力画像
profiles = {}
for i in range(self.model.num_experts):
profiles[i] = {
"strengths": ["math", "code", "creative", ...], # 专业领域
"confidence_threshold": 0.3, # 激活阈值
"performance_metrics": {...}
}
return profiles
def route_to_experts(self, input_text):
"""智能路由到相关专家"""
# 分析输入内容
content_analysis = self.analyze_content(input_text)
# 基于内容分析选择最相关的专家
relevant_experts = self.select_relevant_experts(content_analysis)
return relevant_experts
def generate(self, prompt, max_experts=2):
"""使用智能专家选择的生成"""
relevant_experts = self.route_to_experts(prompt)
# 限制使用的专家数量
selected_experts = relevant_experts[:max_experts]
# 使用选中的专家进行生成
output = self.model.generate(
prompt,
active_experts=selected_experts
)
return output
阶段3:持续学习与更新
模块化更新优势:
class MoEContinuousLearning:
"""
MoE模型的持续学习能力
"""
def __init__(self, base_model):
self.model = base_model
def add_new_expert(self, new_domain_data):
"""添加处理新领域数据的专家"""
# 1. 训练新专家
new_expert = self.train_expert_on_new_domain(new_domain_data)
# 2. 添加到模型(不影响现有专家)
self.model.add_expert(new_expert)
# 3. 微调门控网络学习何时使用新专家
self.finetune_gating_network()
def update_expert(self, expert_id, update_data):
"""更新特定专家"""
# 只更新单个专家,不影响其他专家
self.model.experts[expert_id].train_on_data(update_data)
def expert_ablation_study(self):
"""专家贡献度分析"""
contributions = {}
for i, expert in enumerate(self.model.experts):
# 临时禁用该专家,观察性能变化
original_performance = self.evaluate_model()
disabled_performance = self.evaluate_without_expert(i)
contributions[i] = original_performance - disabled_performance
return contributions
全链路优势总结
三、采用MoE架构的大模型
主流MoE模型概览
1.Google的MoE先驱
Switch Transformer:
# Switch Transformer配置
switch_transformer_config = {
"model_name": "Switch Transformer",
"release_date": "2021",
"total_parameters": "1.6T",
"active_parameters": "7B per token",
"num_experts": 2048,
"experts_used": 1, # Switch: 每次只使用1个专家
"key_innovation": "简化路由,每次只选1个专家",
"performance": "在相同计算预算下,比T5快7倍"
}
# Switch Transformer的核心创新
class SwitchTransformerLayer(nn.Module):
def __init__(self, d_model, d_ff, num_experts):
super().__init__()
# 使用Switch注意力:每个token路由到单个专家
self.switch_layer = SwitchLinear(d_model, d_ff, num_experts)
def forward(self, x):
# 每个输入token独立选择最适合的专家
return self.switch_layer(x)
GLaM模型:
glam_config = {
"model_name": "GLaM",
"total_parameters": "1.2T",
"active_parameters": "96B per token",
"num_experts": 64,
"experts_used": 2,
"specialization": "每个专家专注不同主题领域",
"performance": "在29个NLP任务中超越GPT-3"
}
2.开源社区的MoE模型
Mixtral 8x7B:
mixtral_config = {
"model_name": "Mixtral 8x7B",
"developer": "Mistral AI",
"total_parameters": "47B", # 8个专家×7B,但实际有效参数量
"active_parameters": "13B", # 每次激活2个专家
"num_experts": 8,
"experts_used": 2,
"context_length": "32K",
"key_features": [
"开源可用",
"多语言支持",
"代码能力优秀",
"推理成本相当于13B模型"
]
}
# Mixtral的架构特点
class MixtralArchitecture:
def __init__(self):
self.base_model = "Mistral 7B"
self.moe_layers = [4, 8, 16, 20, 24, 28] # 在这些层使用MoE
self.expert_architecture = {
"type": "前馈网络专家",
"size": "与Mistral 7B的FFN相同",
"activation": "SiLU"
}
DeepSeek-MoE:
deepseek_moe_config = {
"model_name": "DeepSeek-MoE",
"total_parameters": "16B",
"active_parameters": "2.8B",
"num_experts": 64,
"experts_used": 4,
"compression_ratio": "5.7x", # 参数压缩比
"innovation": "细粒度专家设计"
}
3.商业化MoE模型
GPT-4的推测架构:
# 基于公开信息的推测
gpt4_moe_speculation = {
"model_name": "GPT-4",
"total_parameters": "~1.8T",
"active_parameters": "~100B per token",
"num_experts": "8-16",
"architecture": "混合专家Transformer",
"evidence": [
"不同回答风格显示专家专业化",
"计算成本远低于同等参数量的稠密模型",
"多模态能力可能对应不同专家组"
]
}
MoE模型对比表格
|
模型 |
总参数量 |
激活参数量 |
专家数量 |
使用专家数 |
主要特点 |
|
Switch Transformer |
1.6T |
7B |
2048 |
1 |
简化路由,高效训练 |
|
GLaM |
1.2T |
96B |
64 |
2 |
主题专家专业化 |
|
Mixtral 8x7B |
47B |
13B |
8 |
2 |
开源,性能优秀 |
|
DeepSeek-MoE |
16B |
2.8B |
64 |
4 |
高压缩比,细粒度专家 |
|
GPT-4(推测) |
~1.8T |
~100B |
8-16 |
2-4 |
多模态,商业化 |
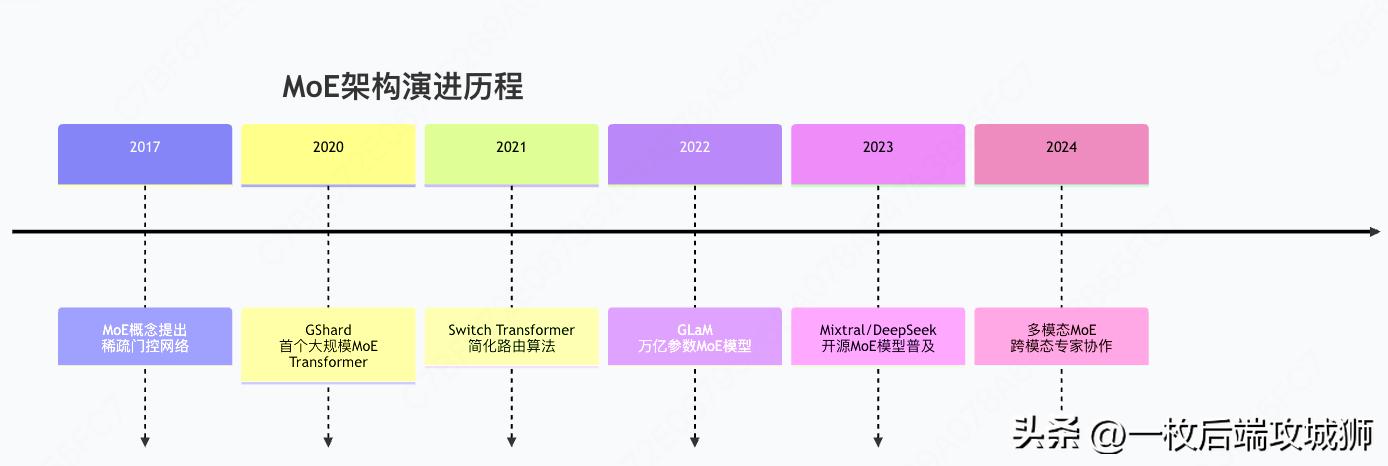
MoE架构的演进趋势
四、MoE实践指南与代码示例
完整的MoE Transformer实现
import torch
import torch.nn as nn
from transformers import GPT2Config, GPT2Model
class MoETransformerBlock(nn.Module):
"""MoE Transformer块"""
def __init__(self, config, moe_config):
super().__init__()
self.config = config
self.moe_config = moe_config
# 自注意力层
self.self_attention = nn.MultiheadAttention(
config.n_embd, config.n_head, batch_first=True
)
self.attention_norm = nn.LayerNorm(config.n_embd)
# MoE前馈层
self.moe_ffn = MoEFeedForward(
config.n_embd,
config.n_embd * 4, # 扩展维度
moe_config.num_experts,
moe_config.experts_used
)
self.ffn_norm = nn.LayerNorm(config.n_embd)
def forward(self, x, attention_mask=None):
# 自注意力
residual = x
x = self.attention_norm(x)
attn_output, _ = self.self_attention(x, x, x, attn_mask=attention_mask)
x = residual + attn_output
# MoE前馈
residual = x
x = self.ffn_norm(x)
ff_output, expert_usage = self.moe_ffn(x)
x = residual + ff_output
return x, expert_usage
class MoEFeedForward(nn.Module):
"""MoE前馈网络"""
def __init__(self, d_model, d_ff, num_experts, experts_used):
super().__init__()
self.num_experts = num_experts
self.experts_used = experts_used
# 专家网络
self.experts = nn.ModuleList([
nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Linear(d_ff, d_model)
) for _ in range(num_experts)
])
# 门控网络
self.gate = nn.Linear(d_model, num_experts)
# 负载均衡统计
self.register_buffer('expert_usage', torch.zeros(num_experts))
def forward(self, x):
batch_size, seq_len, d_model = x.shape
# 门控计算
gate_logits = self.gate(x) # [batch_size, seq_len, num_experts]
# 选择top-k专家
topk_weights, topk_indices = torch.topk(
gate_logits, self.experts_used, dim=-1
)
topk_weights = torch.softmax(topk_weights, dim=-1)
# 初始化输出
output = torch.zeros_like(x)
# 更新专家使用统计
expert_usage = torch.zeros(self.num_experts, device=x.device)
# 对每个位置计算专家输出
for i in range(self.experts_used):
# 创建当前专家的mask
expert_mask = topk_indices == i
# 计算当前专家的输出
expert_output = self.experts[i](x)
# 加权累加
weight = topk_weights[:, :, i:i+1]
output += expert_output * weight * expert_mask.float()
# 更新使用统计
expert_usage[i] += expert_mask.sum().item()
# 归一化使用统计
expert_usage = expert_usage / (batch_size * seq_len)
self.expert_usage = 0.9 * self.experty_usage + 0.1 * expert_usage
return output, expert_usage
class MoEGPT2(nn.Module):
"""基于GPT2的MoE模型"""
def __init__(self, config, moe_config):
super().__init__()
self.config = config
self.moe_config = moe_config
# 词嵌入
self.wte = nn.Embedding(config.vocab_size, config.n_embd)
self.wpe = nn.Embedding(config.n_positions, config.n_embd)
# MoE Transformer层
self.layers = nn.ModuleList([
MoETransformerBlock(config, moe_config)
for _ in range(config.n_layer)
])
# 输出层
self.ln_f = nn.LayerNorm(config.n_embd)
self.head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
def forward(self, input_ids, attention_mask=None):
batch_size, seq_len = input_ids.shape
# 位置编码
position_ids = torch.arange(seq_len, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand(batch_size, -1)
# 输入嵌入
inputs_embeds = self.wte(input_ids)
position_embeds = self.wpe(position_ids)
hidden_states = inputs_embeds + position_embeds
# 通过MoE层
expert_usage_history = []
for layer in self.layers:
hidden_states, expert_usage = layer(hidden_states, attention_mask)
expert_usage_history.append(expert_usage)
# 输出投影
hidden_states = self.ln_f(hidden_states)
logits = self.head(hidden_states)
return logits, expert_usage_history
# 配置示例
gpt2_config = GPT2Config(
vocab_size=50257,
n_embd=768,
n_layer=12,
n_head=12,
n_positions=1024
)
moe_config = type('MoEConfig', (), {
'num_experts': 8,
'experts_used': 2
})()
# 创建MoE模型
model = MoEGPT2(gpt2_config, moe_config)
训练优化技巧
class MoETrainingOptimizer:
"""MoE模型训练优化"""
def __init__(self, model, learning_rate=1e-4):
self.model = model
# 不同部分使用不同学习率
self.optimizer = torch.optim.AdamW([
{'params': model.wte.parameters(), 'lr': learning_rate},
{'params': model.wpe.parameters(), 'lr': learning_rate},
{'params': [p for n, p in model.named_parameters()
if 'experts' in n], 'lr': learning_rate * 2},
{'params': [p for n, p in model.named_parameters()
if 'gate' in n], 'lr': learning_rate * 5},
])
def load_balancing_loss(self, expert_usage_history):
"""计算负载均衡损失"""
total_loss = 0
for expert_usage in expert_usage_history:
# 鼓励均匀使用专家
usage_mean = expert_usage.mean()
usage_std = expert_usage.std()
balance_loss = usage_std / (usage_mean + 1e-6)
total_loss += balance_loss
return total_loss
def training_step(self, batch, balance_weight=0.01):
input_ids, labels = batch
# 前向传播
logits, expert_usage_history = self.model(input_ids)
# 任务损失
task_loss = F.cross_entropy(
logits.view(-1, logits.size(-1)),
labels.view(-1)
)
# 负载均衡损失
balance_loss = self.load_balancing_loss(expert_usage_history)
# 总损失
total_loss = task_loss + balance_weight * balance_loss
# 反向传播
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return {
'total_loss': total_loss.item(),
'task_loss': task_loss.item(),
'balance_loss': balance_loss.item()
}
总结:MoE架构的革命性意义
技术突破的核心价值
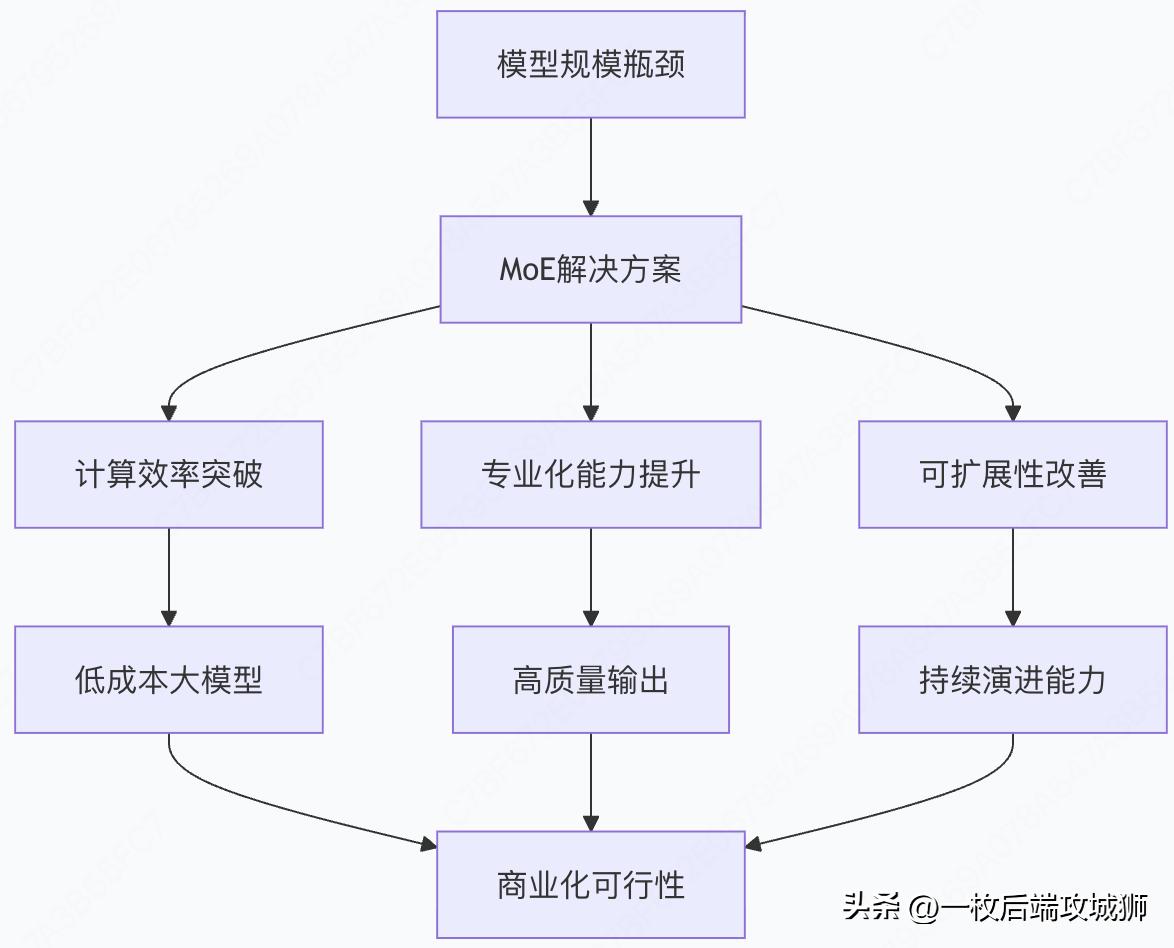
关键成功因素
- 稀疏激活:保持计算效率的同时大幅增加参数量
- 专家专业化:每个专家专注特定领域,提升整体能力
- 模块化设计:支持灵活扩展和更新
- 智能路由:动态选择最适合的专家组合
未来发展方向
- 更细粒度专家:从层级别到神经元级别的MoE
- 跨模态专家:处理文本、图像、音频的多模态MoE
- 动态专家数量:根据任务复杂度自动调整激活专家数
- 联邦MoE:分布式专家网络,保护数据隐私
实践建议
对于不同场景的MoE采用策略:
|
场景 |
建议 |
理由 |
|
研究实验 |
从小规模MoE开始(4-8专家) |
快速验证,调试路由机制 |
|
生产部署 |
选择成熟开源MoE(Mixtral) |
稳定性验证,社区支持 |
|
资源受限 |
高压缩比MoE(DeepSeek-MoE) |
平衡性能与成本 |
|
前沿探索 |
自定义MoE架构 |
针对特定任务优化 |
MoE架构不仅解决了大模型的规模扩展问题,更重要的是为AI系统提供了一种模块化、专业化、可演进的智能构建范式。这不仅是技术的进步,更是AI工程范式的革命,为构建真正通用、高效、可持续的人工智能系统奠定了坚实基础。


















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











