




阿里巴巴
在就在 12 月 25 日,阿里云通义千问携一款重磅之作 —— 业界首个开源多模态推理模型 QVQ-72B-Preview 惊艳亮相。
QVQ-72B
QVQ 使用页面
QVQ-72B-Preview 基于 Qwen2-VL-72B 构建,拥有令人惊叹的视觉理解与推理能力。它就像一个智慧超群的 “大脑”,无论是面对复杂的 “梗图”,还是真实照片中的物体,都能轻松识别其内涵,并准确推断出物体个数及高度等信息。
参数对比
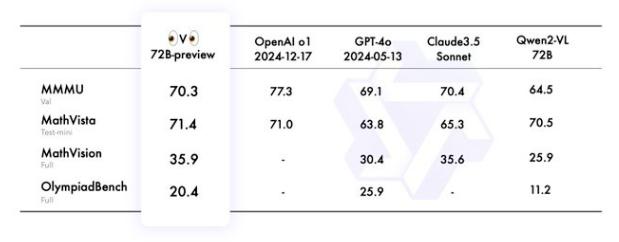
参数对比
在 MMMU 评测中,QVQ-72B-Preview 取得了 70.3 的高分,这意味着它的认知水平已达到大学生级别,在视觉理解方面成功超越了此前的顶尖模型 Qwen2-VL。在解决数学、物理、化学等各科学领域的难题时,QVQ-72B-Preview 更是展现出卓越的才能,能像人甚至科学家一样,给出详细的思考过程和准确答案。
在 MathVista 和 MathVision 评测中,它的表现超越了 Claude3.5 及 GPT-4,在多步推理任务中,例如物理问题中结合文字和视觉信息推导因果关系,以及数学推理任务中的分步推理,都显著减少了错误率,展现出强大的逻辑思维和分析能力。
不仅如此,QVQ-72B-Preview 在技术报告、复杂图表分析中提取关键信息的准确率和效率也极高,能够快速准确地从复杂的文档和图表中提取出关键信息,为科研人员、分析师等专业人士提供了强大的辅助工具,极大地提高了工作效率。
目前,QVQ-72B-Preview 已在魔搭社区和 HuggingFace 平台上开源,开发者可上手体验。尽管 QVQ-72B-Preview 表现出色,但作为一个实验性研究模型,也存在语言混合与切换、陷入循环推理、安全和伦理考虑以及在多步骤视觉推理过程中可能会逐渐失去对图像内容的关注而产生幻觉等局限性。但相信在未来,随着技术的不断优化和改进,QVQ-72B-Preview 将在多模态推理领域发挥更加重要的作用,为人工智能的发展注入新的动力。
有关慧星云
慧星云致力于为用户提供稳定、可靠、易用、省钱的 GPU 算力解决方案。海量 GPU 算力资源租用,就在慧星云。

















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









