







鸣谢以下博文提供的支持:
1、https://blog.youkuaiyun.com/u013063153/article/details/74171362
2、https://blog.youkuaiyun.com/gx304419380/article/details/79868404
3、http://livy.incubator.apache.org/
背景:
Apache Spark提供的两种基于命令行的处理交互方式虽然足够灵活,但在企业应用中面临诸如部署、安全等问题。为此本文引入Livy这样一个基于Apache Spark的REST服务,它不仅以REST的方式代替了Spark传统的处理交互方式,同时也提供企业应用中不可忽视的多用户,安全,以及容错的支持。
Livy
Livy是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行。它提供了以下这些基本功能:
- 提交Scala、Python或是R代码片段到远端的Spark集群上执行;
- 提交Java、Scala、Python所编写的Spark作业到远端的Spark集群上执行;
- 提交批处理应用在集群中运行。
从Livy所提供的基本功能可以看到Livy涵盖了原生Spark所提供的两种处理交互方式。与原生Spark不同的是,所有操作都是通过REST的方式提交到Livy服务端上,再由Livy服务端发送到不同的Spark集群上去执行。说到这里我们首先来了解一下Livy的架构。
部署:
从官方网站下载最新的资源包http://livy.incubator.apache.org/,目前是0.6版本
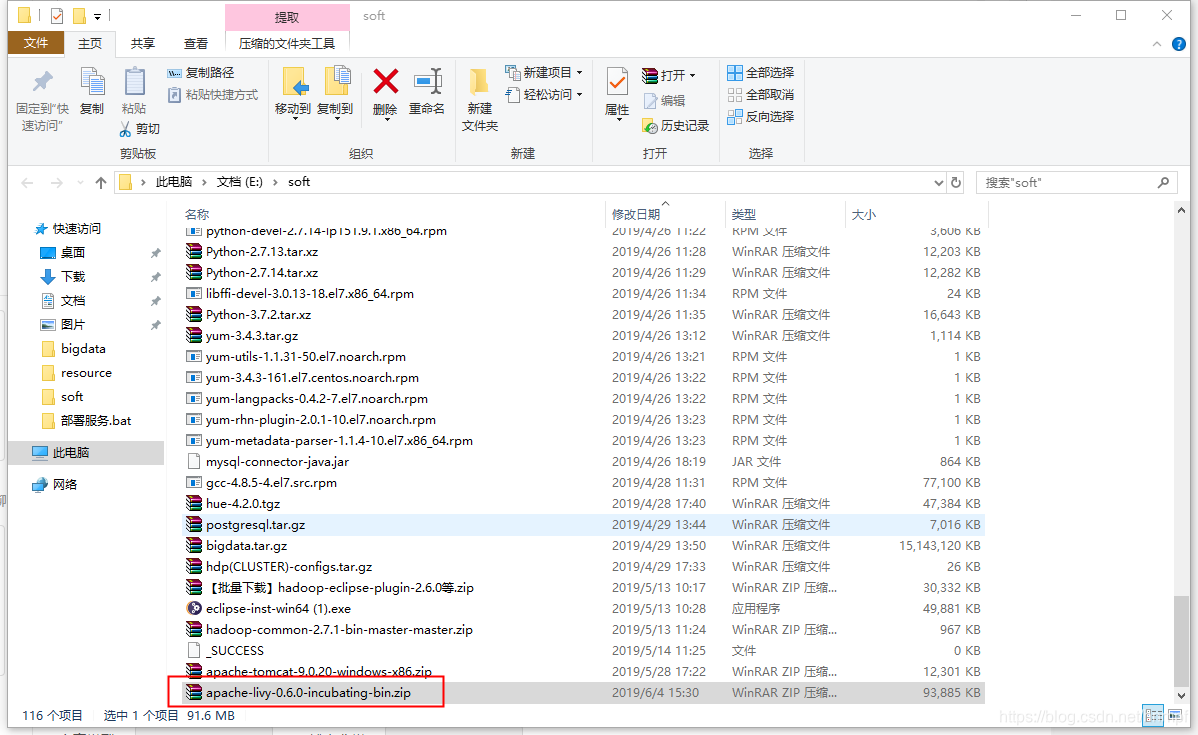
将下载到的资源包上传到相应的服务器并解压
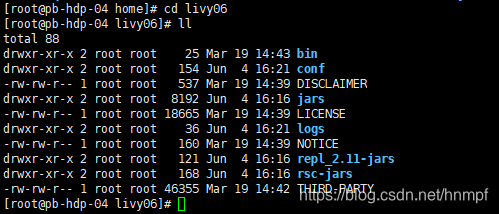
解压后的目录:
配置
进入conf 目录 ,并mv livy-env.sh.tmplate livy-env.sh

在livy-env.sh 环境变量文件中添加如下配置
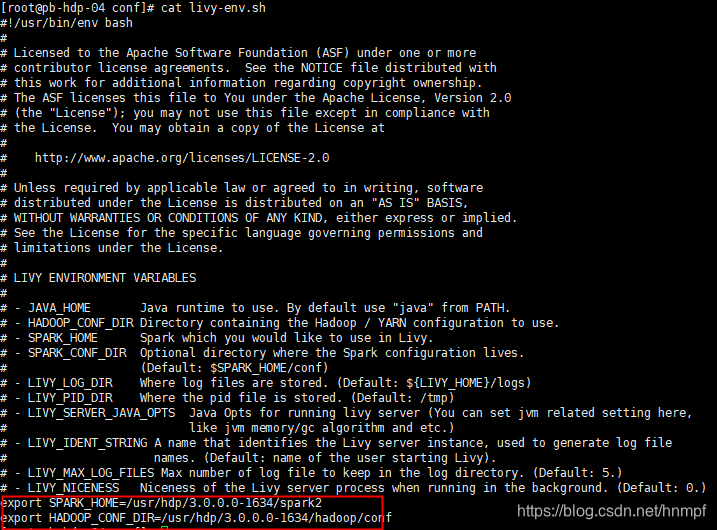
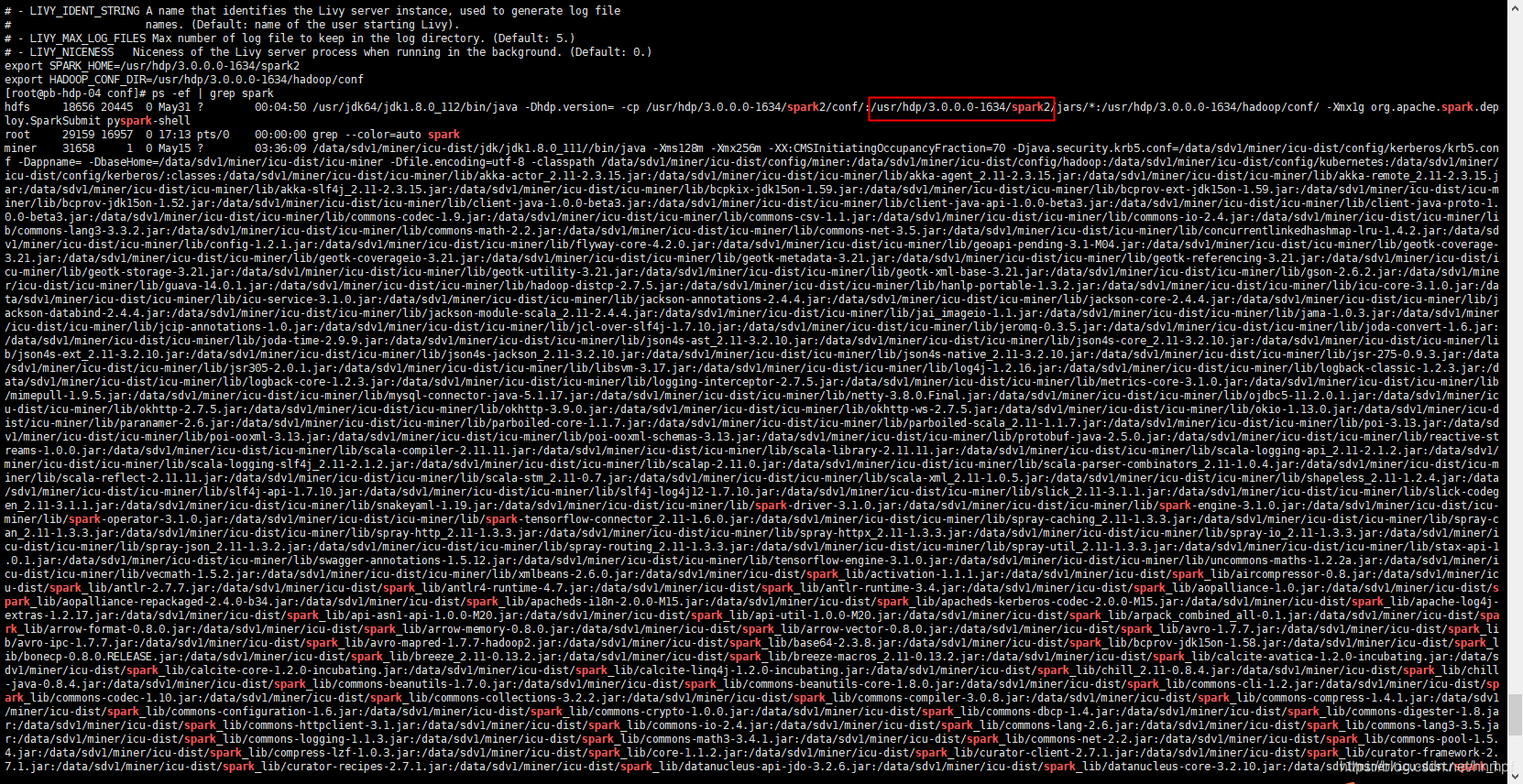
上图中的2个环境变量地址必须真实有效,可以通过 ps -ef|grep spark 来获取当前服务器上的spark 环境变量(切记:livy务必安装到有spark服务的服务端,因为其本身就是一个客户端,集群中有可能部分节点只安装了spark的客户端)
如下,只有客户端:

如下,有服务端:
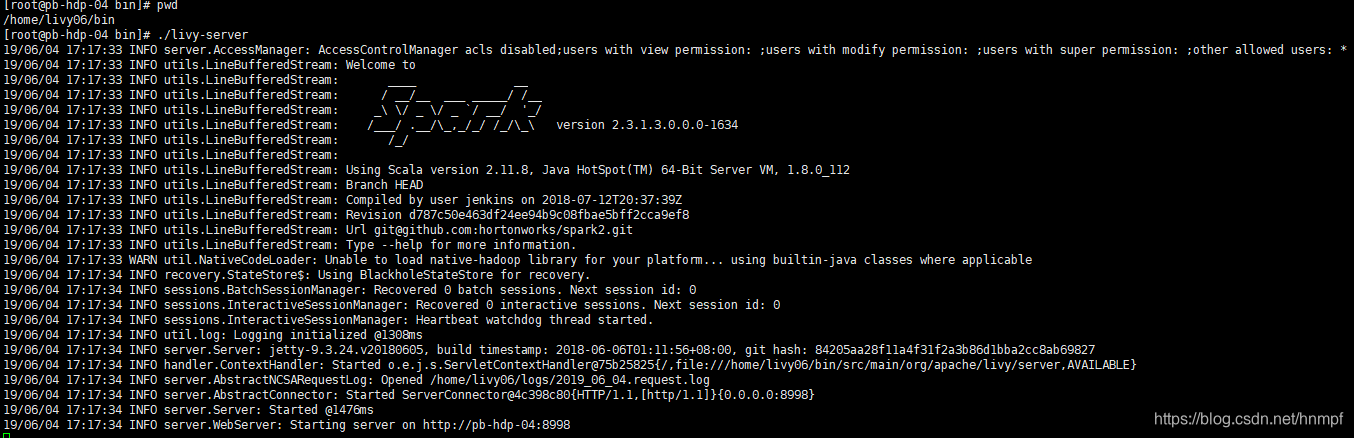
启动livy:
返回到livy的bin 目录
![]()
#前台模式,
可观察程序运行日志
./livy-server
#后台模式
./livy-server start
测试
1、启动postman,通过http://pb-hdp-04:8998/sessions把下列报文用post发送出去
{
"kind":"spark",
"name":"pb Spark first test",
"executorMemory":"2g",
"executorCores":2
}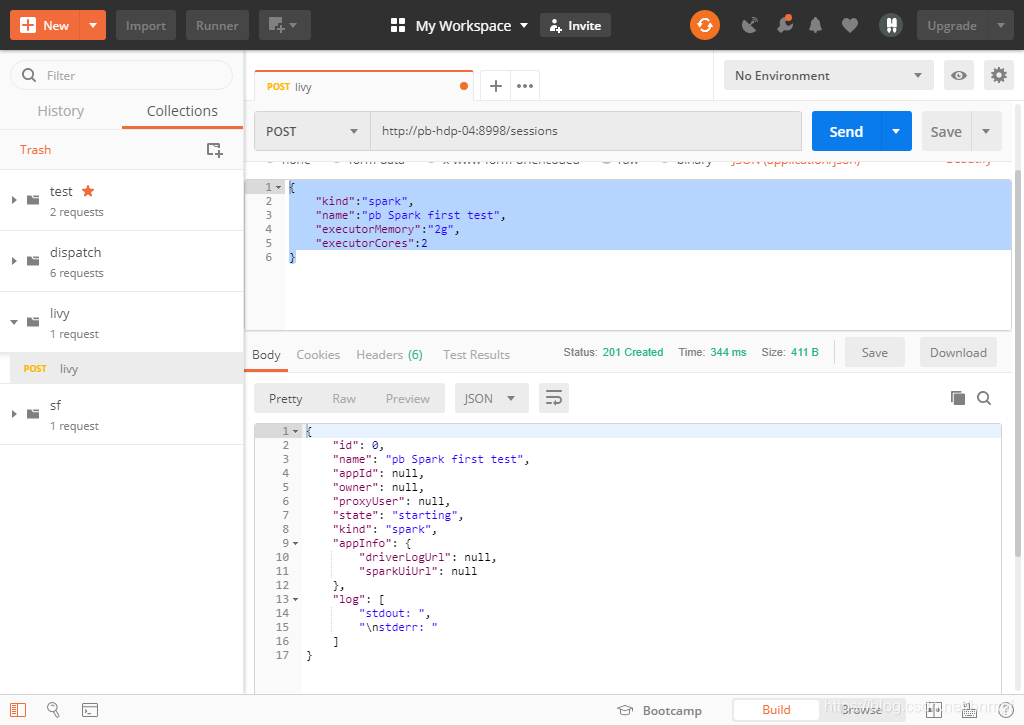
根据返回值中ID的值,如上面返回的是0,这样就可以实现livy与spark建立了成功的sesson 通信连接,有了它我们就可以执行spark程序
2、通过http://pb-hdp-04:8998/sessions/0/statements 【http://pb-hdp-04:8998/sessions/{id}/statements】来获取执行该spark任务节点ID
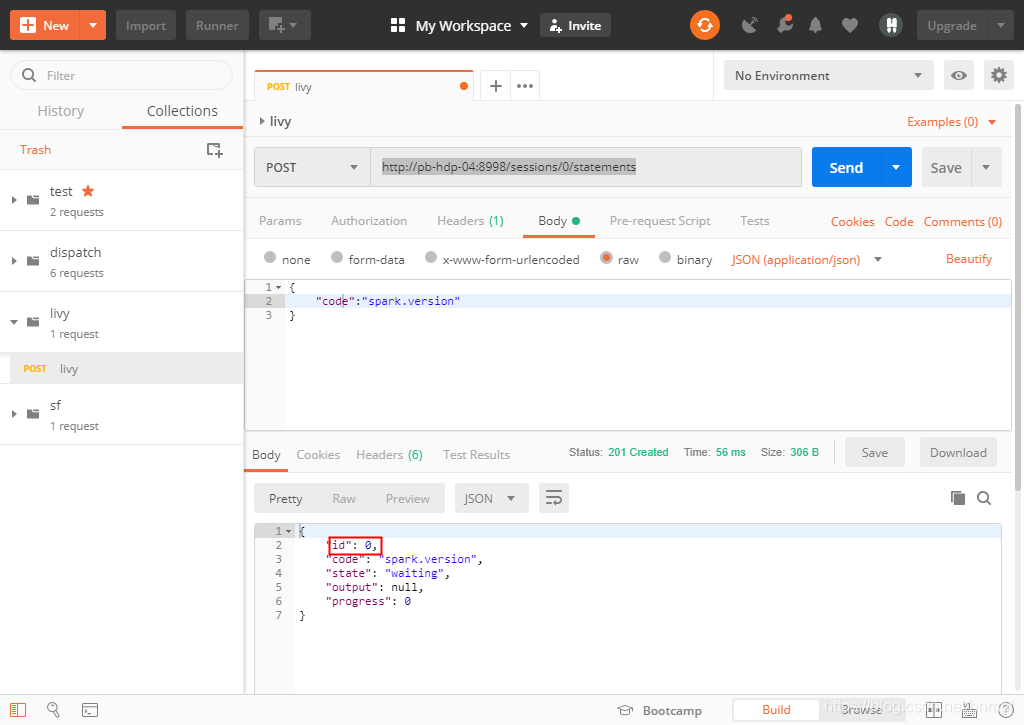
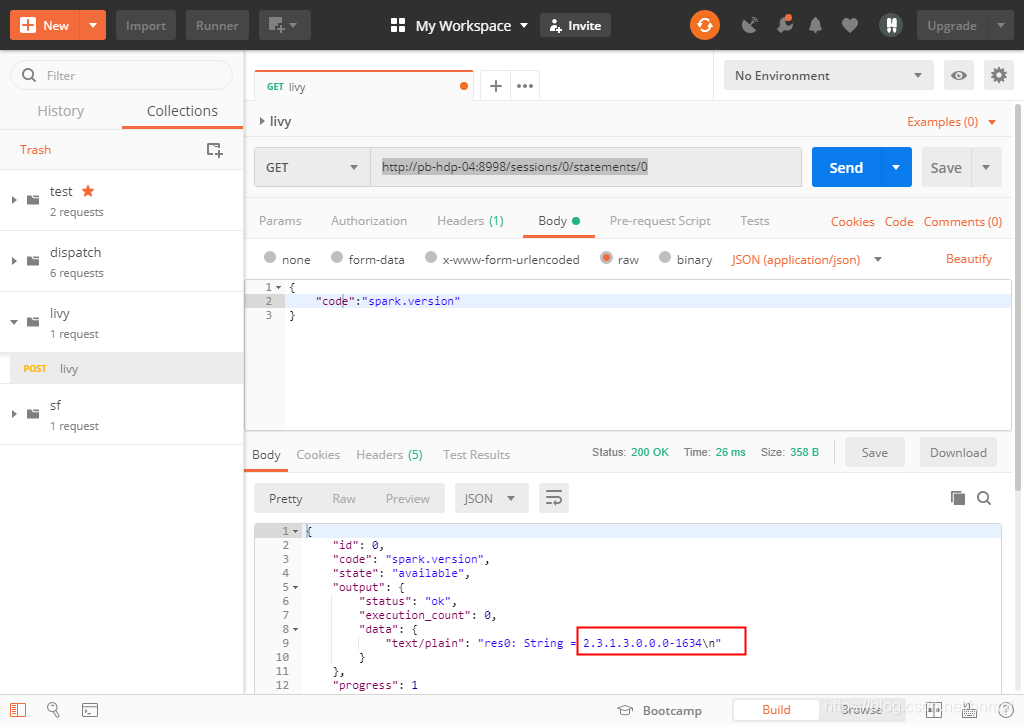
3、通过http://pb-hdp-04:8998/sessions/0/statements/0 【http://pb-hdp-04:8998/sessions/{sessionsID}/statements/{statementsID}】来获取statementsID对应指令执行的结果
livy管理界面
通过http://pb-hdp-04:8998/ui 来加载页面
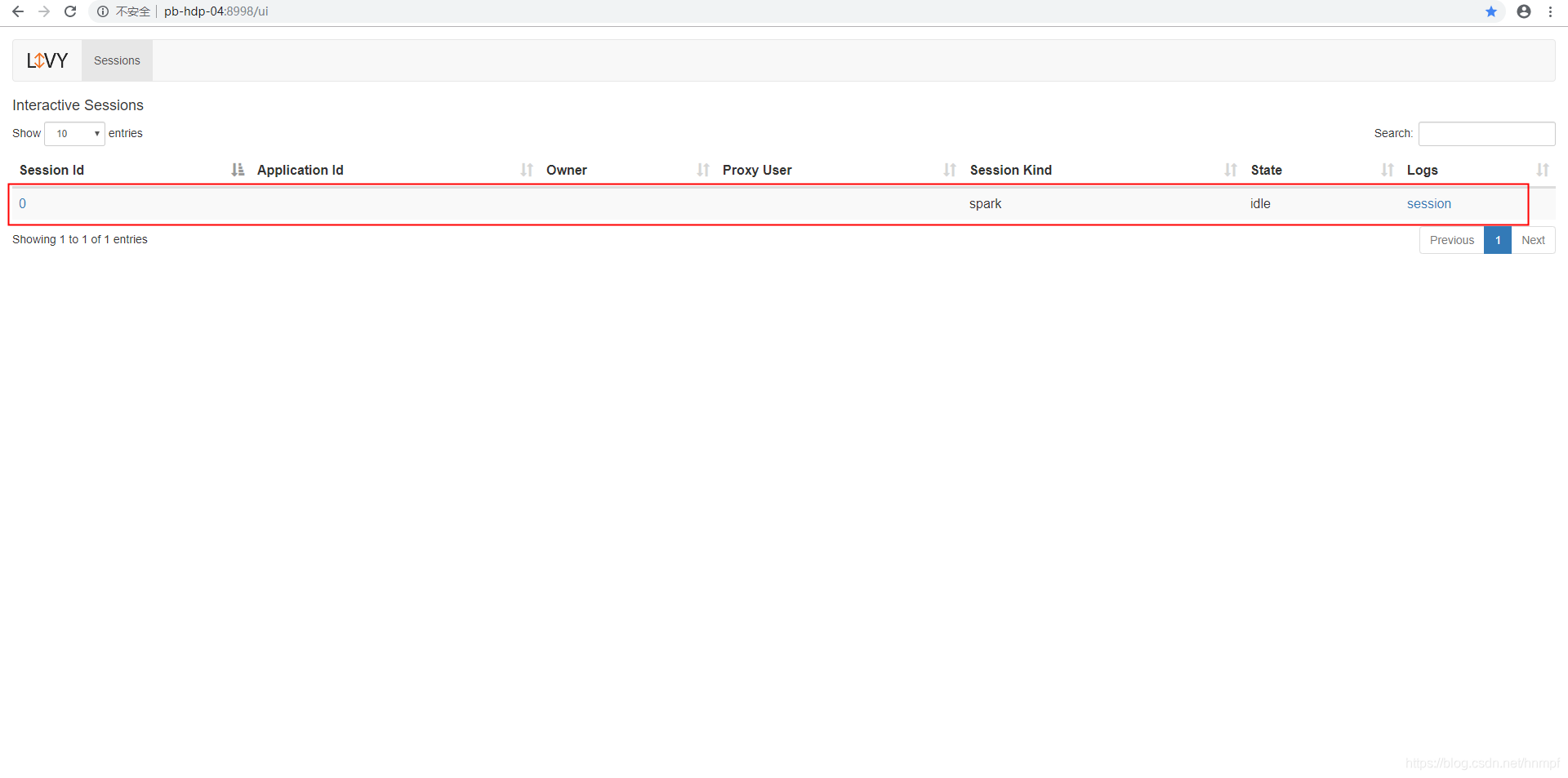
至此一个基于livy的测试用例也完成了。不过这只是测试一个livy的指令模式,还没有测试 livy的批量模式。

















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









