




背景:
为了比较系统的学习大模型的训练与应用有了该样例,仅供由此爱好的初学者参考和给自己留存。
本文将以去哪网酒店预订评论数据作为训练材料进行模型训练,力求达到输入中文描述,模型自动匹配该描述是好评还是差评。
材料:
1、准备数据(自行准备,内容结构如下)
label,review
0,"距离川沙公路较近,但是公交指示不对,如果是""蔡陆线""的话,会非常麻烦.建议用别的路线.房间较为简单."
1,商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!
0,早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。
1,宾馆在小街道上,不大好找,但还好北京热心同胞很多~宾馆设施跟介绍的差不多,房间很小,确实挺小,但加上低价位因素,还是无超所值的;环境不错,就在小胡同内,安静整洁,暖气好足-_-||。。。呵还有一大优势就是从宾馆出发,步行不到十分钟就可以到梅兰芳故居等等,京味小胡同,北海距离好近呢。总之,不错。推荐给节约消费的自助游朋友~比较划算,附近特色小吃很多~
0,"CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风"
1,总的来说,这样的酒店配这样的价格还算可以,希望他赶快装修,给我的客人留些好的印象
0,价格比比较不错的酒店。这次免费升级了,感谢前台服务员。房子还好,地毯是新的,比上次的好些。早餐的人很多要早去些。
1,不错,在同等档次酒店中应该是值得推荐的!2、 下载预训练模型(由于从源头开始训练模型太费时也费资源,我们采用已训练好的预训练模型进行微调),对于已经预训练好的模型bert-base-chinese的下载可以去Hugging face下载,网址是:Hugging Face – The AI community building the future.
通过搜索找到模型并下载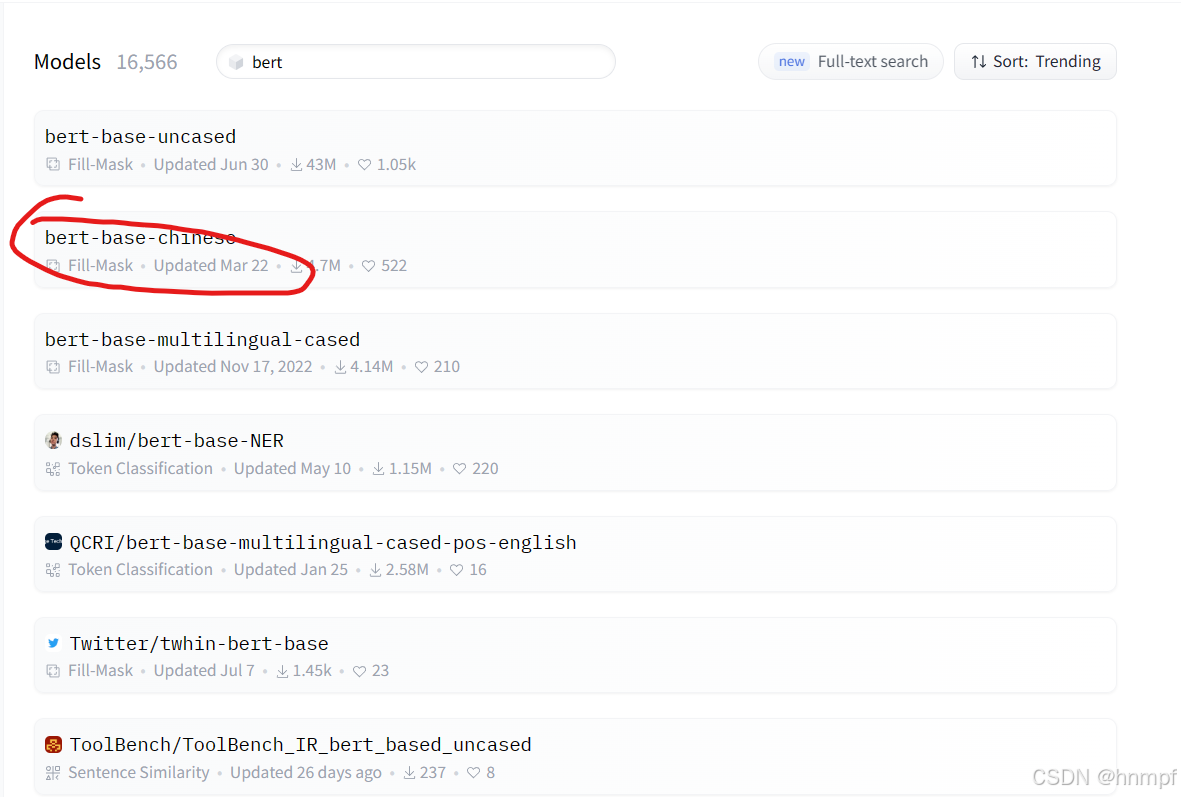
3、准备python 环境(python 版本要>3.8)
制作:
模型训练
1、引入的库
import pandas as pd
from sklearn.model_selection import train_test_split
from datasets import Dataset, DatasetDict
import numpy as np
from transformers import BertTokenizer, BertForSequenceClassification, DataCollatorWithPadding, TrainingArguments, Trainer, EvalPrediction
from sklearn.metrics import f1_score, accuracy_score2、加载待训练数据并处理
# 取数
def get_trans_data(file_path):
data = []
with open(file_path, 'r', encoding='UTF-8') as file:
for line in file:
if len(line) > 0:
label, review = line.strip().split(',', 1)
# 如果 label 是标签,需要在这里将其映射为数字
data.append({'text': review.strip(), 'label': int(label.strip() if label.strip().isdigit() else 0)})
return data3、 对数据进行加工,将数据分割为训练数据、验证数据并借助dataset库中的方法将数据转换成便于大模型训练的数据集
# 对数据进行加工,使其变成大模型训练需要的向量数据结构
def chenge_data(sourceData):
# 为了使用train_test_split 数据拆分工具类,借助pandas 对数据进行转换
data_df = pd.DataFrame(sourceData)
train_data, test_data = train_test_split(data_df, test_size=0.2, random_state=50)
# 分别对数据进行向量转换.
train_dataset = Dataset.from_pandas(train_data)
test_dataset = Dataset.from_pandas(test_data)
datasetDict = DatasetDict({'tran_dataset': train_dataset, 'test_dataset': test_dataset})
return datasetDict4、训练模型并评估模型
# 加载预训练模型并进行词句切割
def train_model(datasetDict):
# 加载模型分词器(简化,其实需要做现行回归)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









