









 本文详细介绍了主席树,一种可持久化的线段树数据结构,重点讲解了其原理、特点、实现中的前缀和、离散化技巧以及在查询区间第k小值问题中的应用实例。通过代码示例和应用场景,帮助读者理解如何利用主席树优化空间和时间复杂度。
本文详细介绍了主席树,一种可持久化的线段树数据结构,重点讲解了其原理、特点、实现中的前缀和、离散化技巧以及在查询区间第k小值问题中的应用实例。通过代码示例和应用场景,帮助读者理解如何利用主席树优化空间和时间复杂度。
【主席树简介】
主席树,即可持久化线段树,又称函数式线段树,是重要的可持久化数据结构之一。所谓可持久化,是指可以回溯到历史版本。
主席树的本质,就是在有数据更新时,在基准线段树的基础上采用“结点复用”的方式仅仅增加少量结点来维护历史数据,而不是通过存储不同版本线段树的方式来维护历史数据,从而达到减少时空消耗的目的,避免出现TLE(Time Limit Exceeded)及MLE(Memory Limit Exceeded)错误。主席树空间一般建议是开 n<<5 (n为基准线段树的结点数)。
如在下图中,橙色结点为历史结点,其右边多出来的结点是新结点(修改结点)。
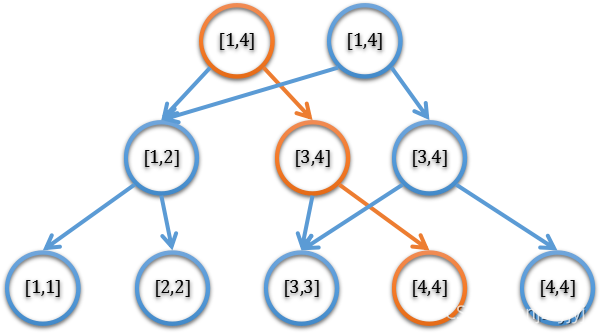
主席树的名称,来源于其发明人黄嘉泰的姓名首字母缩写HJT,与我们的某位主席的姓名首字母缩写一样。
实现主席树时,需要经常用到前缀和、离散化等思想。现分别陈述如下:
1. 前缀和:如需得到区间 [L,R] 的统计信息,只需用区间 [1,R] 的统计信息减去区间 [1,L-1] 的统计信息就可以了。
利用前缀和,降低时间复杂度。
2. 离散化:不改变数据相对大小的前提下,对数据进行相应的缩小。
利用离散化,降低空间复杂度。
例如:对25000,6600,10000,36000,770000离散化的结果为3,1,2,4,5;对22,33,1111,666777,88889999离散化的结果为1,2,3,4,5
3. 主席树代码常用到3个c++函数:unique,erase,lower_bound/upper_bound
(1) unique 函数示例代码如下:
#include <bits/stdc++.h>
using namespace std;
int main() {
int a[]= {10,20,30,30,20,10,10,20};
int len0=sizeof(a)/sizeof(a[0]); //求整型数组的长度
cout<<"数组去重前的元素个数:"<<len0<<endl;
cout<<"数组去重前的内容:";
for(int i=0; i<len0; i++) {
cout<<a[i]<<" ";
}
cout<<endl<<endl;
sort(a,a+len0); //必须先调用sort再调用unique
int len1=unique(a,a+len0)-a; //去重后的整型数组长度
cout<<"数组去重后的元素个数:"<<len1<<endl;
cout<<"数组去重后的内容:";
for(int i=0; i<len1; i++) {
cout<<a[i]<<" ";
}
return 0;
}
/*
数组去重前的元素个数:8
数组去重前的内容:10 20 30 30 20 10 10 20
数组去重后的元素个数:3
数组去重后的内容:10 20 30
*/
另一种实现可参考 https://www.cplusplus.com/reference/algorithm/unique/
(2) erase 函数示例代码如下:
#include <bits/stdc++.h>
using namespace std;
int main() {
int x;
vector<int> v; //因为是删除操作,所以必须用动态数组vector
while(cin>>x) {
v.push_back(x); //10 20 30 30 20 10 10 20
}
cout<<"删除前:";
for(int i=0; i<v.size(); i++) {
cout<<v[i]<<" ";
}
cout<<endl;
cout<<"删除后:";
//v.erase(v.begin()+2,v.end());
v.erase(v.begin()+2,v.begin()+6); //左闭右开[first,last),下标从0开始
for(int i=0; i<v.size(); i++) {
cout<<v[i]<<" ";
}
return 0;
}
/*
10 20 30 30 20 10 10 20
^Z
删除前:10 20 30 30 20 10 10 20
删除后:10 20 10 20
*/另一种实现可参考 https://www.cplusplus.com/reference/vector/vector/erase/
(3) lower_bound/upper_bound 函数示例代码如下:
#include <bits/stdc++.h>
using namespace std;
int main () {
int a[]= {10,20,30,30,20,10,10,20}; //排序后为 10 10 10 20 20 20 30 30
int len0=sizeof(a)/sizeof(a[0]); //求整型数组的长度
sort(a,a+len0); //必须先调用sort再调用lower_bound/upper_bound
int low=lower_bound(a,a+len0,20)-a; //返回数组中第1个大于等于20的数的下标(从0开始)
int up=upper_bound(a,a+len0,20)-a; //返回数组中第1个大于20的数的下标(从0开始)
cout<<"lower_bound at position "<<low<<endl;
cout<<"upper_bound at position "<<up<<endl;
return 0;
}
/*
lower_bound at position 3
upper_bound at position 6
*/另一种实现可参考 https://www.cplusplus.com/reference/algorithm/lower_bound/
【问题描述】
题目来源:
https://www.luogu.com.cn/problem/P3834
https://www.acwing.com/problem/content/description/257/
给定 n 个整数构成的序列 a,将对于指定的闭区间 [l,r] 查询其区间内的第 k 小值。
【输入格式】
第一行包含两个整数,分别表示序列的长度 n 和查询的个数 m。
第二行包含 n 个整数,第 i 个整数表示序列的第 i 个元素 a[i]。
接下来 m 行每行包含三个整数 l,r,k , 表示查询区间 [l, r] 内的第 k 小值。
【输出格式】
对于每次询问,输出一行一个整数表示答案。
【输入输出样例】
in:
5 5
25957 6405 15770 26287 26465
2 2 1
3 4 1
4 5 1
1 2 2
4 4 1
out:
6405
15770
26287
25957
26287
【数据规模与约定】
对于 100% 的数据,满足 1≤n,m≤2×10^5,∣ai∣≤10^9。
【算法代码】
#include <bits/stdc++.h>
using namespace std;
const int maxn=200005;
int cnt;
int a[maxn],root[maxn];
vector<int> v;
struct node {
int left;
int right;
int sum;
} hjt[maxn<<5];
//since the example requires subscripts to start at 1,
//so let the return value of lower_bound +1
int getid(int x) { //Discretization
return lower_bound(v.begin(),v.end(),x)-v.begin()+1;
}
//Note that cur is used with &cur, for it will change
void insert(int left,int right,int pre,int &cur,int val) {
hjt[++cnt]=hjt[pre]; //Assign position of the left and right subtrees to new segment tree
cur=cnt;
hjt[cur].sum++; //insert operation, total record +1
if(left==right) return;
int mid=left+right>>1;
if(val<=mid) insert(left,mid,hjt[pre].left,hjt[cur].left,val);
else insert(mid+1,right,hjt[pre].right,hjt[cur].right,val);
}
int query(int left,int right,int L,int R,int k) {
if(left==right) return left;
int mid=left+right>>1;
int t=hjt[hjt[R].left].sum-hjt[hjt[L].left].sum;
if(t>=k) return query(left,mid,hjt[L].left,hjt[R].left,k); //find kth smallest number in the left subtree
else return query(mid+1,right,hjt[L].right,hjt[R].right,k-t); //Otherwise go to the right subtree and look for (k-t)th smallest number
}
int main() {
int n,m;
while(cin>>n>>m) {
for(int i=1; i<=n; i++) { //start from index 1, echo getid()
cin>>a[i];
v.push_back(a[i]);
}
sort(v.begin(),v.end()); //v must be sorted before using unique()
v.erase(unique(v.begin(),v.end()),v.end()); //Keep the parts that don't repeat
for(int i=1; i<=n; i++) {
insert(1,n,root[i-1],root[i],getid(a[i]));
}
int x,y,k;
for(int i=0; i<m; i++) {
cin>>x>>y>>k;
cout<<v[query(1,n,root[x-1],root[y],k)-1]<<endl; //Prefix Sum
/*
The query function returns the index,
and it corresponds to the actual data stored in the vector[index-1]
*/
}
}
}
/*
in:
5 5
25957 6405 15770 26287 26465
2 2 1
3 4 1
4 5 1
1 2 2
4 4 1
out:
6405
15770
26287
25957
26287
*/
【参考文献】
https://blog.youkuaiyun.com/KnightHONG/article/details/101917861 https://www.cnblogs.com/LonecharmRiver/articles/9087536.html
https://www.cnblogs.com/mint-hexagram/p/15190020.html
https://www.cnblogs.com/kzj-pwq/p/9583099.html
https://www.pianshen.com/article/6126631942/
https://www.jianshu.com/p/e1d46a714fa8
https://blog.youkuaiyun.com/hnjzsyjyj/article/details/103425021 https://blog.youkuaiyun.com/hnjzsyjyj/article/details/103428414 https://blog.youkuaiyun.com/hnjzsyjyj/article/details/103428838 https://blog.youkuaiyun.com/hnjzsyjyj/article/details/103428971 https://blog.youkuaiyun.com/hnjzsyjyj/article/details/103429189 https://www.cnblogs.com/chenxiaoran666/p/ChairmanTree.html

















 2681
2681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









