 Pandas高效数据处理技巧
Pandas高效数据处理技巧





 本文详细介绍Pandas库中各种高效的数据处理技巧,包括CSV文件读取、数据筛选、列名获取、列合并、重复数据处理及表关联等,帮助读者掌握Pandas核心功能。
本文详细介绍Pandas库中各种高效的数据处理技巧,包括CSV文件读取、数据筛选、列名获取、列合并、重复数据处理及表关联等,帮助读者掌握Pandas核心功能。
pandas 使用上若干技巧
操作技巧
打开CSV文件
file = pd.read_csv(“your_file”)
打开普通文件
file = pd.read_table(“your_file”,sep="\t")
获取列名
DataFrame.columns.values.tolist()
个数统计
DataFrame[‘id’].value_counts()
使用列索引选取多列
DataFrame.iloc[:,your_col_index]
根据value选取指定列
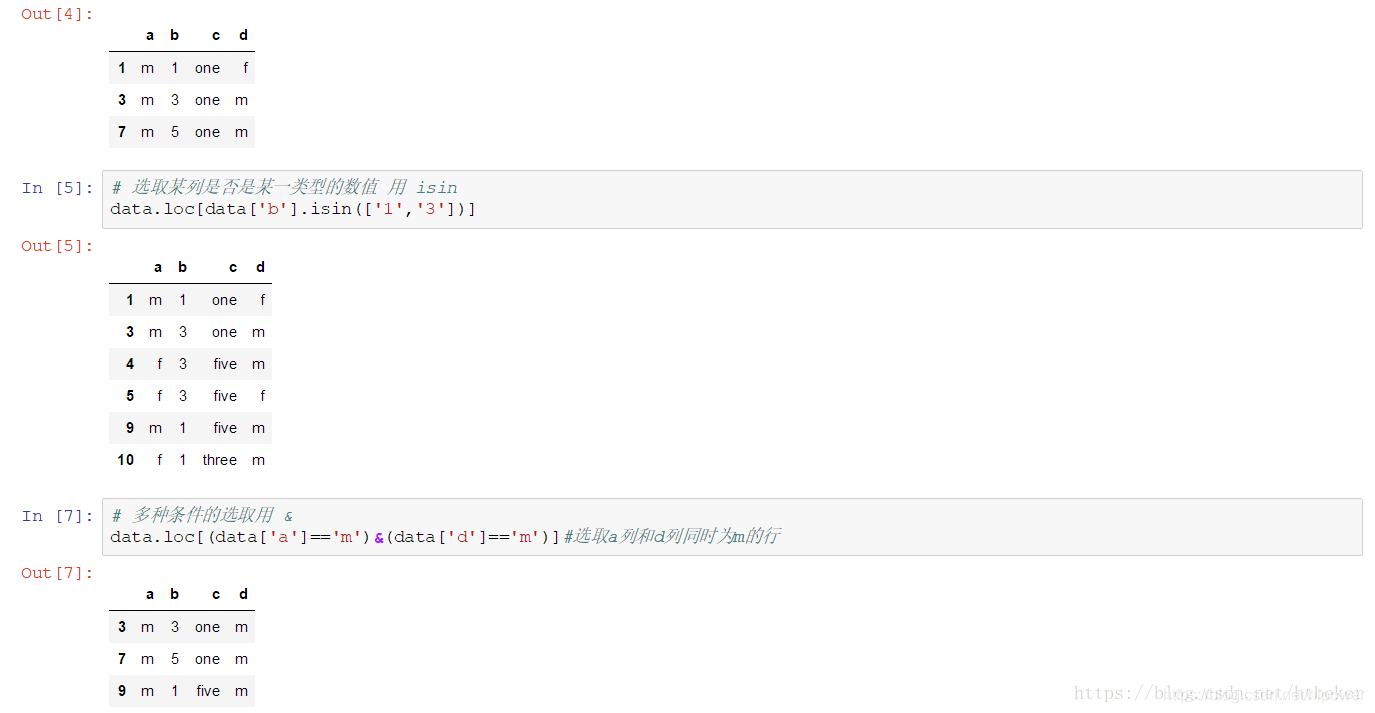
选取多列
DataFrame[[‘a’,‘b’]]
针对单独列做运算(如:格式转换)
file[‘app_version’] = file[‘app_version’].map(lambda x:str(x))
多列合并成一列
file[‘product_id’].str.cat(file[‘app_version’],sep="_")
去除重复列
DataFrame.drop_duplicates(subset=None, keep=‘first’, inplace=False)
这个drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行。返回DataFrame格式的数据。
- subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列 - keep : {‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项 - inplace : boolean, default False
是直接在原来数据上修改还是保留一个副本
pandas 根据key关联两张表
pandas 导出DataFrame到文件
DataFrame.to_csv(“des_file”)
group后作统计值
分块读取大文件
当文件过大无法单次读取到内存时,可以采用iterator进行多次读取:
reader = pd.read_csv(‘block_all.csv’,iterator=True)
reader.get_chunk(N)
示范代码
df_event = pd.read_csv("/workspace/share_dir/event_sequence.csv",iterator=True)
while True:
try:
chunk = df_event.get_chunk(10**4)
for index,row in chunk.iterrows():
your_process()
except StopIteration:
break

















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









