






Data dependency 发生在连续的指令的操作数,或循环指令的操作数之间。连续指令会在read after write(RAW),write after read(WAR),或者write after write(WAW)依赖。为了解决寄存器操作数或者memory访问之间的依赖,各种静态的、动态的、或者混合的技术都被引入。图1我们总结了目前已经才用的技术。
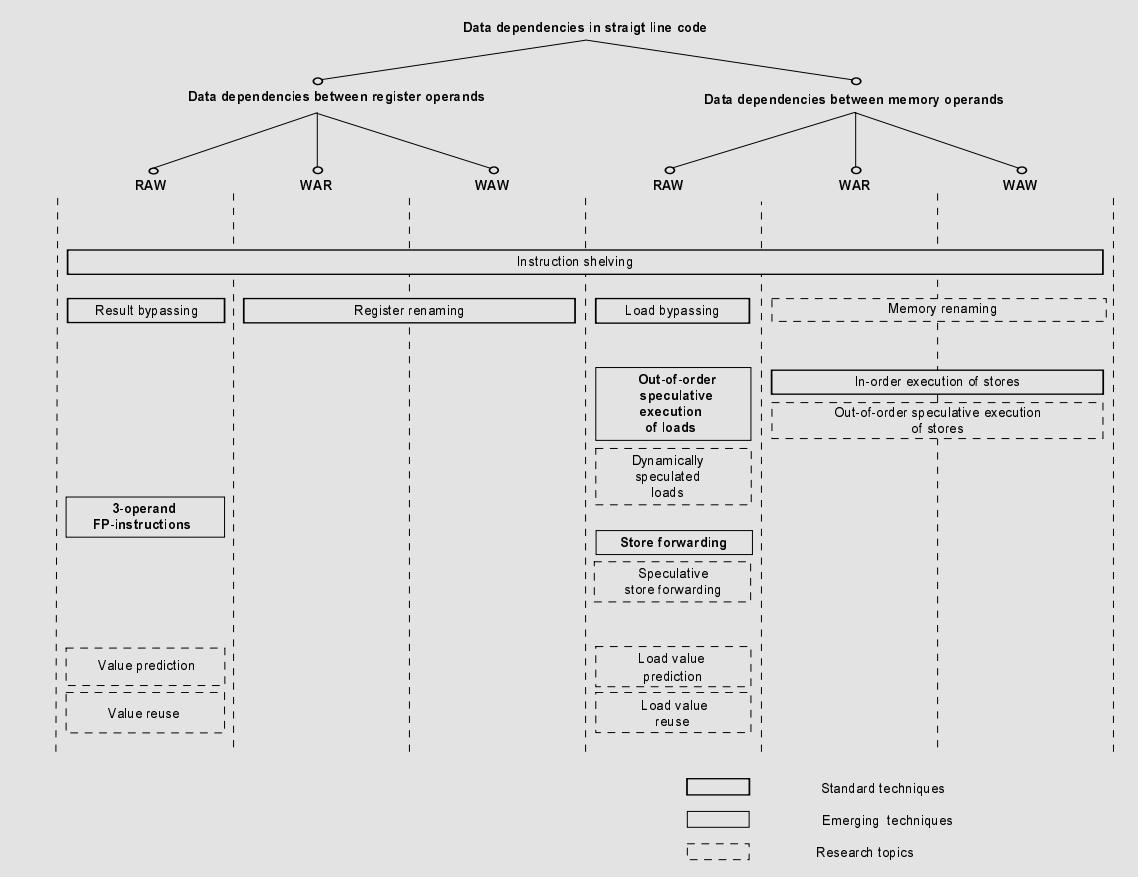
Instruction shelving(也被称作indirect issue或者dynamic instruction sheduling)解决了direct issue mode(可执行的指令被直接issue到执行单元)中会遇到的issue bottleneck的问题。direct issue mode中,所有的data和控制依赖以及对执行单元的争抢都会阻塞指令的发射。
在Instruction shevling中,指令先被发射到shelves,基本上不进行dependency的检查。然后在一个称为dispatch的单独的步骤中,检查依赖,然后forward指令到free execution 单元。本文后面的dispatch与issue同义。
接下来我们重点关注解决register operand存在的数据依赖。
寄存器重命名是广泛采用的技术,来移除straight-line code中出现数据依赖(WAR和WAW)的技术。在后面的章节中我们会详细的介绍各种各样实现寄存器重命名的技术。
如果我们通过寄存器重命名移除了假数据依赖,通过分支预测移除了控制依赖,那么只有RAW依赖可以限制我们并行执行指令。此时,处理器执行shelves中hold的指令,换句话说即dispatch window中的指令。这意味着采用renaming 和 speculative branch processing之后,基本上只有producer-consumer关系会限制顺序依赖,并且成为并行执行的hard limit,称为 dataflow limit。接下来我们介绍用来解决dataflow limit的两种已经被广泛采用的技术和两种正在研究中的技术:
Result bypassing现在已经是一个标准的技术,来减少指令之间的RAW导致的阻碍。Result bypassing意味着将从执行单元产生的结果直接forward到需要它们的输入端口,省去了producer-consumer链路中的寄存器写→读操作。
Three-operand floating point instruction移除了原来使用两操作数,在计算点乘操作(A*B+C)时存在的RAW依赖。单操作数允许立即计算点乘,而不需要导致任何的RAW依赖。
为了超越dataflow limit,最近两种技术成为研究的重点(1)value prediction (2) value resuse.
value prediction (data value speculation)会根据指令的指令历史,猜测指令的结果。如果是可以预测的,那么指令可能会利用预测的结果继续执行,同时也会计算真实的结果。一旦producer执行完毕,处理器会检测预测的结果是狗正确。如果正确,则使计算有效。否则,会发起recovery,并利用正确的结果继续指令。
value reuse,指令通过移除重复的复杂计算(比如除法和开方运算)来减轻RAW的依赖。其基本的思想如下,处理器会存储复杂指令的相关成员(操作数,操作和结果)在operation cache(dynamic look up table)中。因此在之前执行过的计算会保存结果在operation cache中。如果又有新的复杂指令进入,那么处理器就会检查之前是否进行过同样的计算。如是,那么处理器会重新使用之前operation cache中保存的值,而不是重新计算一次。
现在我们再讨论memory operand. 我们将讨论限制在load/store architecture。 这也是基于事实,即使是CISC架构的处理器内部也是采用了CISC/RISC 转换。假想load/store 架构,只有load和store指令可以访问memory,所以memory data dependency可以限制在load和store指令。如果他们访问同一个memory地址,那么就会产生dependency。除了shelving, 下面的技术被采用来解决memory data dependency。
WAR 和 WAW memory dependency会在顺序执行store的时候遇到。在我们讨论的case中,store instruction的结果按照program order被写入到memory,因此不存在WAR和WAW dependency。
另一方面,我们采用三种主要的技术来解决RAW依赖:1)load bypassing 2) load乱序执行(这实际上包括多种技术) 3)通过进行load value prediction或者load value reuse来避免memory的RAW依赖。
1) load bypassing是一种用来减少load-use latency的标准方法,load和后续的操作数指令可以直接使用load fetch到的value。这是通过将fetch value直接forward到请求的执行单元来实现。用这个方法,load-use latency减少了将fetch到的数值先写入目标寄存器,然后从目标寄存器读取的时间。
2)out of order execution of load意味着load可以bypass older的load和store。这个feature对于想要快速获取数据或者是想要减少因为cache miss导致的性能下降的情况十分需要。然而乱序执行的load希望处理器可以检查那些比older store执行的更早的load,是否和previous pending store地址冲突。然而在进行地址检查时,可能store的地址还没有被产生。在早期的超标量处理器比如motorola MC 88110,如果有地址还没有被计算出来,那么就暂停load指令的执行。这种straightforward out of order execution of loads不再被使用。最近的处理器通过使用out of order speculative load避免了上述的blocking。这种技术积极的猜测没有发生地址冲突,让load继续执行。在后面知道了store的地址时,处理器再检测冲突,如果确实需要的话,激活recovery mechanism并重新启动load的执行。
Speculative load可以在以下三个方向上加强:
(a) 不像上述的处理器一样盲目的每次都进行speculative load。而是进行dymaic speculative load,通过进行基于执行历史的预测,来检查是否speculative load是可以的。这个方法有效的减少了错误执行的speculative load。
(b) 通过检查load和store的地址冲突,value可以直接立刻的被forwarded到load指令,这个技术即为store forward。减少了load access latency
©通过tracing load和它所依赖的previous store的距离。speculative store fowarding也是可行的
(iii)最后一种解决memory RAW依赖的方法就是使用load value prediction或者load value reuse。这些技术与value prediction和value reuse类似。
考虑到WAR和WAW dependency,我们只出了两种进一步的研究方向:
(i) 通过引入memory renaming来移除WAR和WAW dependency
(ii) 通过ouf of order store来减少WAR和WAW dependency的阻碍
【论文导读】 The Design Space of Register Renaming (一)
最新推荐文章于 2024-06-04 13:37:55 发布
部署运行你感兴趣的模型镜像
欢迎关注我的公众号《处理器与AI芯片》
您可能感兴趣的与本文相关的镜像

ACE-Step
音乐合成
ACE-Step
ACE-Step是由中国团队阶跃星辰(StepFun)与ACE Studio联手打造的开源音乐生成模型。 它拥有3.5B参数量,支持快速高质量生成、强可控性和易于拓展的特点。 最厉害的是,它可以生成多种语言的歌曲,包括但不限于中文、英文、日文等19种语言

















 2927
2927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









