




 Apple发布的新文章介绍了一种名为LLMinaFlash的方法,通过在FlashMemory中有效管理和加载大模型的稀疏参数,尤其是利用FeedForward层的稀疏性和SlidingWindow技术,显著减少了DRAM中的内存需求,提高计算效率。
Apple发布的新文章介绍了一种名为LLMinaFlash的方法,通过在FlashMemory中有效管理和加载大模型的稀疏参数,尤其是利用FeedForward层的稀疏性和SlidingWindow技术,显著减少了DRAM中的内存需求,提高计算效率。

Apple最近发表了一篇文章,可以在iphone, MAC 上运行大模型:【LLM in a flash: Efficient Large Language Model Inference with Limited Memory】。
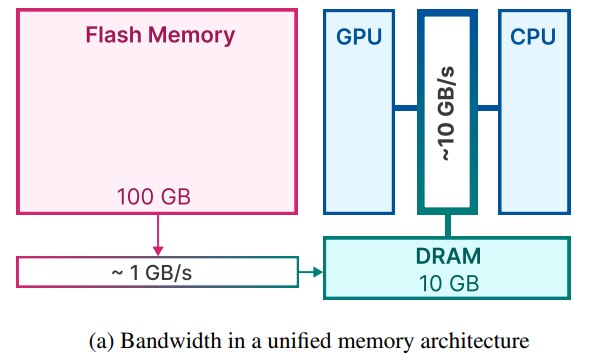
主要解决的问题是在DRAM中无法存放完整的模型和计算,但是Flash Memory可以存放完整的模型。但是Flash带宽较低,LLM in Flash通过尽量减少从Flash中加载参数的数量,优化在DRAM中的内存管理,实现在Flash带宽有限的条件下提高计算速度的目的。
这篇文章很多都是工程上的细节,很少理论。下面是这篇论文的总结,如有不对的地方,欢迎私信。
-
利用FeedForward 层的稀疏度,只加载FeedForward层输入非0和预测输出非0的参数
-
通过Window Sliding 只加载增量的参数,复用之前的计算,减少需要加载的参数。
-
将up-projection的row和down-projection的column放在一起存放,这样在flash中可以一次读取比较大的chunk,提高flash的带宽利用效率。
如下图所示,chunk越大,带宽也就越大,初始加载chunk的latency可以被平摊。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









