




 本文详细介绍了Python中数据拼接的方法,包括List的append和extend,DataFrame的非条件拼接(append、concat)和条件拼接(merge、join),以及Array的numpy.append、numpy.concatenate、numpy.stack、numpy.vstack、numpy.hstack、numpy.dstack、numpy.c_和numpy.r_的使用。文章旨在帮助读者清晰理解各种数据拼接方式及其适用场景。
本文详细介绍了Python中数据拼接的方法,包括List的append和extend,DataFrame的非条件拼接(append、concat)和条件拼接(merge、join),以及Array的numpy.append、numpy.concatenate、numpy.stack、numpy.vstack、numpy.hstack、numpy.dstack、numpy.c_和numpy.r_的使用。文章旨在帮助读者清晰理解各种数据拼接方式及其适用场景。
使用python进行数据处理,常免不了做数据拼接。可是因为常用的数据容器类型不少,有List,array,DataFrame等,时不时搞混(根本原因是以前偷懒一直没用心去记-_-’)。终于痛定思痛,决定好好整理记录下来,并养成好习惯。。。
以下按照不同数据容器类型,整理出了可用的数据拼接方法。
(一) List
python为列表提供的拼接方法,首先是append和extend。其中append是把参数整个作为元素回到原列表的末尾作为一个元素,而extend则是把参数列表的所有元素作为原列表的新元素追加到末尾。另外有一点需注意的是,append和extend调用的结果是直接修改原列表,无返回值。 例子如下:

除此以外,python中的+和+=操作符,作用在列表上,也具有拼接的功能。其中,+=的实现的功能和extend一样,而+则和extend略有不同:其返回的是一个新列表,而非原列表。例子如下:

(二) DataFrame
DataFrame提供的拼接功能要更为丰富一些。大抵可以概括为非条件拼接和条件拼接两种(非条件拼接和条件拼接是我为了便于理解记忆自己杜纂的,因此莫问出处)。
1. 非条件拼接
非条件拼接包括append和concat。
(1) append
append实现的功能和List的+功能类似,即执行结果是返回一个新的DataFrame,且不改变原DataFrame。
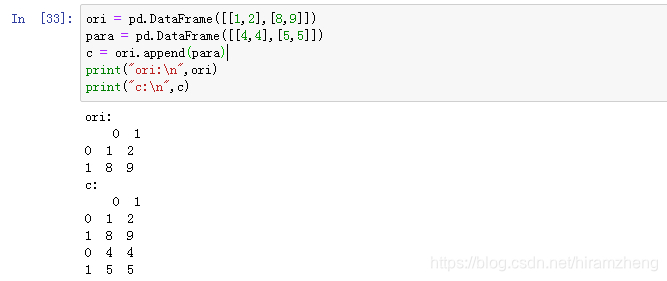
此外,DataFrame合并涉及到index的处理:置ignore_index=True(默认False)可以无视原index并在合并后新建index;相反的,置verify_integrity=True(默认False)则可以使得合并遇到重复index时报错。
(2) pandas.concat
concat比append灵活,因为concat既可在行方向扩展,也可在列方向扩展。控制扩展方向的参数为axis(默认为0)。
此外,对于拼接的DataFrame行列没能对齐的情况,concat通过参数join提供了两种拼接方法outer(默认)和 inner。前者将使用NaN填充空缺的数据域,后者则将所有有空缺的数据域(行和列)删除。
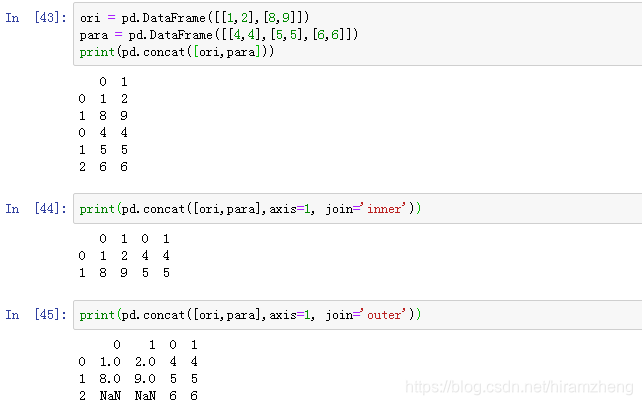
concat也有ignore_index和verify_integrity参数。
2. 条件拼接
之所以叫它条件拼接,是因为它需要按某个指定的条件进行拼接,实现的效果很象SQL的表关联查询。
条件拼接有merge和join,前者是pandas的方法,后者是DataFrame的方法。
(1) pandas.merge
需要指定关联的列,使用on指定。关联列不只一个列的,使用列表方式on=[colName1, colName2,…]。关联的方式,和SQL差不多,默认为inner,可选left,right,outer。

方法merge参数较多,更详细的用,可到pandas官网查看:http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html?highlight=merge#pandas.DataFrame.merge
(2) join
join也需要指定关联的列。需要特别注意的一点是,其关联的方式默认为left而不是inner,这一点有别于merge,需要特别注意。
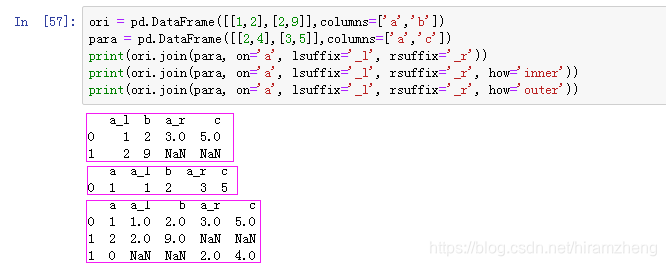
方法join参数较多,更详细的用法,可到pandas官网查看:http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.join.html#pandas.DataFrame.join
(三) array
numpy的数组合并方法很多(其实感觉有点多过头了……)。
1. numpy.append
append方法的参数比较少,关于参数,有两点需要注意:
(1)参数axis的值和选取,如何与对数组进行拼接的维度进行对应;
(2)确保进行拼接的两个数组,除了进行拼接的维度以外,其他维的长度都是相同的。
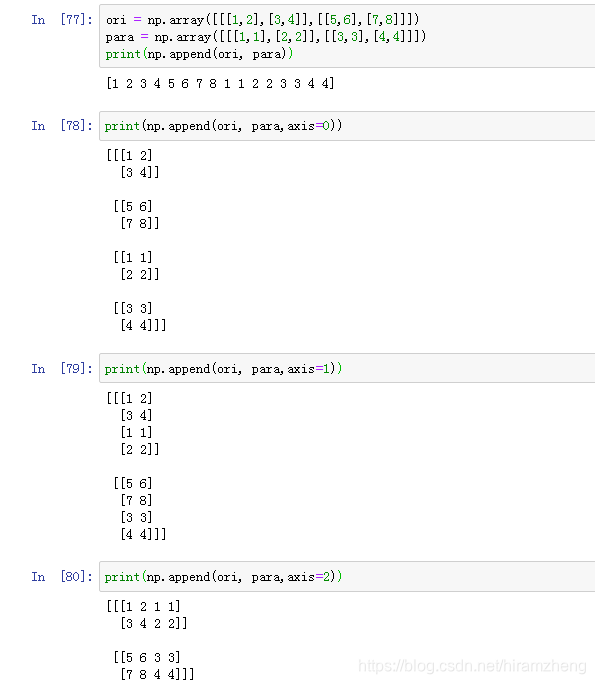
当数据量很大时,使用append方式会很慢,因为每次都会把之前的数组复制给一个新的数组。
另外,append返回的数组,其维数将和原数组一致。无法通过append方法拼接出更高维的数组。
2. numpy.concatenate
concatenate的使用方法及调用结果和append差不多,唯一不同的,是concatenate的axis默认值为0.

concatenate的效率高于append,这种优势在大数据量情况下更加明显。
3. numpy.stack
stack用于矩阵堆叠,在参与堆叠的矩阵多于一个时,堆叠结果将必然增加一个维度。参数axis用于控制在哪两个维度之间增加新维度。
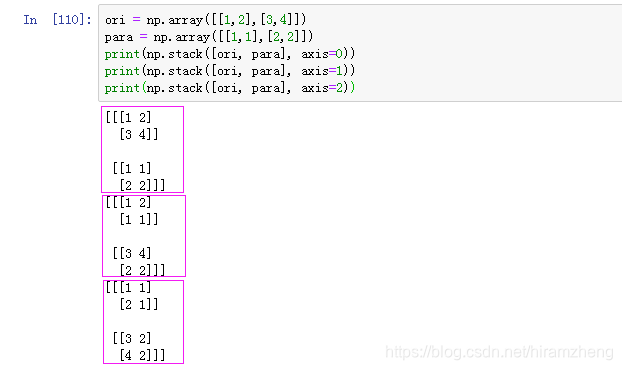
4. numpy.vstack & numpy.hstack & dstack
vstack是沿着第一个维度进行拼接,相当于concatenate取axis=0;hstack是沿着第二个维度进行拼接,相当于concatenate取axis=1;dstack是沿着第三个维度进行拼接,相当于concatenate取axis=2.
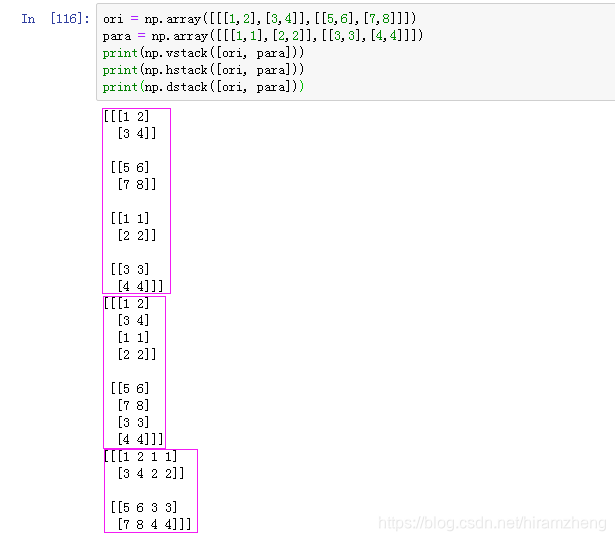
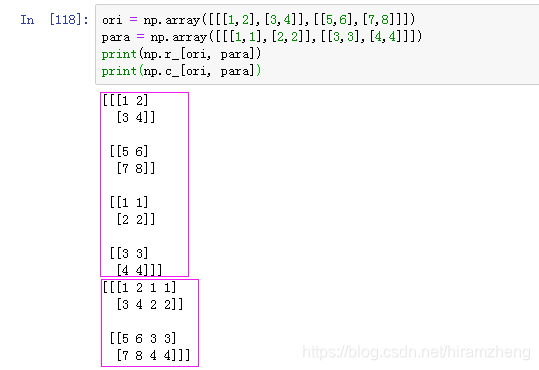
5. numpy.c_ & numpy.r_
r_效果同vstack,c_效果则和hstack相同,但调用方法略有不同。r_和c_并不是函数的方法,因此不使用括号,而是使用方括号。
另外看到网上有人有人说r_和c_的性能和vstack等并不相同,但没找到详细说明,因此先Mark着,以后再补充。


















 2902
2902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









