




 文章探讨了Flink为何需要自主管理内存,特别是针对大数据处理中JVM内存管理的问题,如低效的Java对象存储、FullGC性能下降和频繁的OutOfMemoryError。Flink通过MemorySegment实现内存集中管理和高效操作,减少垃圾收集压力,提供内存剩余监控和溢写磁盘机制,以提升系统性能和稳定性。
文章探讨了Flink为何需要自主管理内存,特别是针对大数据处理中JVM内存管理的问题,如低效的Java对象存储、FullGC性能下降和频繁的OutOfMemoryError。Flink通过MemorySegment实现内存集中管理和高效操作,减少垃圾收集压力,提供内存剩余监控和溢写磁盘机制,以提升系统性能和稳定性。
文章目录
本节从整体使用的角度了解Flink如何实现对内存的积极管理,然后对比基于JVM带来的内存管理问题,介绍Flink如何抽象出合理内存模型,解决大规模场景下的内存使用问题。
一.flink为什么自己管理内存
1. 处理大数据时JVM内存管理的问题
在JVM上运行的系统,需要将数据存储到JVM堆内存中进行处理和运算,借助JVM提供的GC能力能够实现内存的自动管理,但对于大数据处理场景而言,需要处理非常庞大的数据,此时JVM内存管理的问题会比较突出,主要体现在以下几点。
- Java对象存储密度相对较低:对于常用的数据类型,例如Boolean类型数据占16字节内存空间,其中对象头占字节,Boolean属性仅占1字节,其余7字节做对齐填充。而实际上仅1字节就能够代表Boolean值,这种情况造成了比较严重的内存空间浪费。
- Full GC极大影响系统性能:使用JVM的垃圾回收机制对内存进行回收,在大数据量的情况下GC的性能会比较差,尤其对于大数据处理,有些数据对象处理完希望立即释放内存空间,但如果借助JVM GC自动回收,通常情况下会有秒级甚至分钟级别的延迟,这对系统的性能造成了非常大的影响。
- OutOfMemoryError问题频发,严重影响系统稳定性:系统出现对象大小分配超过JVM内存限制时,就会触发OutOfMemoryError,导致JVM宕机,影响整个数据处理进程。
2. flink主动管理内存逻辑
积极地内存管理,强调的是主动对内存资源进行管理。
2.1. Flink内存管理方面
对Flink内存管理来讲,主要是
- 将本来直接存储在堆内存上的数据对象,通过数据序列化处理,存储在预先分配的内存块上,该内存块也叫作MemorySegment,代表了固定长度的内存范围,默认大小为32KB,同时MemorySegment也是Flink的最小内存分配单元。
- MemorySegment将JVM堆内存和堆外内存进行**集中管理,形成统一的内存访问视图。**MemorySegment提供了非常高效的内存读写方法,例如getChar()、putChar()等。
- 如果MemorySegment底层使用的是JVM堆内存,数据通常会被存储至普通的字节数据(byte[])中,如果MemorySegment底层使用的是堆外内存,则会借助ByteBuffer数据结构存储数据元素。
- 基于MemorySegment内存块可以帮助Flink将数据处理对象尽可能连续地存储到内存中,且所有的数据对象都会序列化成二进制的数据格式,对一些**DBMS风格(关系型数据库)**的排序和连接算法来讲,这样能够将数据序列化和反序列化开销降到最低。
2.2. 序列化、反序列化说明
如图,对于用户编写的自定义数据对象,例如Person(String name, int age),会通过高效的序列化工具将数据序列化成二进制数据格式,然后将二进制数据直接写入事先申请的内存块(MemorySegment)中,当再次需要获取数据的时候,通过反序列化工具将二进制数据格式转换成自定义对象。
整个过程涉及的序列化和反序列化工具都已经在Flink内部实现,当然,Flink也可以使用其他的序列化工具,例如KryoSerializer等。
OOM情况的处理
我们也可以看到,在MemorySegment中如果因为内存空间不足,无法申请到更多的内存区域来存储对象时,Flink会将MemorySegment中的数据溢写到本地文件系统(SSD/Hdd)中。当再次需要操作数据时,会直接从磁盘中读取数据,保证系统不会因为内存不足而导致OOM(Out Of Memory,超出内存空间),影响整个系统的稳定运行。
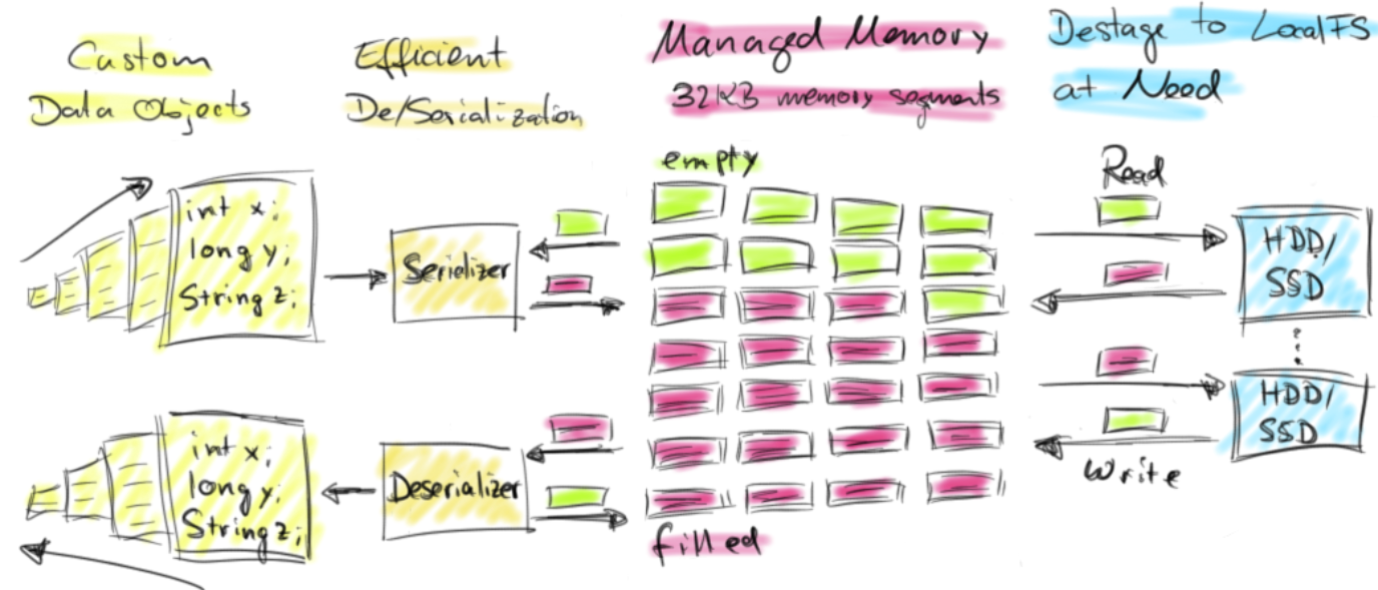
3. Flink主动管理内存的好处
- 内存剩余监控简单:因为分配的内存段数量是固定的,所以监控剩余的内存资源非常简单。在内存不足的情况下,处理操作符可以有效地将更大批的内存段写入磁盘,然后再将它们读回内存。这样就可以有效防止OOM问题。
- 减低垃圾收集压力:在Flink中,所有长生命周期的数据都是以二进制形式管理内存的,所有创建的数据对象都是短暂且可变的,并且支持重用。短生命周期的对象可以更有效地进行垃圾收集,这大大降低了垃圾收集的压力。为了降低垃圾收集的压力,Flink社区实现了将数据对象分配到堆外内存,使得JVM堆变得更小,垃圾收集消耗的时间更短。
- 数据对象以二进制的形式存储,可以节省大量存储Java对象需要的存储开销。
- 更高效的缓存访问模式:通过二进制形式存储数据对象,框架可以有效地比较和操作二进制数据。(ing)此外,用二进制表示数据可以将相关值、哈希码、键和指针等信息存储在相邻的内存中。(ing)这使得数据结构通常具有更高效的缓存访问模式。
二. Flink内存模型
1. 堆内存
在Flink中将JVM堆内存分为Framework堆内存和Task堆内存两种类型,其中
- Framework堆内存主要用于Flink框架本身需要的内存空间,
- Task堆内存则用于Flink算子及用户代码的执行,两者主要的区别在于是否将内存计入Slot计算资源中。
- Framework堆内存和Task堆内存之间没有做明确的隔离,在后续版本中会做进一步优化。
2. 非堆内存
对于非堆内存,则主要包含了托管内存、直接内存以及JVM特定内存三部分。
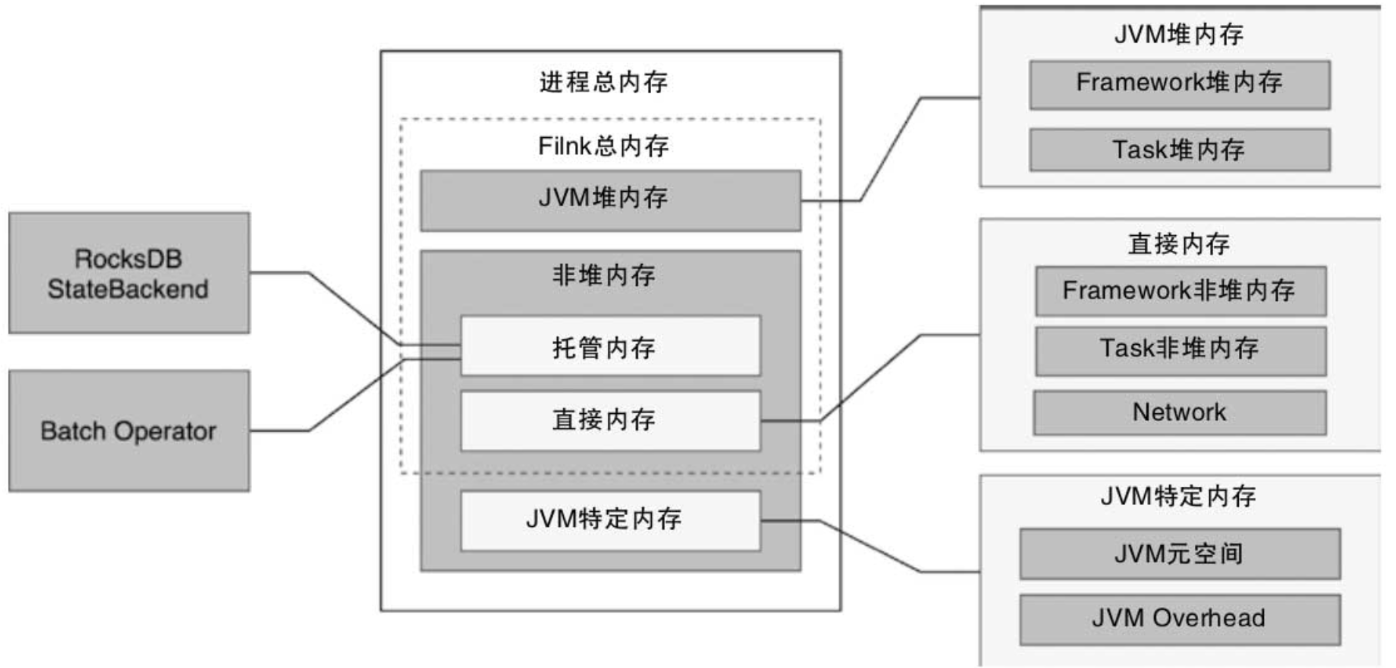
2.1. 托管内存
托管内存是由Flink负责分配和管理的本地(堆外)内存,
在流处理作业中用于RocksDBStateBackend状态存储后端
在批处理作业中用于排序、哈希表及缓存中间结果
2.2.直接内存
直接内存分为Framework非堆内存、Task非堆内存和Network三个部分,
- 其中Framework非堆内存和Task非堆内存主要根据堆外内存是否计入Slot资源进行区分,堆外内存没有对Framework和Task之间进行隔离。
- Network内存存储空间主要用于基于Netty进行网络数据交换时,以NetworkBuffer的形式进行数据传输的本地缓冲。
2.3. JVM特定内存
JVM特定内存不在Flink总内存范围之内,包括JVM元空间和JVM Overhead,其中JVM元空间存储了JVM加载类的元数据,加载的类越多,需要的内存空间越大,JVM Overhead则主要用于其他JVM开销,例如代码缓存、线程栈等。
对于Flink来讲,将内存划分成不同的区域,实现了更加精准地内存控制,并且可以通过MemorySegment内存块的形式申请和管理内存,我们继续了解MemorySegment内存块的设计与实现。
参考:《Flink设计与实现:核心原理与源码解析》



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











