






介绍
Flink 作为一个基于内存的分布式计算引擎,其内存管理模块很大程度上决定了系统的效率和稳定性,尤其对于实时流式计算,JVM GC 带来的微小延迟也有可能被业务感知到。
针对这个问题,Flink 实现了一套较为优雅的内存管理机制,可以在引入小量访问成本的情况下提高内存的使用效率并显著降低 GC 成本和 OOM 风险,令用户可以通过少量的简单配置即可建立一个健壮的数据处理系统。
一、Flink内存结构分析
Flink进程一般称为TaskManager,即一个JVM进程作为Master/Slave 架构中的 Slave 提供了作业执行需要的环境和资源。
Flink在 JVM 堆内或堆外实现显式的内存管理,即用自定义内存池来进行内存块的分配和回收,并将对象序列化后存储到内存块,同时支持 on-heap 和 off-heap。
import org.apache.flink.configuration.MemorySize;
import java.io.Serializable;
/**
* Memory components which constitute the Total Flink Memory.
*
* <p>The relationships of Flink JVM and rest memory components are shown below.
*
* <pre>
* ┌ ─ ─ Total Flink Memory - ─ ─ ┐
* ┌───────────────────────────┐
* | │ JVM Heap Memory │ |
* └───────────────────────────┘
* |┌ ─ ─ - - - Off-Heap - - ─ ─ ┐|
* │┌───────────────────────────┐│
* │ │ JVM Direct Memory │ │
* │└───────────────────────────┘│
* │ ┌───────────────────────────┐ │
* ││ Rest Off-Heap Memory ││
* │ └───────────────────────────┘ │
* └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
* └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
* </pre>
*
* <p>The JVM and rest memory components can consist of further concrete Flink memory components
* depending on the process type. The Flink memory components can be derived from either its total
* size or a subset of configured required fine-grained components. Check the implementations for
* details about the concrete components.
*/
public interface FlinkMemory extends Serializable {
MemorySize getJvmHeapMemorySize();
MemorySize getJvmDirectMemorySize();
MemorySize getTotalFlinkMemorySize();
} |
TaskManager 主要由几个内部组件构成:
负责和 JobManager 等进程通信的 actor 系统,负责在内存不足时将数据溢写到磁盘和读回的 IOManager,还有负责内存管理的 MemoryManager。
其中 actor 系统和 MemoryManager 会要求大量的内存。相应地,Flink 将 TaskManager 的运行时 JVM heap 分为 Network Buffers、MemoryManager 和 Free 三个区域
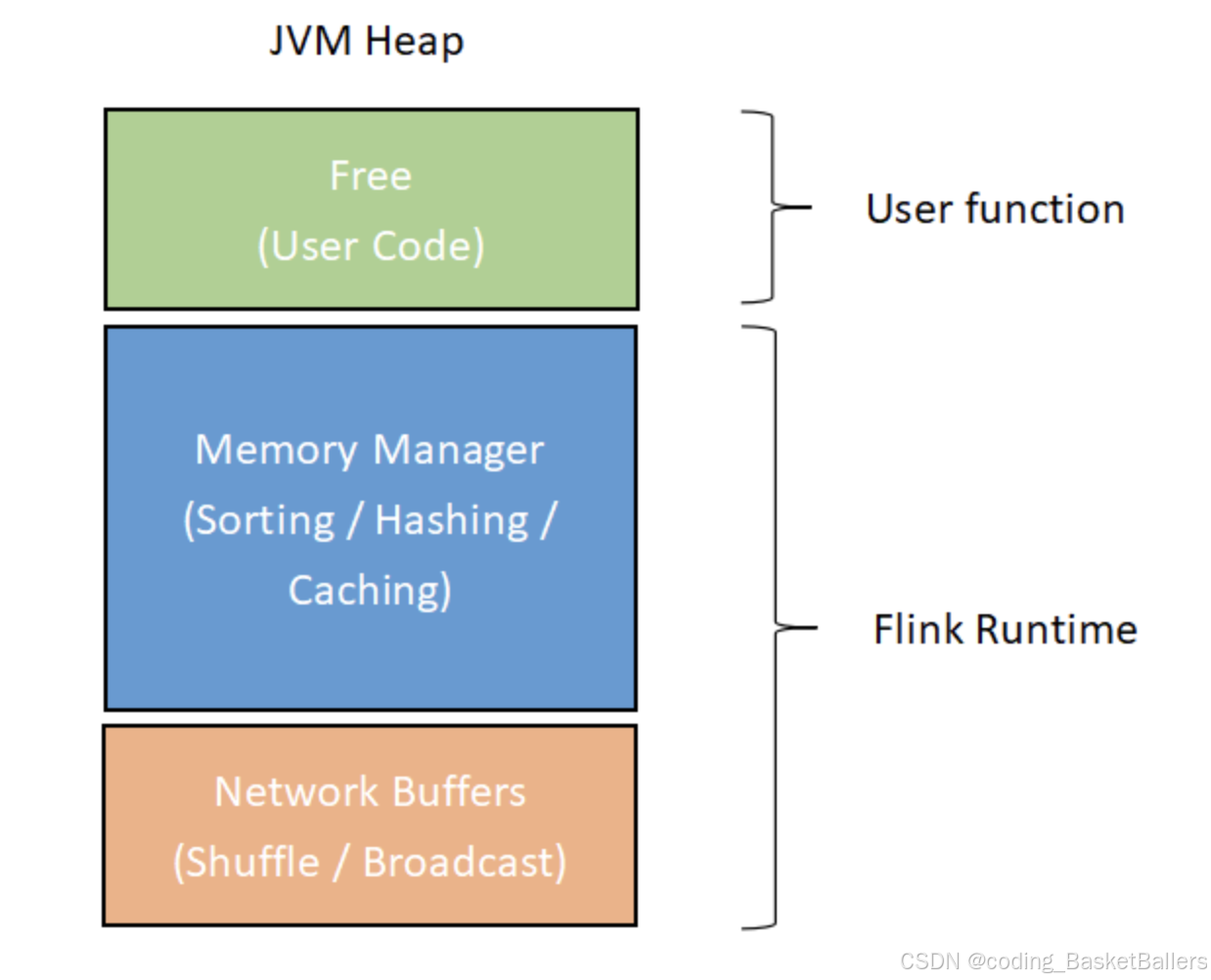
- Network Buffers 区: 网络模块用于网络传输的一组缓存块对象,单个缓存块对象默认是32KB大小。Flink 会根据 TaskManager 的最大内存来计算该区大小,默认范围是64MB至1GB。
- Memory Manager 区: 用于为算子缓存运行时消息记录的大缓存池(比如 Sort、Join 这类耗费大量内存的操作),消息记录会被序列化之后存进这些缓存块对象。这部分区域默认占最大 heap 内存减去 Network Buffers 后的70%,单个缓存块同样默认是32KB。
- Free 区: 除去上述两个区域的内存剩余部分便是 Free heap,这个区域用于存放用户代码所产生的数据结构,比如用户定义的 State.
二、Flink的内存管理
Memory Segment
Memory Segment 是 Flink 内存管理的核心概念,是在 JVM 内存上的进一步抽象(包括 on-heap 和 off-heap),代表了 Flink Managed Memory 分配的单元。
每个 Memory Segment 默认占32KB,支持存储和访问不同类型的数据,包括 long、int、byte、数组等。你可以将 Memory Segment 想象为 Flink 版本的 java.nio.ByteBuffer。
MemoryManager中的
private final Map<Object, Set<MemorySegment>> allocatedSegments; 内存分配map,key是申请内存的具体对象,一般是Task算子,value就是他申请的内存块
不管消息数据实际存储在 on-heap 还在是 off-heap,Flink 都会将它序列化成为一个或多个的 Memory Segment(内部又称 page,多个块认为是一页内存,跟系统中的内存分页是对应的)。
消息数据是Flink自己实现的序列化与反序列化机制实现的,然后存储在MemorySegment里,溢出的部分会写到磁盘上
三、对GC的影响
Flink 不会将消息记录当作对象直接放到 heap 上,而是序列化后存在长期缓存对象里。
这意味着将不会出现低效的短期对象,消息对象只用来在用户函数内传递和被序列化。
而长期对象是 MemorySegment 本身,它们并不会被 GC 清理。
因此在 JVM 内存结构规划上,Flink 也作了相应的调整: MemoryManager 和 Network Buffers 两个实现了显式内存管理的子系统分配到老年代,而留给用户代码的 Free 区域分配到新生代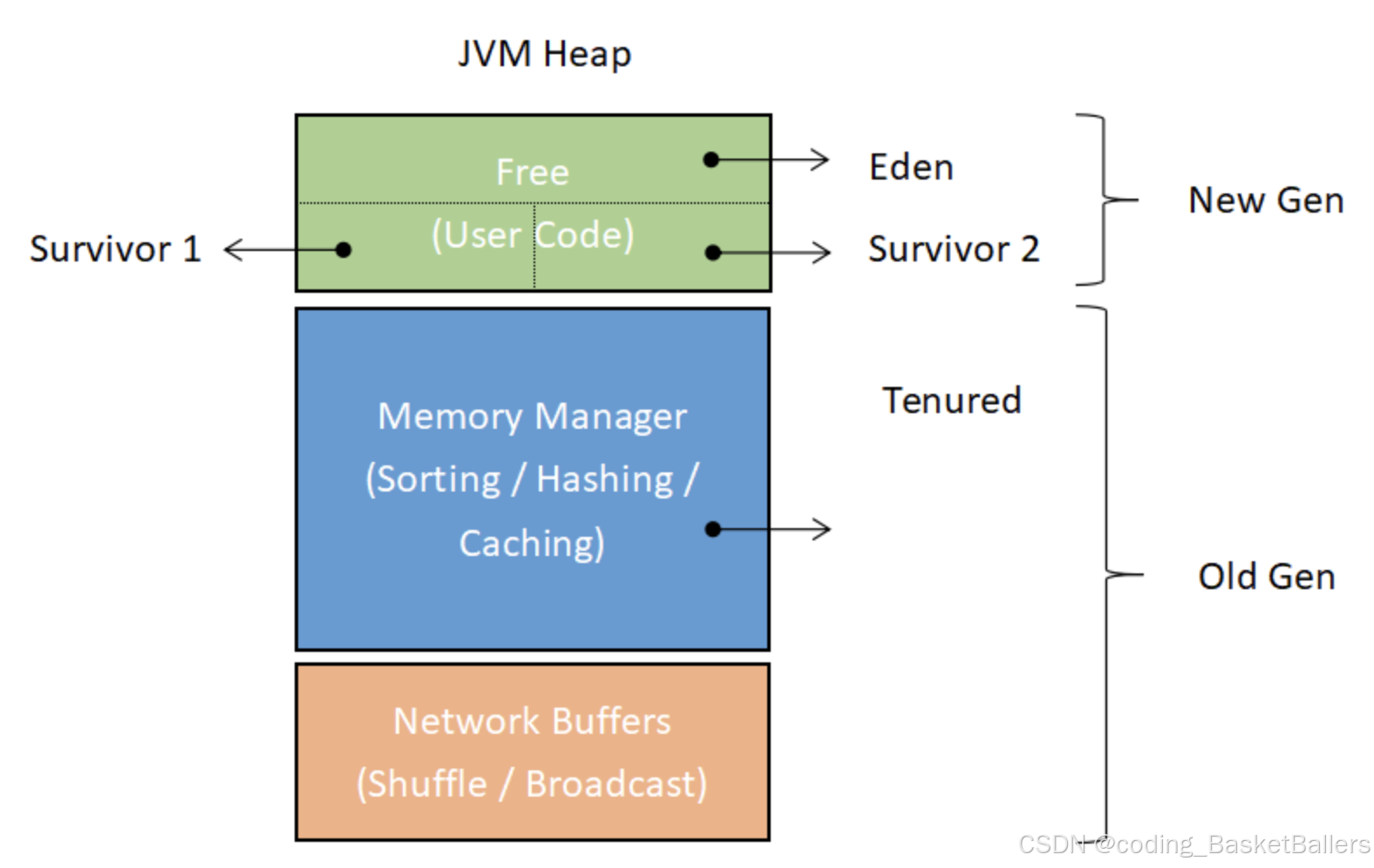
为了证明 Flink 内存管理和序列化器的优势,Flink 官方对 Object-on-Heap (直接 Java 对象存储)、Flink-Serialized (内建序列化器 + 显式内存管理)和 Kryo-Serialized (Kryo 序列化器(google的开源) + 显式内存管理)三种方案进行了 GC 表现的对比测试。
显而易见,使用显式内存管理可以显著地减少 GC 频率。在 Object-on-Heap 的测试中,GC 频繁地被触发并导致 CPU 峰值达到90%。

在测试中使用的8核机器上单线程的作业最多只占用12.5%的 CPU ,机器花费在 GC 的成本显然超过了实际运行作业的成本。
而在另外两个依赖显式内存管理和序列化的测试中,GC 很少被触发,CPU 使用率也一直稳定在较低的水平


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









