




前言:上篇文章我们学习了指针相关知识,这篇博客来做一些题目,巩固加深对指针的理解。
详情请看这一篇文章 学了3200遍才略有所懂的C语言指针-优快云博客
———— 道阻且长,行则将至
1.sizoef和strlen的对比
在正式做题目之前我们先来学习两个非常基础的但极其重要的知识点:sizeof和strlen。这两者虽然都和指针计算相关,但它们的计算方式和应用场景却有很大区别,理解它们的差异对后续编程非常重要。
1.1sizeof的简介
sizeof是一个操作符,而并非一个函数,这是一个在编译时计算的运算符,主要用于计算变量或者数据类型的内存空间大小,单位是字节。
#include <stdio.h>
//在x64环境下计算的结果
int main()
{
int a = 10;
printf("%d\n", sizeof(a));
printf("%d\n", sizeof a);
printf("%d\n", sizeof(int));
return 0;
}
这段代码清晰的展现了,sizeof是一个操作数,而并非一个函数,它不需要用函数名(实参)的方式就能进行使用。
1.2.strlen的简介
strlen是一个库函数,需要通过包含<string.h>头文件,用于计算字符串的实际长度,遇到'\0'就停止计算,(直到找到为⽌,所以可能存在越界查找),不会计算'\0',也就是说计算的是'\0'之前的字符串长度,另外注意一下strlen返回的是无符号整形。
函数头:
size_t strlen ( const char * str );
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[3] = {'a', 'b', 'c'};
char arr2[] = "abc";
printf("%d\n", strlen(arr1)); //打印出随机值
printf("%d\n", strlen(arr2));
printf("%d\n", sizeof(arr1));
printf("%d\n", sizeof(arr2));
return 0;
}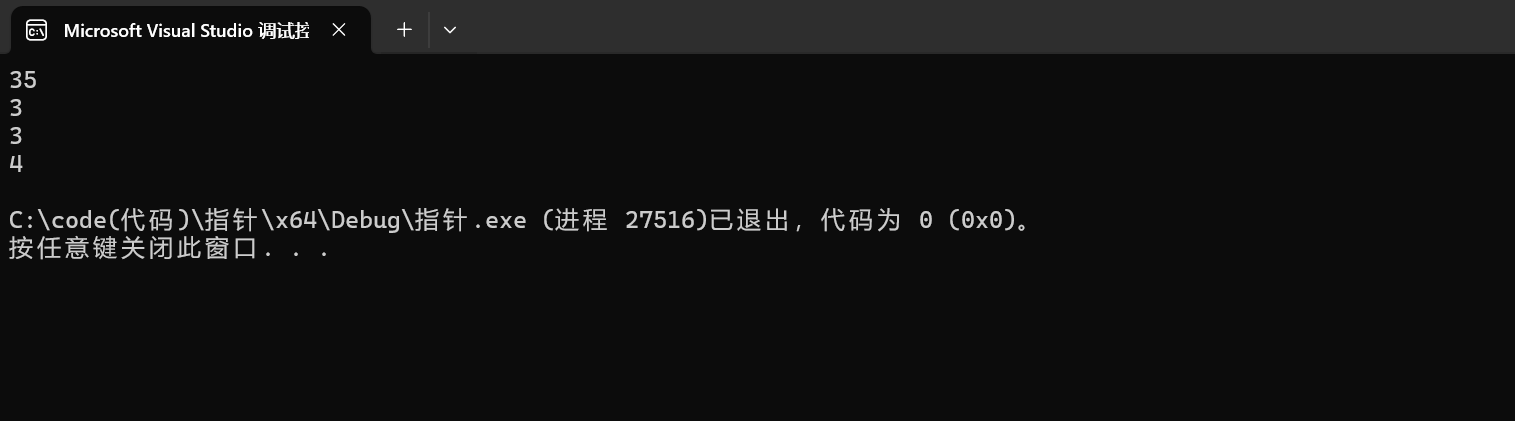
这里输出的第一行为随机值,因为arr1中存放的是单个字符而没有存放'\0',导致其会继续向后计算,直到'\0'停止。
这里输出的第二行就是字符串“abc”真正的大小,因为在arr2中存放的是完整的字符串,所以在arr2[3]中就存放的为"\0",因而字符串大小为3。
第三行和第四行的区别就在于了,arr1字符串数组无"\0",而arr2字符串数组中存在"\0",所以打印的结果就相差1。
1.3 sizeof与strlen的区别
1. 本质区别
- sizeof是C/C++中的运算符(operator),在编译时就能确定结果
- strlen是C标准库函数(定义在string.h中),需要在运行时计算
2.功能差异
- sizeof计算的是对象或类型在内存中占用的字节数
- 示例:char str[100] = "hello";
- sizeof(str)将返回100(数组总大小)
- strlen计算的是字符串的实际长度(不包括结尾的'\0')
- 示例:char str[100] = "hello";
- :strlen(str)将返回5("hello"的长度)
3.接受参数类型的差异
- sizeof可以接受多种参数:
- 数据类型(如sizeof(int))
- 变量(如sizeof(x))
- 表达式(如sizeof(3+5.0))
- strlen只能接受以'\0'结尾的字符串指针
4.计算时机
- sizeof在编译时就确定结果
- 示例:int arr[10];
- sizeof(arr)在编译时就被替换为40(假设int为4字节)
- strlen需要在运行时遍历字符串直到遇到'\0'
2.数组与指针
2.1一维数组与指针
可以尝试一下这些题目,接下来将详细剖析以下代码。
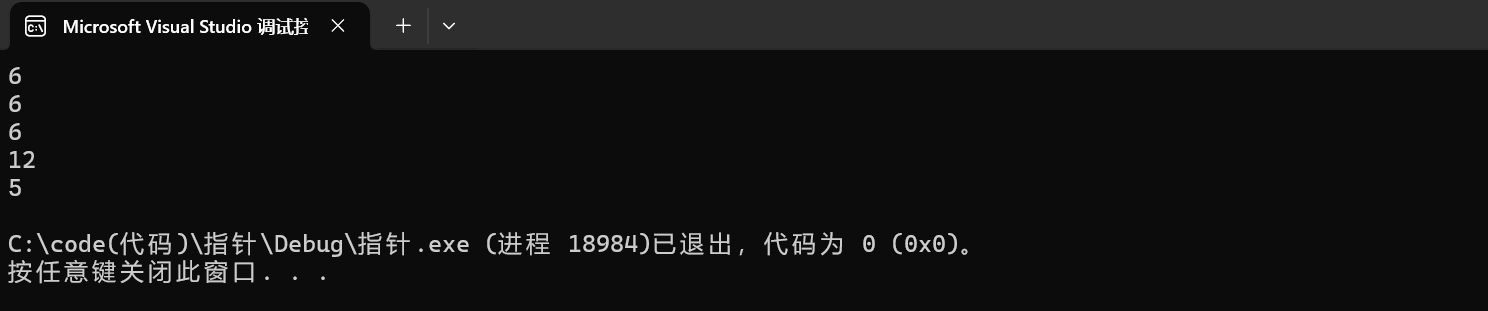
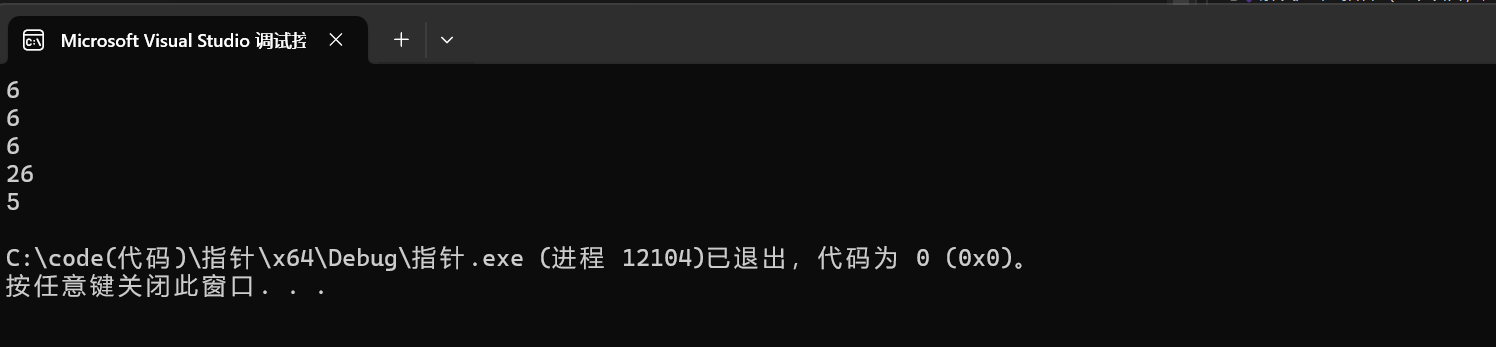
1 int a[] = {1,2,3,4};
2 printf("%d\n",sizeof(a)); //16
3 printf("%d\n",sizeof(a+0));
4 printf("%d\n",sizeof(*a));
5 printf("%d\n",sizeof(a+1));
6 printf("%d\n",sizeof(a[1]));
7 printf("%d\n",sizeof(&a));
8 printf("%d\n",sizeof(*&a));
9 printf("%d\n",sizeof(&a+1));
10 printf("%d\n",sizeof(&a[0]));
11 printf("%d\n",sizeof(&a[0]+1));对于一维数组要注意两个地方:
1.sizeof(数组名),其中数组名单独放,计算的是整个数组的大小。
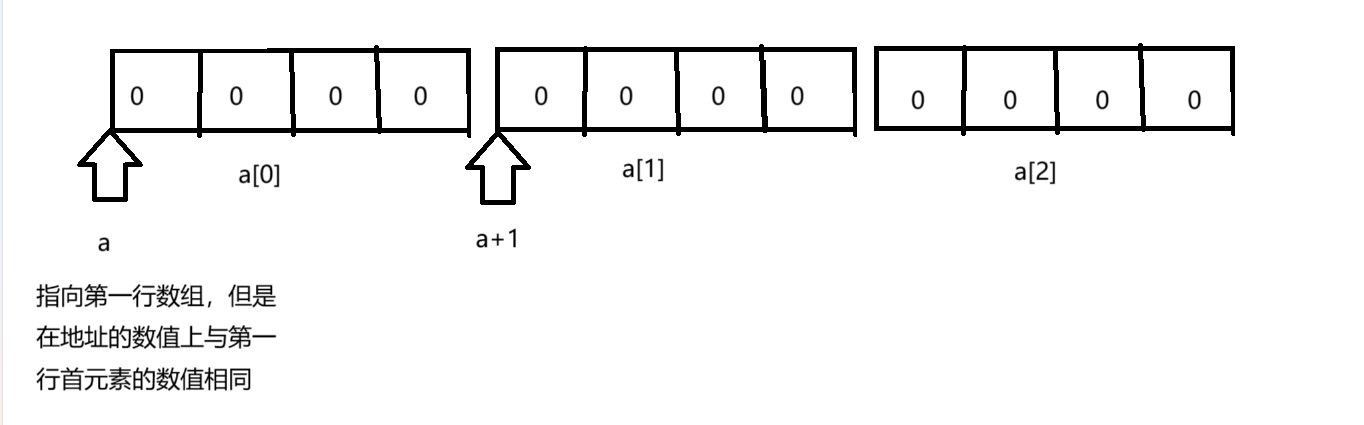
2.&arr拿到的是整个数组的地址,存放在数组指针中,数值上和首元素的地址一样,但是含义却是完全不相同。
其他情况下数组名就是首元素的地址
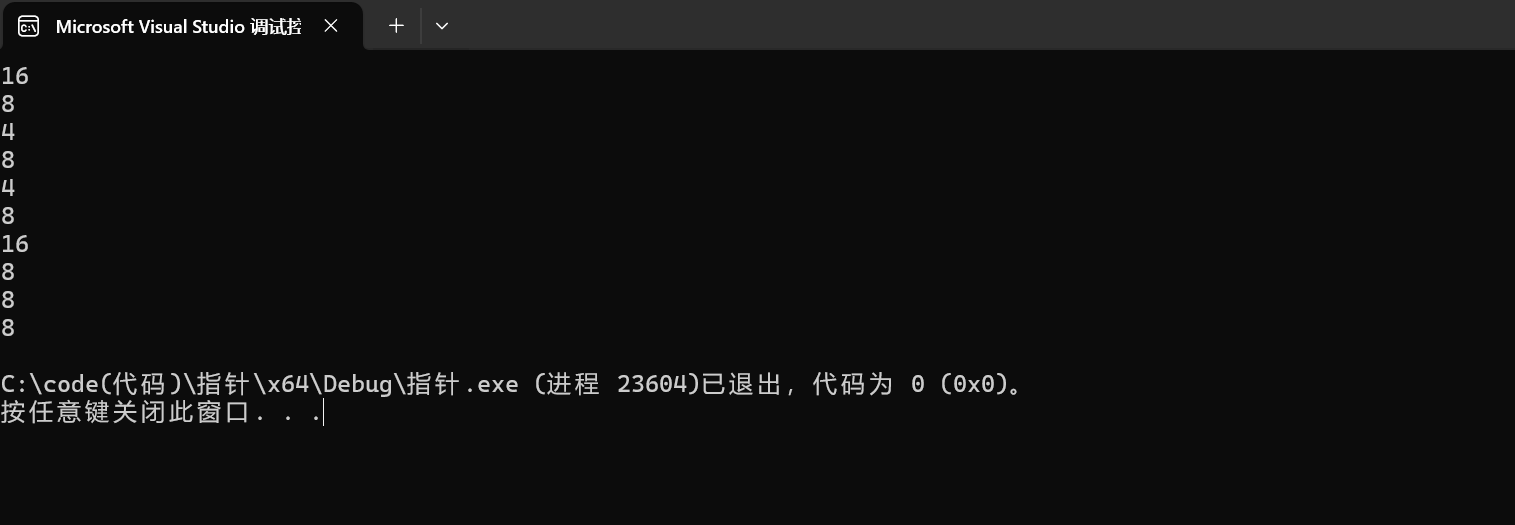
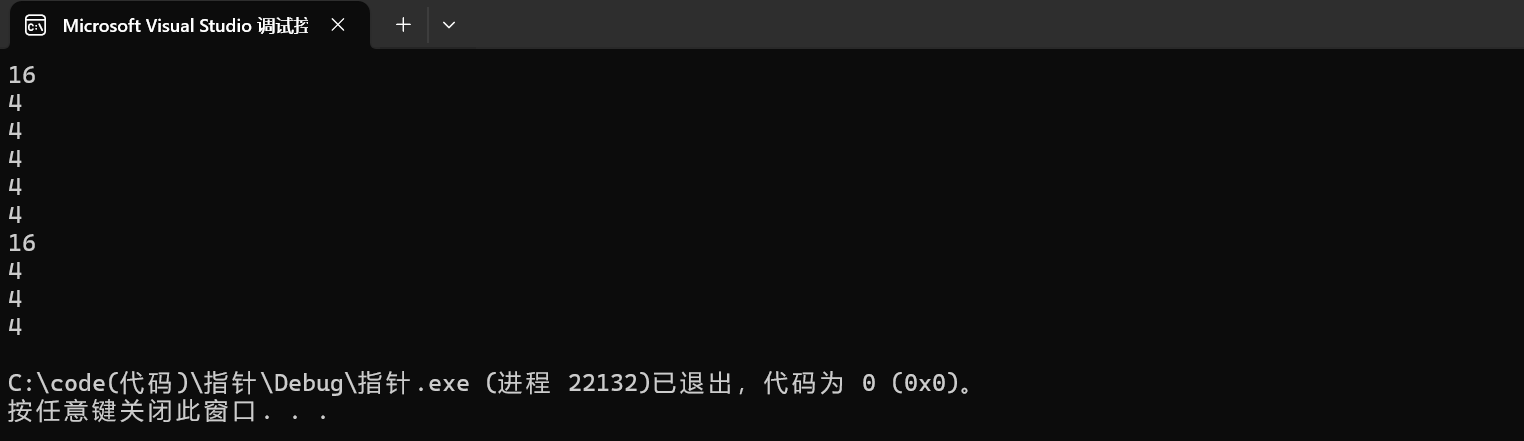
1. printf("%d\n",sizeof(a));
这里是sizeof(a),即sizeof(数组名)计算的是整个数值的大小,对于整形元素是4个字节,数组中有4个元素,所以这里应该大小为16个字节。
2.printf("%d\n",sizeof(a+0));
不同于sizeof(a),这里是sizeof(a+0),sizeof中放入的是一个表达式,它会在编译阶段就进行了判定,因为这里的a相当于首元素地址,这个表达式就会被认定为指针运算,所以它计算得到的是指针的大小,在x86中是4个字节,在x64中是8个字节。
3.printf("%d\n",sizeof(*a));
这里的a是数组首元素的地址,所以解引用拿到的是a[0]这个整形数据,即1,所以sizeof(int)计算的结果为4个字节
4.printf("%d\n",sizeof(a+1));
这里的a是数组首元素的地址,类型就为(int*),所以加1跳过4个/8个字节,即指向了第二个元素,a+1就是第二个元素的地址,计算指针类型的大小,在x86中是4个字节,在x64中是8个字节。
5. printf("%d\n",sizeof(a[1]));
a[1]就是数组中第二个元素,即是2,是一个整形元素,sizeof(int)就是4个字节
6.printf("%d\n",sizeof(&a));
&a是整个数组的地址,存放在数组指针中,假设有一个数值指针p1,int (*p1)[4]=&a,所以sizeof(&a)计算的就是数组指针的大小,只要是指针在x86平台下就是4个字节,在x64平台下就是8个字节。
7.printf("%d\n",sizeof(*&a));
这段代码可以从两方面理解:
1.这里&a就相当于拿到整个数组的地址,在进行解引用相当于拿到了数组名,sizeof(数组名)计算的就是整个数组的大小,也就是16个字节
2.这里*&可以认为相互抵消了,所以就是计算sizeof(数组名),计算得到的就是整个数组的大小,也就是16个字节。
8.printf("%d\n",sizeof(&a+1));
这里是&a,类型是数组指针类型,指向的是int a[] = {1,2,3,4},整个数组有4个整形元素,数组大小就为16个字节,所以&a加1就跳过16个字节,尽管跳过了16个字节,本质还是一个数组指针,所以sizeof(int (*)[]),在x86环境下就是4个字节,在x64环境下就是8个字节。
9.printf("%d\n",sizeof(&a[0]));
这里直接就是取出的第一个元素的地址,也就是int *类型,即整形指针类型,所以sizeof(int *)大小,在x86环境下就是4个字节,在x64环境下就是8个字节
10. printf("%d\n",sizeof(&a[0]+1))
&a[0],类型为int *,&a[0]+1跳过4个/8个字节(x86/x64),指向第二个元素,所以相当于计算的就是第二个元素的地址,第二个元素的地址也是int *类型,sizeof(int *)得到结果在x86环境下就是4个字节,在x64环境下就是8个字节。
x64环境下运行的结果:
x86环境下运行的结果:
2.2字符数组与指针
2.2.1sizeof字符数组与指针(不含'\0'的字符数组)
1 char arr[] = {'a','b','c','d','e','f'};
2 printf("%d\n", sizeof(arr));
3 printf("%d\n", sizeof(arr+0));
4 printf("%d\n", sizeof(*arr));
5 printf("%d\n", sizeof(arr[1]));
6 printf("%d\n", sizeof(&arr));
7 printf("%d\n", sizeof(&arr+1));
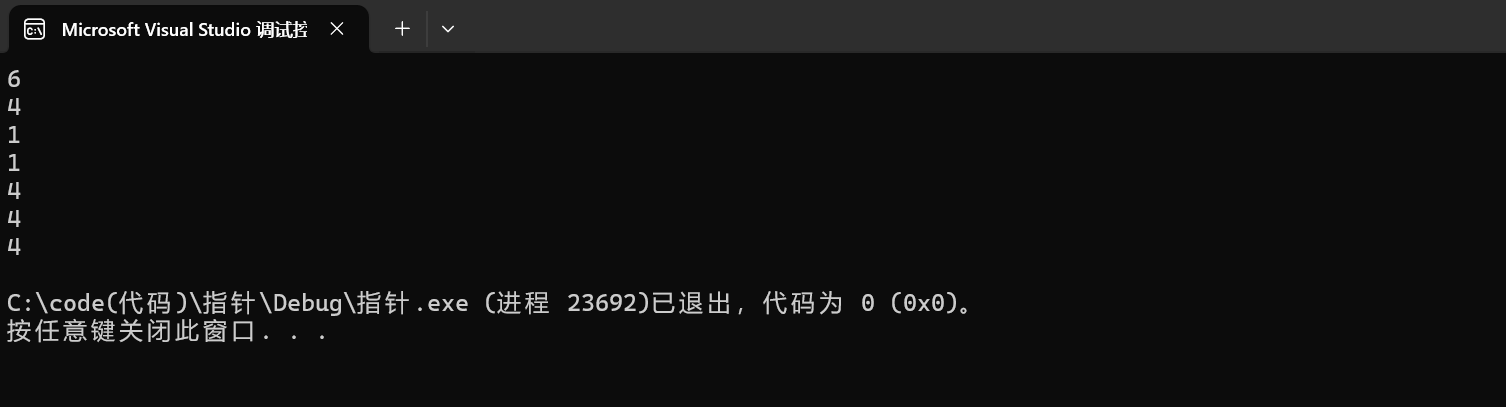
8 printf("%d\n", sizeof(&arr[0]+1));1.printf("%d\n", sizeof(arr));
这里是sizeof(数组名),所以计算得到的是整个数组的大小,又因为char类型是占1个字节,一共有6个元素,注意这个字符数组不含'\0',所以大小为6个字节。
2.printf("%d\n", sizeof(arr+0));
不同于sizeof(arr),这里是sizeof(arr+0),sizeof中放入的是一个表达式,它会在编译阶段就进行了判定,因为这里的arr相当于首元素地址,这个表达式就会被认定为指针运算,所以它计算得到的是指针的大小,在x86中是4个字节,在x64中是8个字节。
3.printf("%d\n", sizeof(*arr));
这里的arr是数组首元素的地址,解引用得到arr[0],一个char类型的元素,所以大小为1个字节。
4. printf("%d\n", sizeof(arr[1]));
这里arr[1]拿到了第二个元素,第二个元素为char类型,所以大小为1个字节。
5. printf("%d\n", sizeof(&arr));
这里是&arr,拿到的是整个数组的地址,类型为数组指针char(*)[6],数组指针也是指针,只要是指针,在x86环境下就是4个字节,在x64环境下就是8个字节。
6. printf("%d\n", sizeof(&arr+1));
这里是&arr,拿到的是整个数组的地址,类型为数组指针char(*)[6],数组指针+1,跨越的是数组类型*数组元素,尽管数组指针+1了,但是还是个指针,只要是指针,在x86环境下就是4个字节,在x64环境下就是8个字节。
7. printf("%d\n", sizeof(&arr[0]+1))
这里是&arr[0],拿到的是第一个元素的地址,由于是一个char类型的元素,所以&arr的类型就是char*,&arr[0]+1,跨越char大小的字节,指向第二个元素,依旧是指针,只要是指针,在x86环境下就是4个字节,在x64环境下就是8个字节。
在x86环境下
在x64环境下
2.2.2strlen字符数组和指针(不含'\0'的字符数组)
简单回顾一下,strlen的函数原型及其作用
size_t strlen ( const char * str );
通过传递一个字符串的地址,计算字符串,'\0'之前的元素个数,不包括'\0'。
1 char arr[] = {'a','b','c','d','e','f'};
2 printf("%d\n", strlen(arr));
3 printf("%d\n", strlen(arr+0));
4 printf("%d\n", strlen(*arr)); //报错
5 printf("%d\n", strlen(arr[1]));//报错
6 printf("%d\n", strlen(&arr));
7 printf("%d\n", strlen(&arr+1));
8 printf("%d\n", strlen(&arr[0]+1));1.printf("%d\n", strlen(arr)
这里的arr是数组的首地址,由于这个字符数组没有'\0',所以传递的首地址过去,需要找到第一个'\0'才会停止,所以这里打印的是一个随机值。
2.printf("%d\n", strlen(arr+0));
这里的arr是数组的首地址,arr+0还是数组的首地址,由于这个字符数组没有'\0',所以传递的首地址过去,需要找到第一个'\0'才会停止,所以这里打印的是一个随机值。
3. printf("%d\n", strlen(*arr));
这里的arr是数组首元素的地址,*arr拿到的是第一个元素,即'a',而strlen的原函数是size_t strlen ( const char * str ),所以这里的'a'会被转化为地址,我们知'a'的ascii值是97,在十六进制中是0x61,而这里的地址是我们用户不能访问的,所以这段代码会报错。

4.printf("%d\n", strlen(arr[1]));
这里拿到的是第二个元素,即'b',我们知道'b'的ascii值是98,在十六进制中是0x62,同样在这里的地址是我们用户所不能访问的,所以这段代码也会报错。

5.printf("%d\n", strlen(&arr));
&arr拿到的是整个数组的大小,虽然和数组名的含义完全不同,但是在数值上两者是完全相同的,都是第一个元素首字节的地址,由于这个字符数组没有'\0',所以传递的首地址过去,需要找到第一个'\0'才会停止,所以这里打印的是一个随机值。
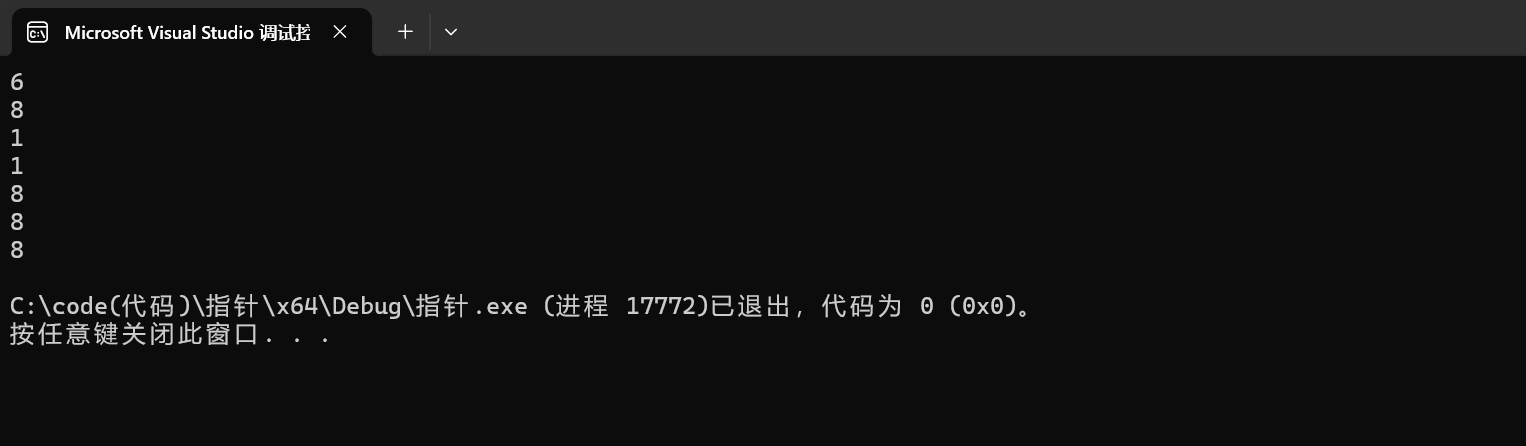
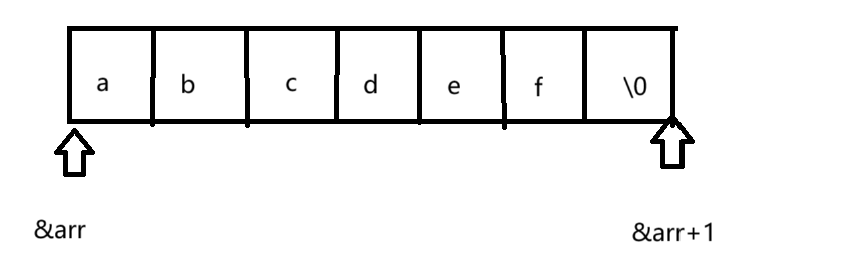
6. printf("%zd\n", strlen(&arr + 1));
&arr拿到的是整个数组的大小,&arr+1跨越的是整个数组,如下图示可知
由于这个字符数组没有'\0',所以传递的首地址过去,需要找到第一个'\0'才会停止,所以这里打印的是一个随机值,但是相比于strlen(&arr),在数值上strlen(&arr+1)=strlen(&arr)-6。
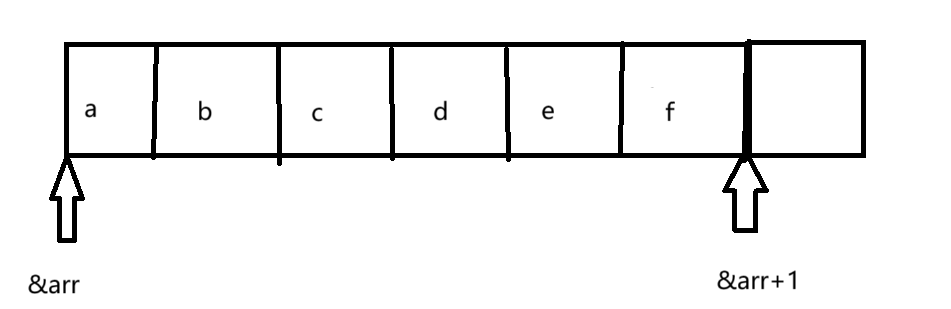
7. printf("%d\n", strlen(&arr[0]+1));
&arr[0]拿到的是第一个元素的地址,类型为char*,不同于&arr,&arr的类型就是数组指针类型,所以&arr[0]+1,跨越的是char类型大小的字节数,指向的是第二个元素,如下图:
由于这个字符数组没有'\0',所以传递的首地址过去,需要找到第一个'\0'才会停止,所以这里打印的是一个随机值,但是相比于strlen(&arr),在数值上strlen(&arr[0]+1)=strlen(arr)-1。

2.2.3.sizeof字符数组和指针(含有'\0'的字符数组)
1 char arr[] = "abcdef";
2 printf("%d\n", sizeof(arr));
3 printf("%d\n", sizeof(arr+0));
4 printf("%d\n", sizeof(*arr));
5 printf("%d\n", sizeof(arr[1]));
6 printf("%d\n", sizeof(&arr));
7 printf("%d\n", sizeof(&arr+1));
8 printf("%d\n", sizeof(&arr[0]+1));与之前不同的是这个字符数组,现在有了'\0'。
1.printf("%d\n", sizeof(arr));
这里是sizoef(arr),计算的是整个数组的大小,由于每个元素是char类型,加上'\0'一共有七个元素,所以这里打印的结果就是7个字节
2.printf("%d\n", sizeof(arr+0));
不同于sizeof(arr),这里是sizeof(arr+0),sizeof中放入的是一个表达式,它会在编译阶段就进行了判定,因为这里的arr相当于首元素地址,这个表达式就会被认定为指针运算,所以它计算得到的是指针的大小,在x86中是4个字节,在x64中是8个字节。
3.printf("%d\n", sizeof(*arr));
这里的arr是数组首元素的地址,*arr拿到的是第一个元素,即'a',因为是char类型的数组,所以打印结果就是1个字节。
4.printf("%d\n", sizeof(arr[1]));
这里直接利用下标访问符,访问的是数组中第二个元素,即'b',因为是char类型的数组,所以打印结果就是1个字节。
5.printf("%d\n", sizeof(&arr));
这里是&arr,拿到的是整个数组的地址,存放在数组指针中,类型为char (*)[7],数组指针也是指针,在x86的环境下大小为4个字节,在x64的环境下大小为8个字节。
6. printf("%d\n", sizeof(&arr+1));
这里是&arr,拿到的是整个数组的地址,存放在数组指针中,类型为char (*)[7],&arr+1也就是跨越了一个数组字节的大小,但本质上还是指针,只要是指针,在x86的环境下大小为4个字节,在x64的环境下大小为8个字节。
7.printf("%d\n", sizeof(&arr[0]+1));
这里是&arr[0],拿到的是第一个元素的地址,存放在char*的指针中,&arr[0]+1,跨越一个char类型大小的字节,即指向了第二个元素,但本身还是一个字符指针,只要是指针在x86的环境下大小为4个字节,在x64的环境下大小为8个字节。
在x86的环境下:

在x64的环境下:
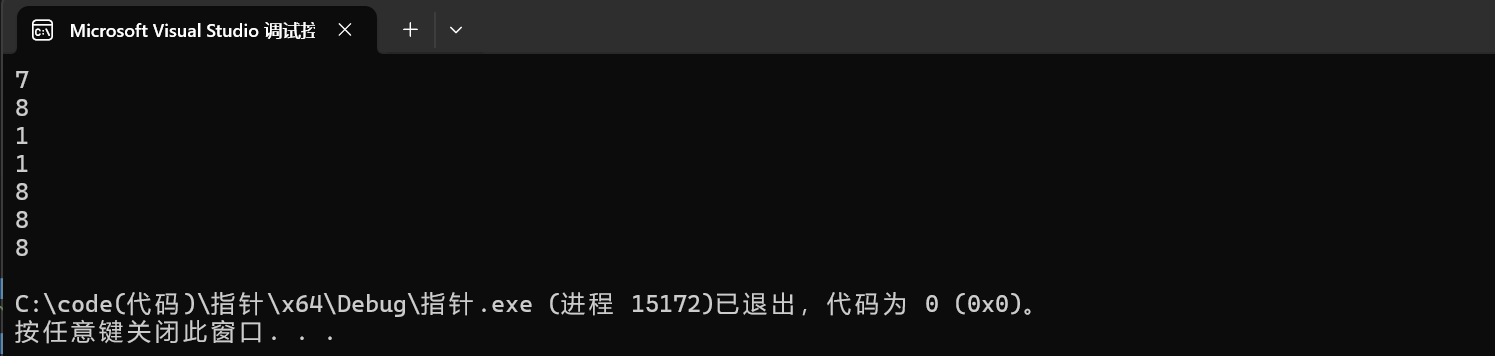
2.2.4strlen字符数组和指针(含有'\0'的字符数组)
1 char arr[] = "abcdef";
2 printf("%d\n", strlen(arr));
3 printf("%d\n", strlen(arr+0));
4 printf("%d\n", strlen(*arr));
5 printf("%d\n", strlen(arr[1]));
6 printf("%d\n", strlen(&arr));
7 printf("%d\n", strlen(&arr+1));
8 printf("%d\n", strlen(&arr[0]+1));与之前不同的是这个字符数组,现在有了'\0',有了'\0',strlen就能正确的计算得到字符串正确的个数。
1.printf("%d\n", strlen(arr));
这里的arr是数组首元素的地址,传参给strlen,计算得到的就是整个字符串的个数,即大小为6。
2.printf("%d\n", strlen(arr+0));
这里的arr是数组首元素的地址,arr+0即指向了第一个元素,传参给strlen,计算得到的是整个字符串的个数,即大小为6。
3.printf("%d\n", strlen(*arr));
这里的*arr解引用得到的是第一个字符,即字符'a',由于字符'a'的ASCII码值是97,在这里传参给strlen函数,就会进行类型转化为十六进制的地址0x61,而这里的地址是用户不能够访问的,所以这里就会出现异常报错。
4.printf("%d\n", strlen(arr[1]));
这里arr[1]通过下标访问拿到的是第二个元素,即'b',由于'b'的ASCII值是98,在向strlen传参的过程中就会被转化成char *类型的十六进制地址即0x62,而这里的地址是用户所不能访问的,所以这里就会出现异常报错。
5.printf("%d\n", strlen(&arr));
&arr拿到的是整个数组的地址,但在数值上是与首元素的地址相同,但注意的是两则的含义是完全不相同的,传参给strlen计算得到整个字符串的个数,即大小为6。
6.printf("%d\n", strlen(&arr+1))
&arr拿到的是整个数组的地址,在数值上与首元素地址相同,类型为char (*)[7],&arr+1跨越的是整个数组的大小,如下图所指向:
所以传参给strlen计算得到的是一个随机值,我们不知道它后面的'\0'位置
7. printf("%d\n", strlen(&arr[0]+1));
&arr[0]拿到的是第一个元素的地址,指向的是第一个元素,存放在char*类型的指针中,&arr[0]+1就相当于指向了第二个元素,得到的是第二个元素的地址,传给strlen计算得到是从第二个元素开始,所以计算得到的结果是5。
2.3字符指针指向常量字符串
我们知道在c语言中,字符指针可以指向一个常量字符串,而常量字符串是不能进行修改得。
2.3.1sizoef常量字符串
1 char *p = "abcdef";
2 printf("%d\n", sizeof(p));
3 printf("%d\n", sizeof(p+1));
4 printf("%d\n", sizeof(*p));
5 printf("%d\n", sizeof(p[0]));
6 printf("%d\n", sizeof(&p));
7 printf("%d\n", sizeof(&p+1));
8 printf("%d\n", sizeof(&p[0]+1));
1.printf("%d\n", sizeof(p));
这里的p是一个char*类型的指针而不是数组名,只要是指针在x86的环境就是4个字节,在x64的环境下就是8个字节。
2.printf("%d\n", sizeof(p+1));
这里的p是一个char*类型的指针,p+1跨越一个char字节大小,所以指向的是字符串中的第二个元素即'b',但本质上还是一个指针,只要是指针在x86的环境下就是4个字节,在x64的环境下就是8个字节。
3.printf("%d\n", sizeof(*p));
这里的p是一个char*类型的指针,指向的是字符串中第一个元素的地址,即'a'的地址,通过*操作符拿到这个元素'a',这是字符串,所以类型为char,sizeof(char)大小就为1个字节。
4.printf("%d\n", sizeof(p[0]));
这里的p[0]就相当于*(p+0),p为char*类型的指针,指向的是第一个元素,通过解引用找到第一个元素,即'a',由于是char类型的字符串,所以计算的是sizeof(char)大小就为1个字节。
5. printf("%d\n", sizeof(&p));
这里的&p拿到的是指针变量p的地址,因为指针变量也是变量当然也会存在地址,&p就存放在二级指针中,即char **,二级指针也是指针,只要是指针在x86的环境下就是4个字节,在x64环境下就是8个字节。
6.printf("%d\n", sizeof(&p+1));
这里的&p拿到的是指针变量p的地址,因为指针变量也是变量当然也会存在地址,&p就存放在二级指针中,即char **,&p+1跨越的就是char*大小的字节数,但本质上还是一个指针,只要是指针在x86的环境下就是4个字节,在x64的环境下就是8个字节。
7.printf("%d\n", sizeof(&p[0]+1));
这里&p[0]相当于&*(p+0),我们知道取地址和解引用是一对运算符,所以这里可以进行抵消,故而相当于指针变量p,p的类型就是char *,p+1跨越的就是一个char类型的字节大小,但是本身还是一个指针,只要是指针在x86的环境下就是4个字节大小,在x64的环境下就是8个字节。
在x86的环境下
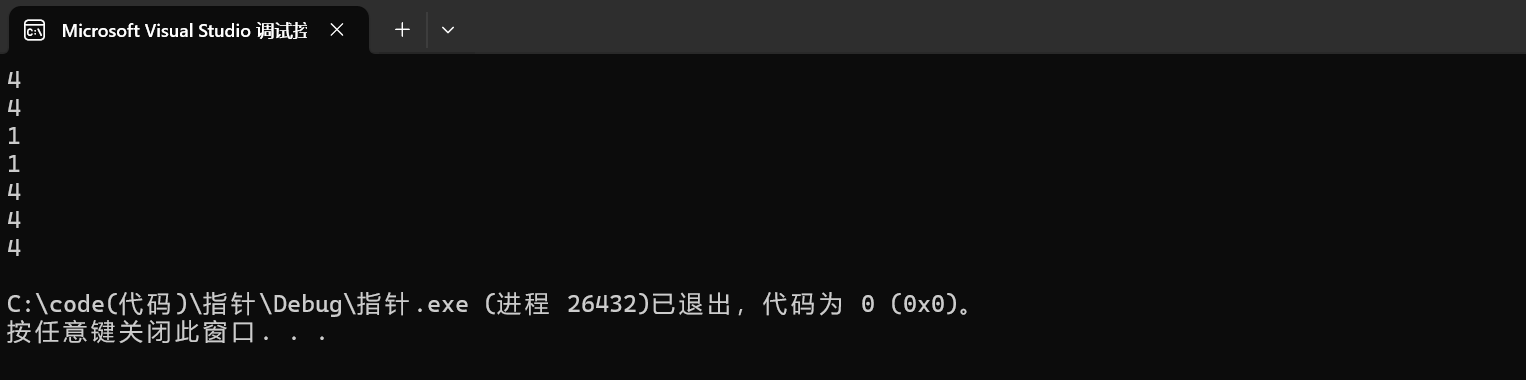
在x64的环境下
2.3.2strlen常量字符串
1 char *p = "abcdef";
2 printf("%d\n", strlen(p));
3 printf("%d\n", strlen(p+1));
4 printf("%d\n", strlen(*p)); //报错
5 printf("%d\n", strlen(p[0])); //报错
6 printf("%d\n", strlen(&p));
7 printf("%d\n", strlen(&p+1));
8 printf("%d\n", strlen(&p[0]+1));1.printf("%d\n", strlen(p));
这里的p是char*类型的指针,默认指向首元素的地址,即'a'的地址,传参给strlen计算的就是整个字符串的长度,即大小为6。
2.printf("%d\n", strlen(p+1));
这里的p是char*类型的地址,默认指向首元素的地址,即'a'的地址,p+1,跨越一个char字节大小,指向字符串中第二个元素,即'b'的地址,传参给strlen计算得到5。
3.printf("%d\n", strlen(*p));
这里的*p解引用得到的是第一个字符,即字符'a',由于字符'a'的ASCII码值是97,在这里传参给strlen函数,就会进行类型转化为十六进制的地址0x61,而这里的地址是用户不能够访问的,所以这里就会出现异常报错。
4.printf("%d\n", strlen(p[0]));
p[0]相当于*(p+0),这里拿到的是第一个元素,即'b',我们知道'b'的ascii值是98,在十六进制中是0x62,同样在这里的地址是我们用户所不能访问的,所以这段代码也会报错。
5.printf("%d\n", strlen(&p));
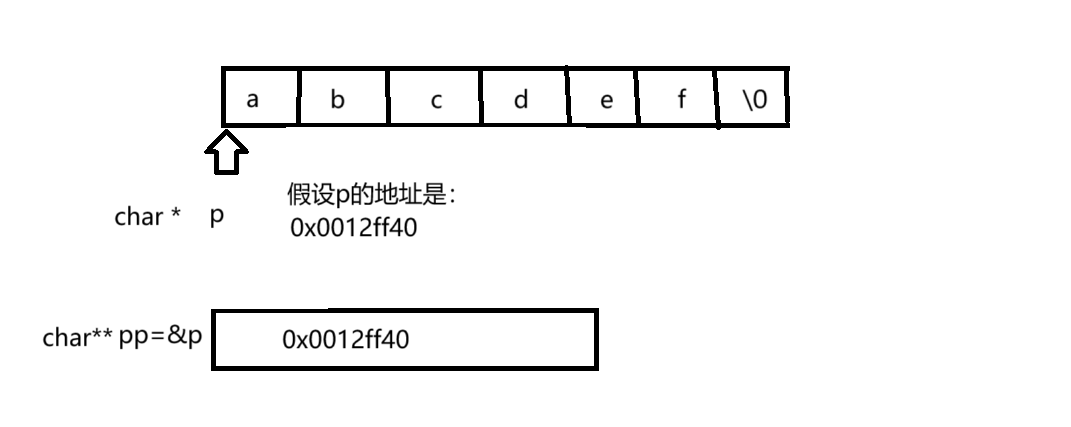
这里的&p拿到的是指针变量p的地址,因为指针变量也是变量当然也会存在地址,&p就存放在二级指针中,即char **,传给strlen的一级指针的地址,而不是字符串的地址,故而这里就会是一个随机值,画图如下:
因为传入二级指针的地址,不能确定后面'\0'的位置,故而也不能确定其大小,所以这里也是一个随机值。
6.printf("%d\n", strlen(&p+1));
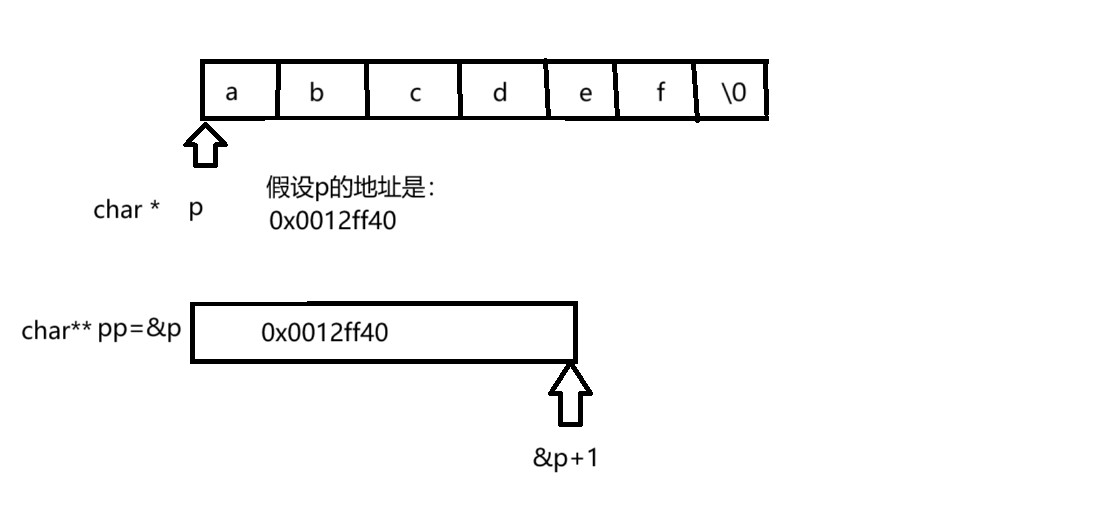
这里的&p拿到的是指针变量p的地址,因为指针变量也是变量当然也会存在地址,&p就存放在二级指针中,即char **,而&p+1,相当于二级指针进行加1,跨越的是一个char *字节大小的地址,指向如下图所示:
所以这里也是一个随机值,但与前面5中的代码没有必然的大小关系,因为我们不知道在跨越的char*大下的字节中是否有'\0'。
7.printf("%d\n", strlen(&p[0]+1));
这里&p[0],相当于&*(p+0),我们知道*&是一对运算符,所以在这里抵消了,&p[0]就相当于p,一个字符指针类型为char*,字符指针加1跨越的就是char大小字节的地址,所以就指向了'b',传参给strlen计算得到的结果就是5。


2.4二维数组与指针
对于二维数组和指针问题,对于很多读者来说(包括我)都是很头疼的,不能深入理解这里的一维数组名和数组名到底有什么关系和区别,还有不能深刻了解二维数组是怎样在内存里面排布的,那么如果你也有类似的问题,那我们可以一起来看一下有关二维数组和指针相关的知识。
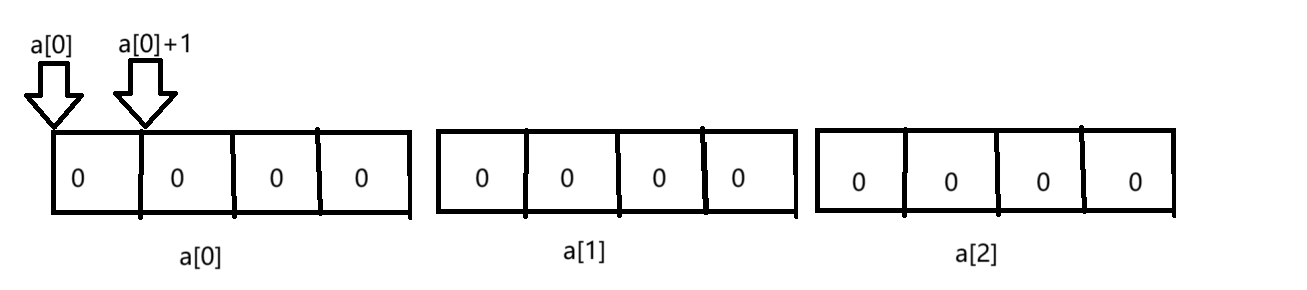
1 int a[3][4] = {0};
2 printf("%d\n",sizeof(a));
3 printf("%d\n",sizeof(a[0][0]));
4 printf("%d\n",sizeof(a[0]));
5 printf("%d\n",sizeof(a[0]+1));
6 printf("%d\n",sizeof(*(a[0]+1)));
7 printf("%d\n",sizeof(a+1));
8 printf("%d\n",sizeof(*(a+1)));
9 printf("%d\n",sizeof(&a[0]+1));
10 printf("%d\n",sizeof(*(&a[0]+1)));
11 printf("%d\n",sizeof(*a));
12 printf("%d\n",sizeof(a[3]));我们以整形二维数组为例,讨论二维数组与指针的关系,在此之前我们要先了解二维数组是在内存中如何排布的,请看两组对比:
很多读者认为在内存中二维数组是这样排布的:
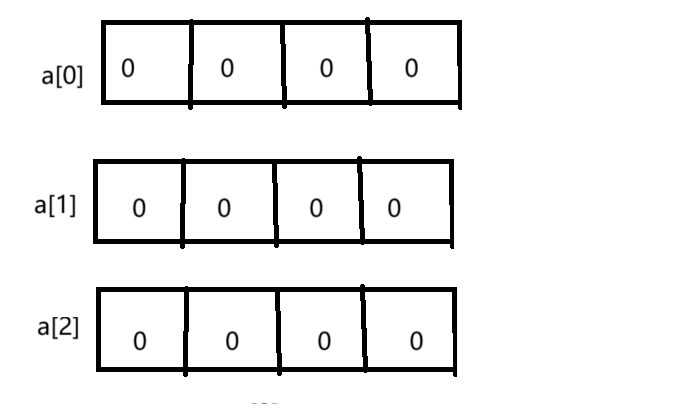
其实不然,二维数组在内存中其实是多个连续的一维数组合成的,那么由此我们就可以有一个想法,那岂不是a[3][4]中,a[0],a[1],a[2]分别是第一行的数组名,a[1]为第二行的数组名,a[2]为第三行的数组名吗?确实可以这样理解,将二维数组理解为多个一维数组拼接而成。
所以二维数组在内存中的正确排布情况如下图

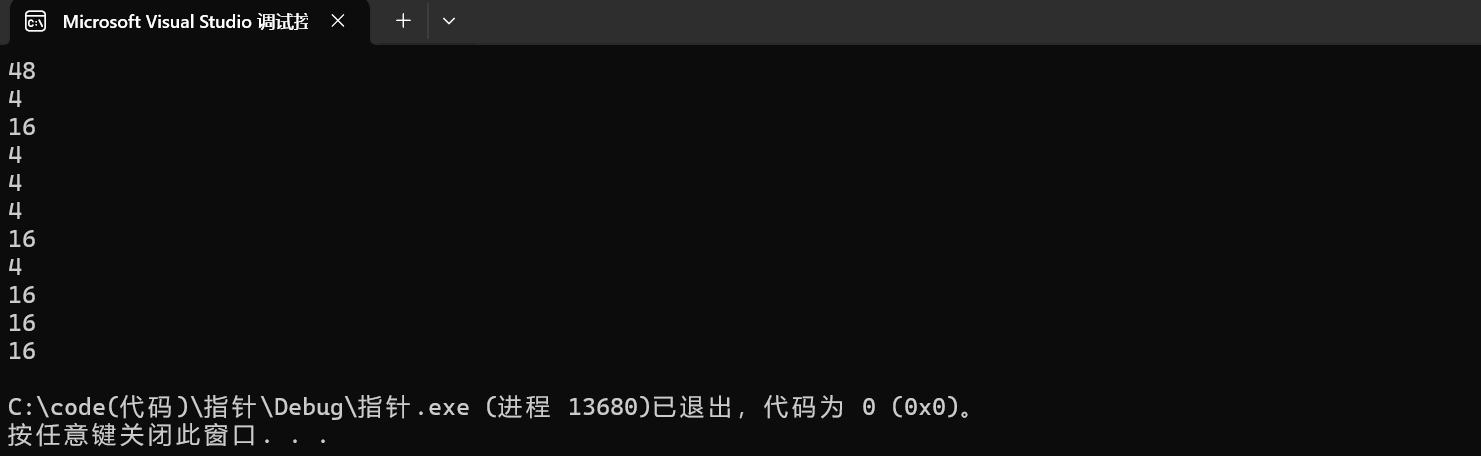
1.printf("%d\n",sizeof(a));
由前面的知识我们知道,sizoef(数组名)计算得到的是整个数组的大小,所以这里虽然是二维数组但也不例外,由于这里为整形元素,且为三行四列,故大小为12*4=48个字节。
2.printf("%d\n",sizeof(a[0][0]));
这里a[0][0]拿到的是第一行第一列的元素,该元素是整形,所以计算的是sizeof(int),大小就为4个字节。
3.printf("%d\n",sizeof(a[0]));
这里是a[0],如何理解a[0],其实由前面我们讨论二维数组存储的方式可知,a[0]就相当于第一行的数组名,既然是数组名,我们又知道sizeof(数组名)计算的是整个数组的大小,那么这里计算的当然是二维数组中第一行的大小,故大小为16个字节。
4.printf("%d\n",sizeof(a[0]+1));
这里的a[0]我们知道是第一行元素的数组名,数组名又是数组首元素的地址,也就是第一行第一个元素的地址,如下图指向
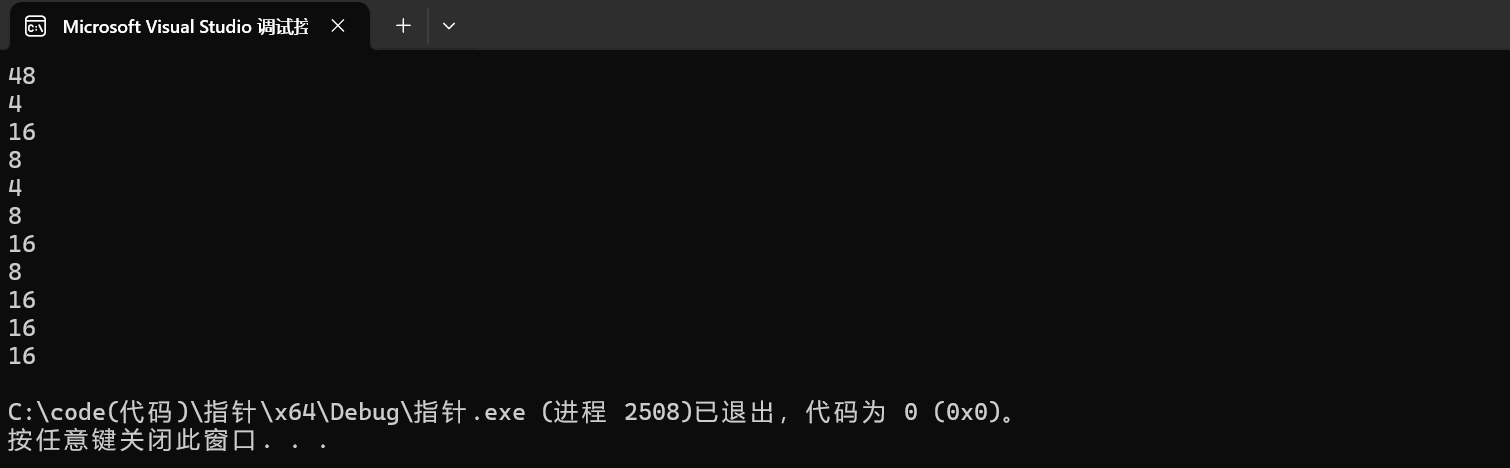
所以这里指向的就是a[0][1],相当于拿到第一行第二个元素的地址,所以地址类型,或者说指针类型是int *,我们知道只要是指针,在x86环境下就是4个字节,在x64环境下就是8个字节
5.printf("%d\n",sizeof(*(a[0]+1)));
由前面的分析我们知道了,a[0]+1就相当于拿到了a[0][1]的地址,那么我们对其解引用就相当于找到这个元素即拿到了0这个整形元素,所以我们这里计算的就是sizeof(int),大小就为4个字节。
6. printf("%d\n",sizeof(a+1));
我们知道数组名是数组首元素的地址,那么对于二维数组来说,数组名就相当于拿到第一行数组的地址,也就是整个a[0]的地址,就相当于&a[0],由此分析,这里的a类型为int(*)[4],为数组指针,指向第一行数组,a+1就相当于跨越了一个数组的地址,这里第一行数组的长度为4,数组元素为整形,所以跨越的是16个字节大小,因而指向了第二行。相当于拿到了&a[1]如下图所示:
尽管加1指向了第二行,但是a本质上是一个数组指针,只要是指针在x86环境下就是4个字节大小,在x64环境下就是8个字节大小。
7.printf("%d\n",sizeof(*(a+1)));
第一种理解:由前面我们知道a+1指向了第二行数组,这里解引用就相当于第二行数组的数组名,sizoef(数组名)计算的就是整个数组的大小,也就是第一行的大小,即4*4=16个字节。
第二种理解:由前面我们知道a+1指向了第二行数组,就相当于是&a[1],而这里是*&a[1],我们知道*和&是一对相互操作符,所以这里就抵消了,相当于是a[1]这个第二行数组,sizoef(数组名)计算的就是整个数组的大小,也就是第一行的大小,即4*4=16个字节。
8. printf("%d\n",sizeof(&a[0]+1));
我们知道&a[0]拿到的是第一行数组的地址,类型为int(*)[4],&a[0]+1,就相当于跨越一个第一行数组字节大小的地址,也就是16个字节的地址,所以这里就指向了第二行数组,但&a[0]+1本质上还是一个数组指针,只要是指针在x86的环境下就是4个字节,在x64的环境下就是8个字节。
9.printf("%d\n",sizeof(*(&a[0]+1)));
第一种理解:我们知道&a[0]+1拿到的就是第二行数组的地址,通过解引用就访问到第二行,就相当于拿到第二行的数组名,类型为int*,一个整形指针,只要是指针在x86的环境下就是4个字节,在x64的环境下就是8个字节。
第二种理解:&a[0]+1就等价于&a[1],再通过解引用就相当于*&a[1],我们知道*和&是一对操作符,两者就抵消了,所以这里就相当于拿到的是a[1]这个第二行的数组名,sizoef(数组名)计算的就是整个数组的大小,也就是第二行的大小,即4*4=16个字节。
10.printf("%d\n",sizeof(*a));
前面我们知道了,a就相当于拿到了第一行数组的地址,类型为int(*)[],就相当于&a[0],而这里进行解引用操作,而*&能够相互抵消,所以我们这里就相当于拿到的是第一行的数组名a[1],sizoef(数组名)计算的就是整个数组的大小,也就是第一行的大小,即4*4=16个字节。
11.printf("%d\n",sizeof(a[3]));
a[3]尽管没有真实存在,但是在计算机中还是会按照前面a[0],a[1],a[2]这样推理,而开辟相应的内存,所以这里a[3]与a[0],a[1],a[2]并没有本质区别,只是不再能够进行访问,但是确实是开辟了这样的空间,a[3]就相当于第四行的数组名,sizeof(数组名)计算得到就是整个数组字节大小,即4*4=16,所以这里是16字节。
在x86环境下:
在x64环境下:
3.指针运算题
试题1:问输出结果是什么?
#include <stdio.h>
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
printf( "%d,%d", *(a + 1), *(ptr - 1));
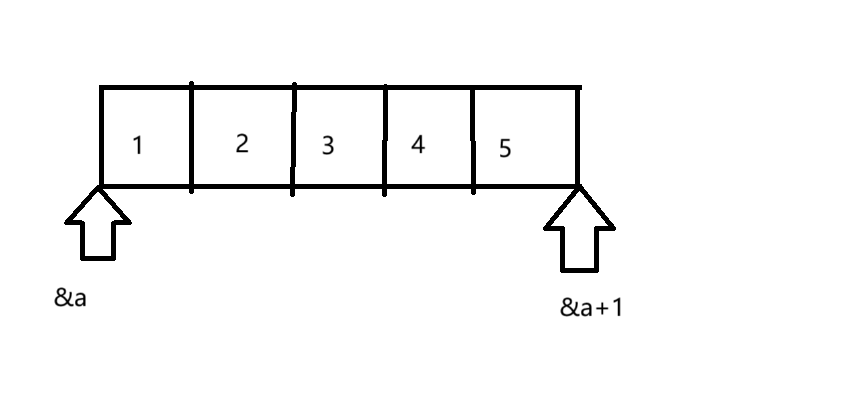
对于这段代码的核心是int *ptr = (int *)(&a + 1); 如何理解这段代码,先剖析&a+1,这里的&a,拿到的是a整个数组的地址,应该放在数组指针中,类型为int(*)[4],&a+1跳过了一个数组的地址,指向如下图所示:
然后这里通过强制类型转换为(int*),存放在整形指针ptr中。
printf( "%d,%d", *(a + 1), *(ptr - 1));
我们知道a是数组名即数组首元素的地址,类型为int*,a+1就指向了第二个元素,*(a+1)访问得到的就是元素2,前面我们已经知道了ptr指向,ptr类型为int*,ptr-1指向的就是最后一个元素,所以解引用访问得到就是5。
故打印结果为 2 5

试题2://在X86环境下
//假设结构体的⼤⼩是20个字节
//程序输出的结果是啥?
//在X86环境下
//假设结构体的⼤⼩是20个字节
//程序输出的结果是啥?
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
在x86的环境下定义了一个结构体,大小为20字节,声明了一个结构体指针,
struct Test*p = (struct Test*)0x100000; 这里是通过将0x100000这个地址强制类型转换为结构体指针。
p+0x1这里的0x1是16进制下的1,p的类型为结构体指针,所以加1,跨越了一个结构体,大小为20个字节,所以这里就是0x100000+20,但是这里进行的是16进制运算,故最后计算的结果为100014,在x86的环境下,在x86环境要打印够4个字节大小,以%p的形式打印的结果为00100014。
(unsigned long)p + 0x1这里将这个结构体指针转为(unsigned long),那么这里进行的就是无符号整形运算,加法就是简单的数值加1,即100000 + 1 = 100001,在x86环境要打印够4个字节大小,以%p的形式打印的结果就为00100001。
(unsigned int*)p + 0x1,这里结构体指针转换为(unsigned int*),那么这里进行的就是指针加法运算,对于int*类型的指针+1,跨越的就是一个整形字节的大小,在x86环境要打印够4个字节大小,以%p的形式打印的结果就为00100004。

试题3:假设是在x86环境下问输出结果是什么?
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
}printf( "%d", p[0]);
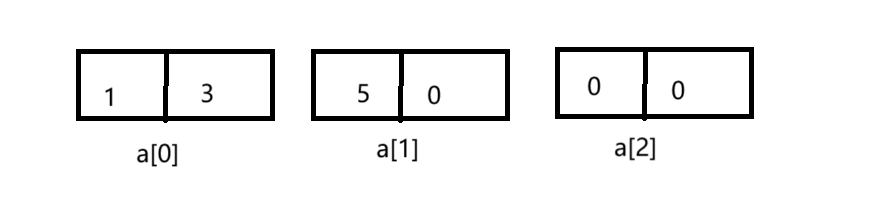
这里定义了一个二维数组, int a[3][2] = { (0, 1), (2, 3), (4, 5) }; 如何理解这个二维数组呢?其实这里运用了逗号表达式,对于逗号表达式,我们要去逗号最右边的为数据,所以这里就是
int a[3][2] = { 1,3,5 };如下图所示:
定义了int*p=a[0],这里的a[0]就相当于第一行数组的数组名,数组名就相当于数组首元素的地址,所以p就存放的是第一行数组首元素的地址,p[0]就相当于*(p+0),我们知道p+0就是第一行首元元素的地址,通过解引用访问到这个元素1。
打印结果为1

试题4://假设环境是x86环境,程序输出的结果是啥?
//假设环境是x86环境,程序输出的结果是啥?
#include <stdio.h>
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
对于int(*p)[4]=a,如何理解这段代码呢,对于二维数组的数组名是第一行数组的地址,存放在数组指针中,所以这里的p就相当于p=&a[0],但这里a的类型为int(*)[5]而这里的p类型为
int(*)[4]这里就有一个隐式类型转换。
&p[4][2] - &a[4][2]如何理解这段代码呢?
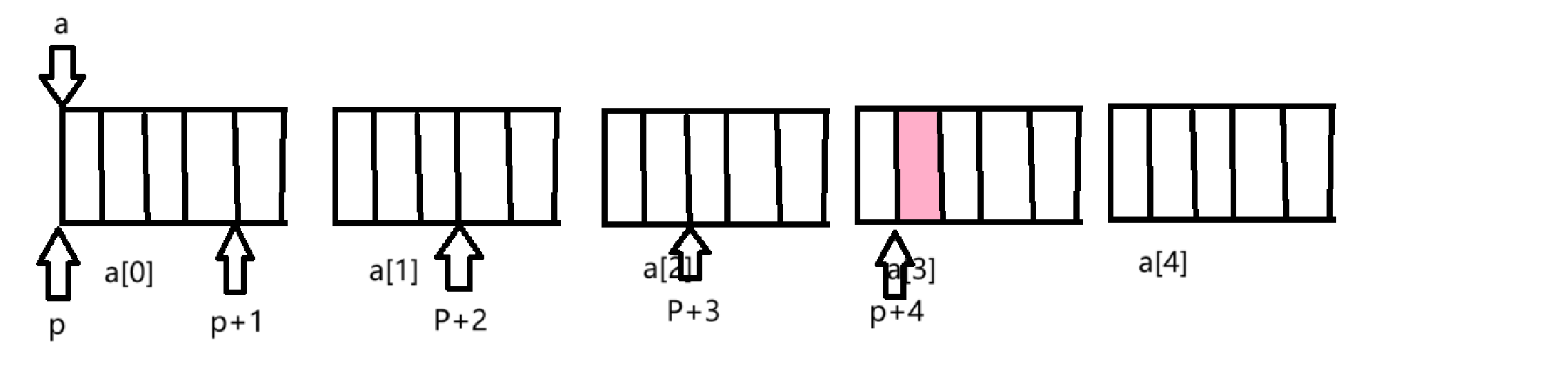
①p[4][2]=*(*(p+4)+2) ②a[4][2]=*(*(a+4)+2)
对于① p为数组指针,p+4,跳跃的是4*4=16个字节的地址,指向如下图:
*(p+4)如何理解呢,这里就相当于拿到的是a[3][2]的地址,一个整形的地址,类型为int*,
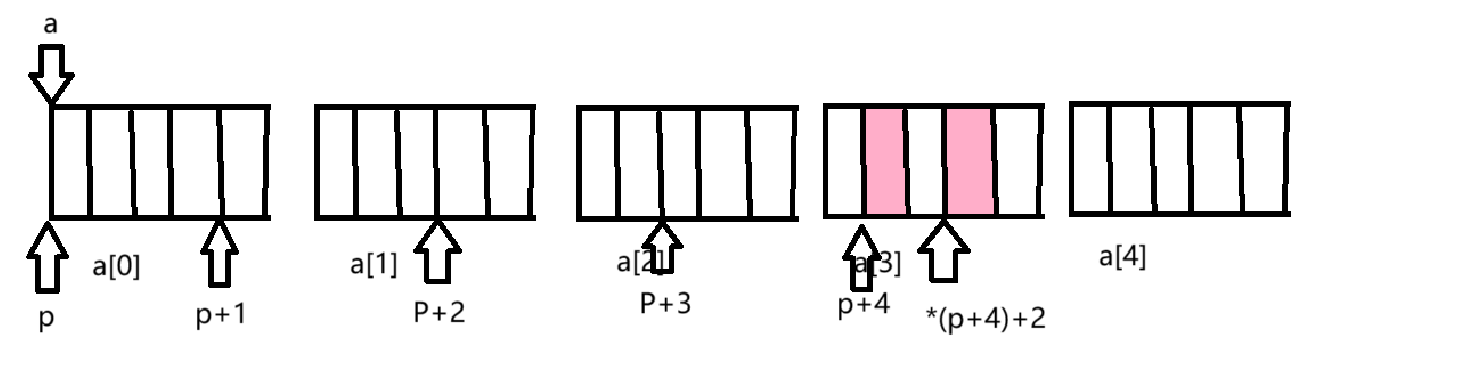
(*(p+4)+2),这里+2就相当于跨越2个整形的地址,就指向了a[3][3],如图所示:
在解引用拿到的就是a[3][3]这个元素了,所以&p[4][2]就是a[3][3]这个元素的地址。
而&a[4][2]如下图所指向:
综上所示&p[4][2]-&a[4][2],这里是同类型的指针-指针,所得结果就是指针之间的元素个数,但是&p[4][2]是属于低地址,而&a[4][2]是属于高地址,所以两者相减的结果为-4。
我们知道
%d -----打印的是有符号整形数据
%p -----打印的是16进制位的地址
对于-4来说在内存中存储的是补码
10000000 00000000 00000000 00000100 ---原码
11111111 11111111 11111111 11111011 ---反码
11111111 11111111 11111111 11111100 ---补码
而%p打印需要将补码转为原码进行打印吗,显然是不需要的,而%d打印的是数据的原码,所以需要转化。
故最后结果是FFFF FFFC -4
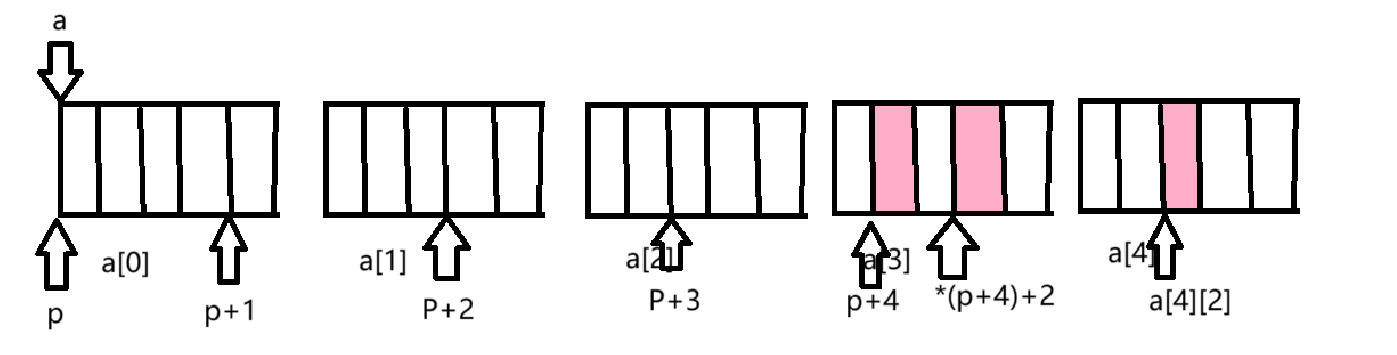

试题5:问输出的结果是什么?
#include <stdio.h>
int main()
{
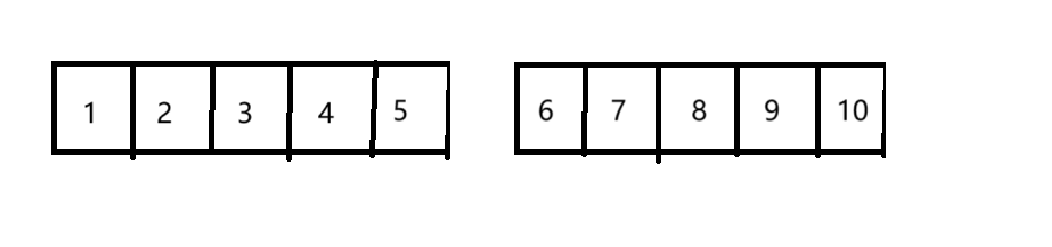
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}这里定义了一个二维数组,如图所示:
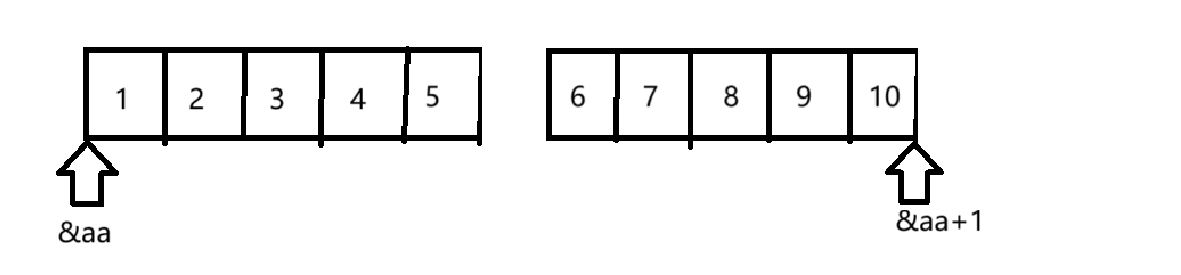
int *ptr1 = (int *)(&aa + 1),这里&aa拿到的是整个数组的地址,&aa+1跳过整个二维数组指向如下:
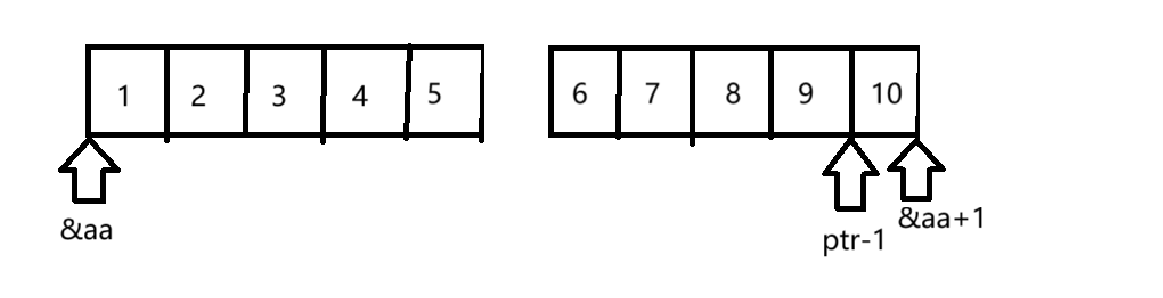
通过强制类型转换为int*,所以ptr1-1,指向如下图所示:
所以解引用拿到了元素10。
而int *ptr2 = (int *)(*(aa + 1));
aa为数组名,在二维数组中即是第一行数组的地址,aa类型为int(*)[5],aa+1就相当于跨越了第一行数组,指向了第二行数组,等价于aa[1],通过转化为int*指针,ptr2-1指向如图所示:
所以解引用拿到的了元素5。
故最后打印结果为10 5
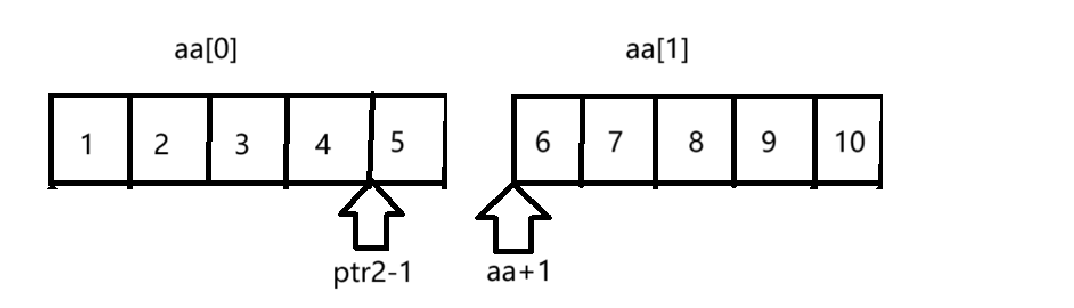

试题6:
#include <stdio.h>
int main()
{
char *a[] = {"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);
return 0;
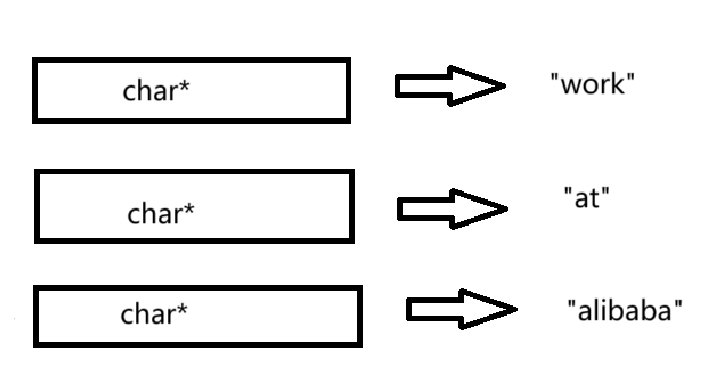
}如何理解 char *a[] = {"work","at","alibaba"};
我们以前讲过char *p="abcdef",这里的p指针就是字符指针,指向了字符串的首元素地址。
这里是一个字符指针数组,存放的是字符指针,比如第一个元素就是存放的指向“work”的指针,或则也可以说是“work”的首元素地址
char**pa=a,这是定义了一个二级指针,我们知道数组名是数组首元素的地址,这里拿到的就是字符指针数组中第一个元素的地址,pa++跨越一个char *元素,也就指向了第二个元素。
*pa就拿到了第二个元素,第二个元素是什么呢,是一个指向“at”字符串的指针,也就是说这里拿到的就是"at"的首元素的地址。
所以以%s形式进行打印,就打印了“at”这个字符串。

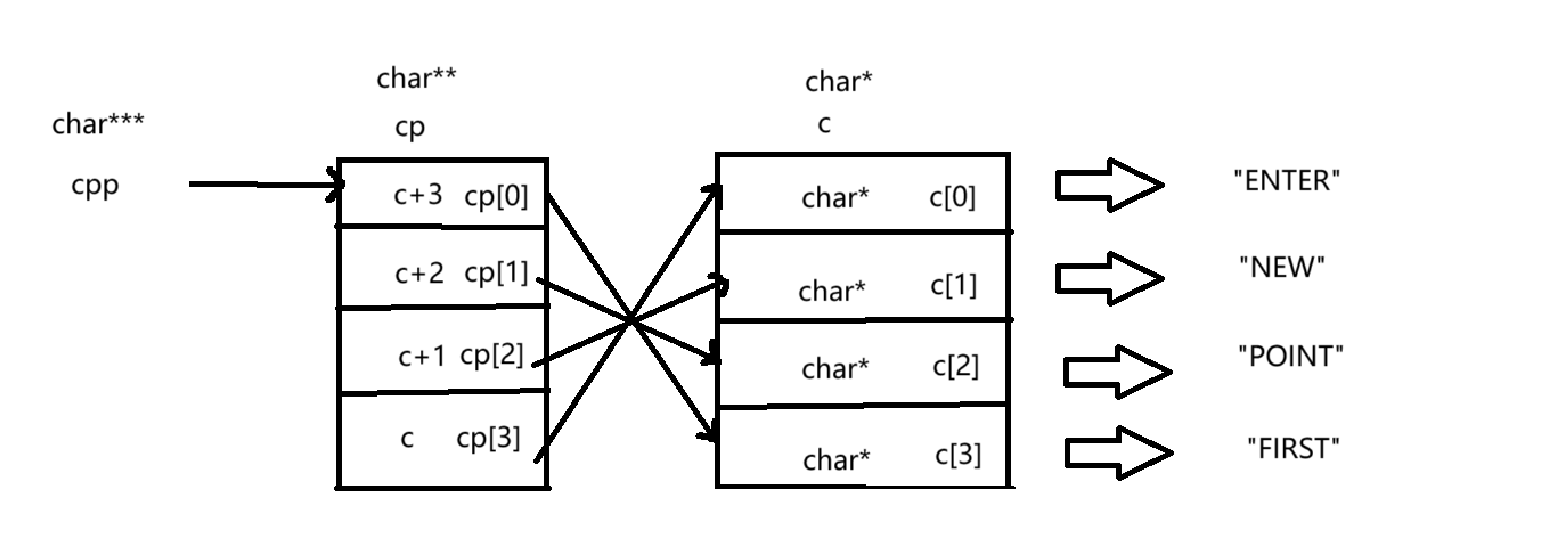
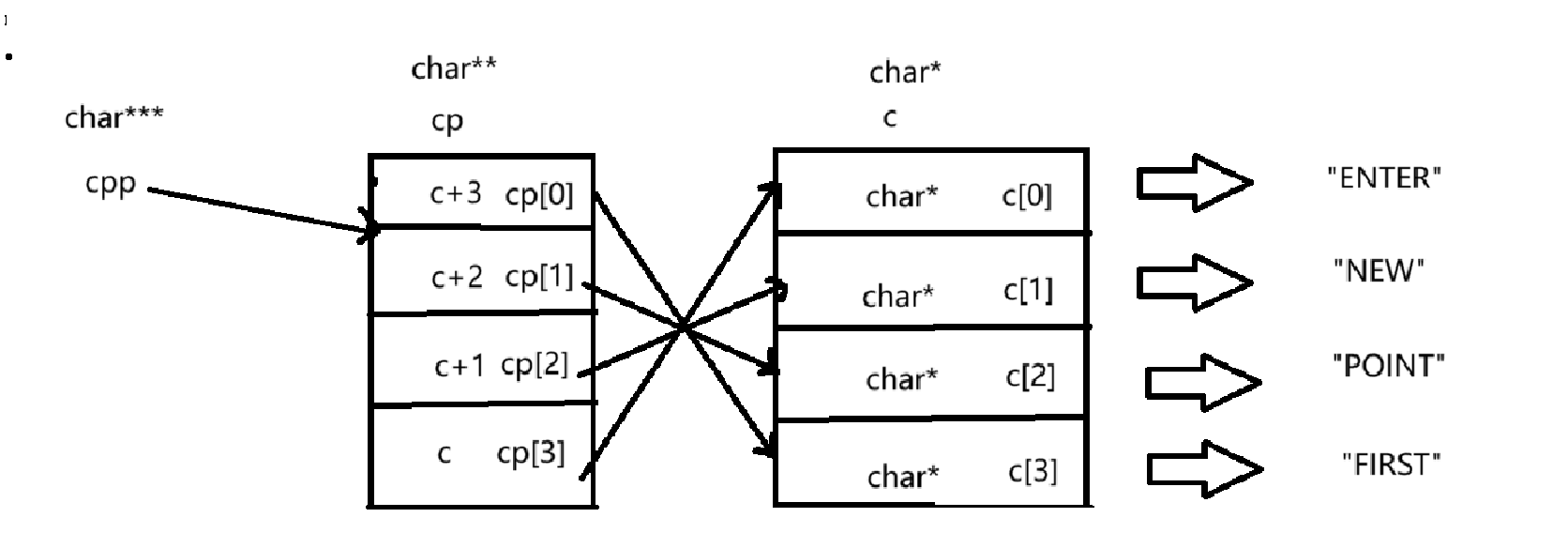
试题7:
#include <stdio.h>
int main()
{
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
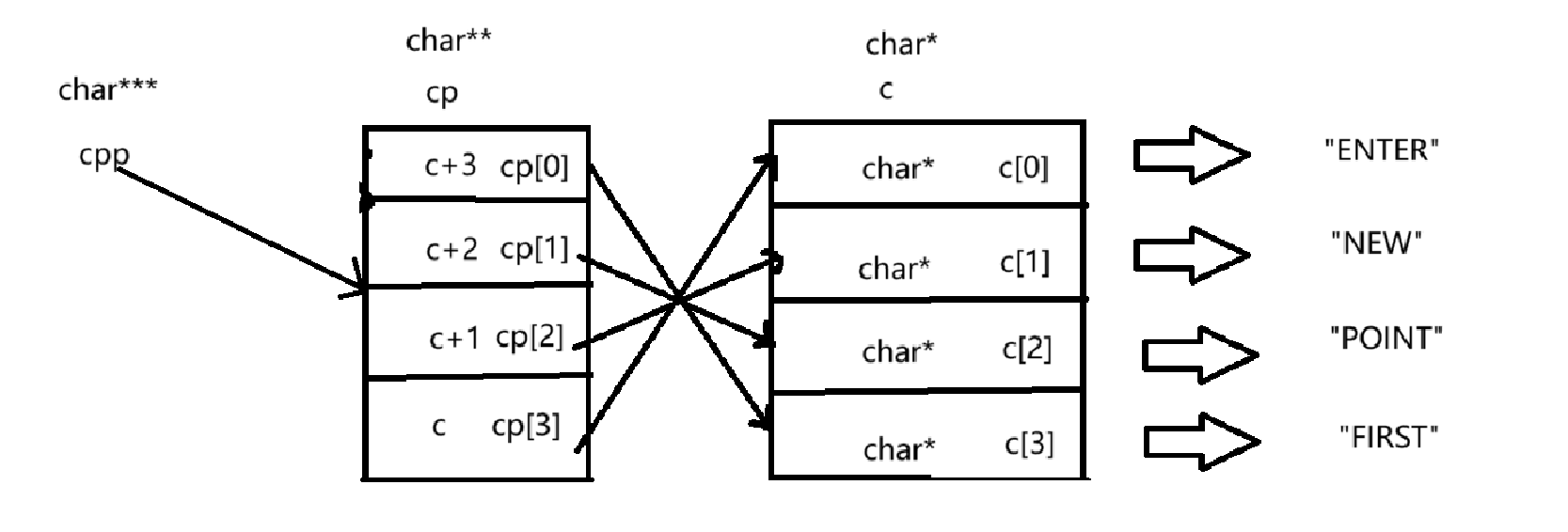
}char *c[] = {"ENTER","NEW","POINT","FIRST"};
这里定义的是一个字符指针数组
char**cp[] = {c+3,c+2,c+1,c},
这里定义了一个字符串二级指针数组,其中的元素就是指向char*c[]这个数组中的元素。
char ***cpp=cp;
这里定义了一个字符串三级指针,指向的是字符串二级指针数组的首元素。
由上一题的分析,我们可以画出指针指向的示意图:
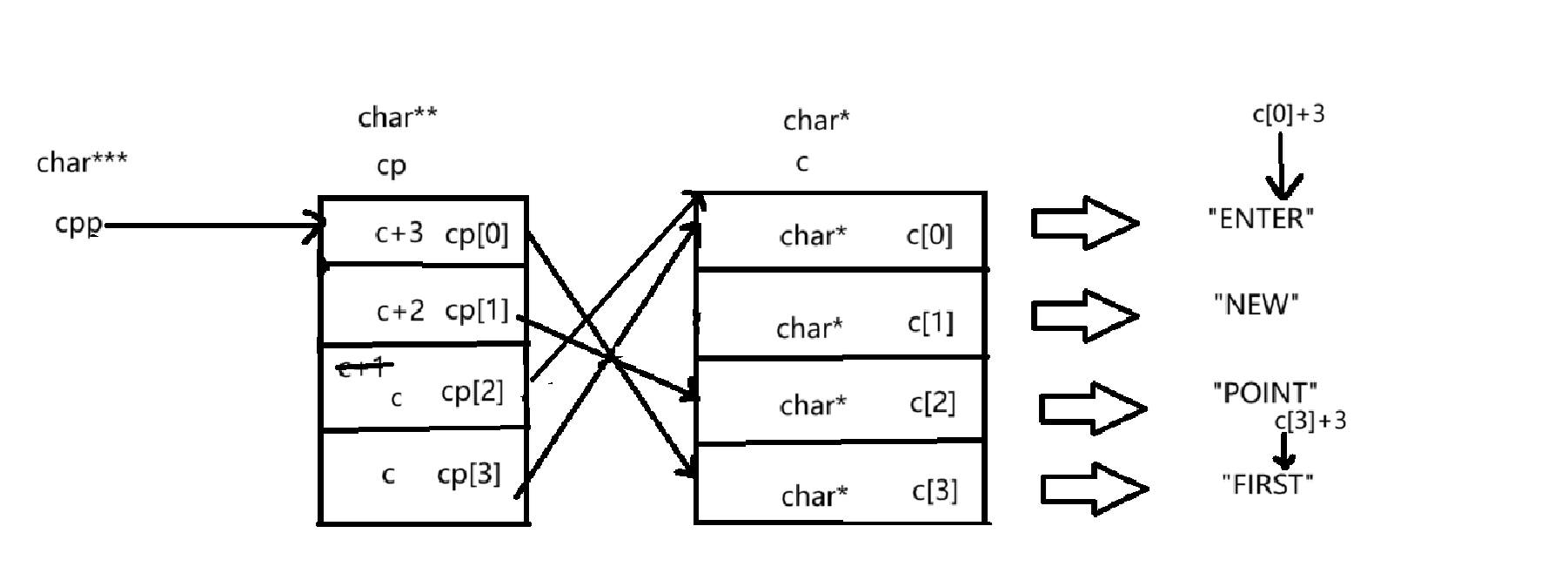
① printf("%s\n", **++cpp);
**++cpp:
按照这个顺序进行运算++cpp --> *(++cpp) --> * ( * (++cpp) )
++cpp后(cpp的内容就发生了改变),cpp指针由指向cp[0],转变为cp[1]如下图所示:
*cpp拿到了第二个元素,即cp[1],其中cp[1]的内容又是c+2,一个指向c[2]的指针
我们知道了(*cpp)是cp[1],是一个指向c[2]的指针,类型为char**,在对其解引用拿到的就是c[2]这个元素,c[2]这个元素的类型为char*,指向"POINT",即存放的是''POINT''这个字符串的首元素的地址,即'P'的地址
所以通过%s打印就会输出"POINT"。
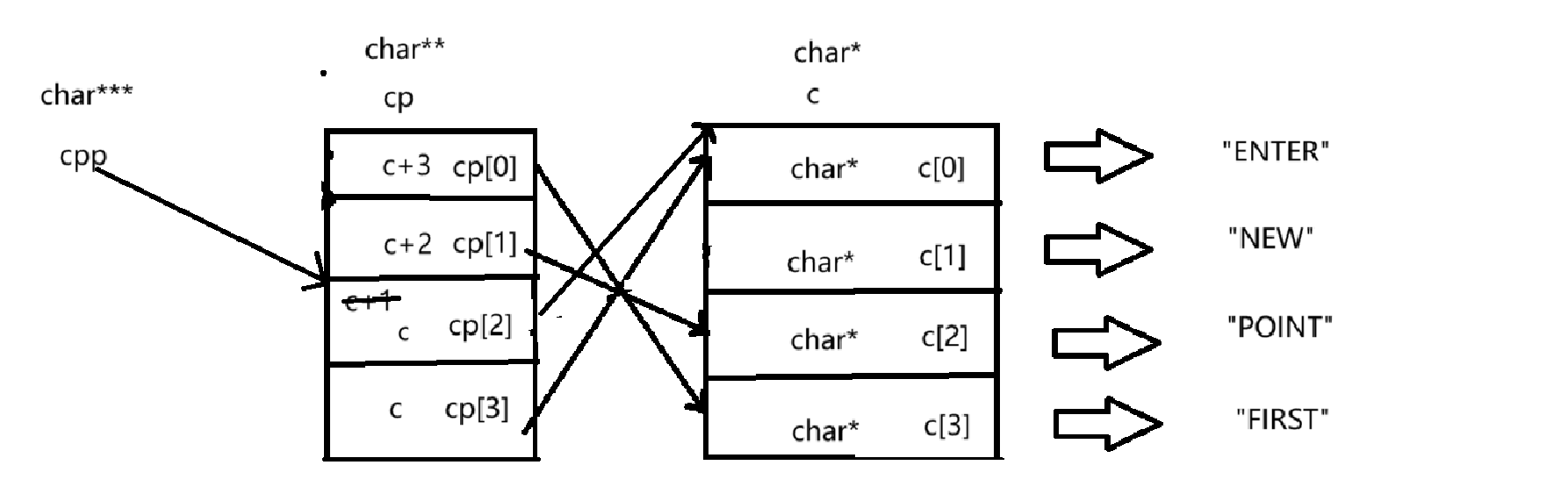
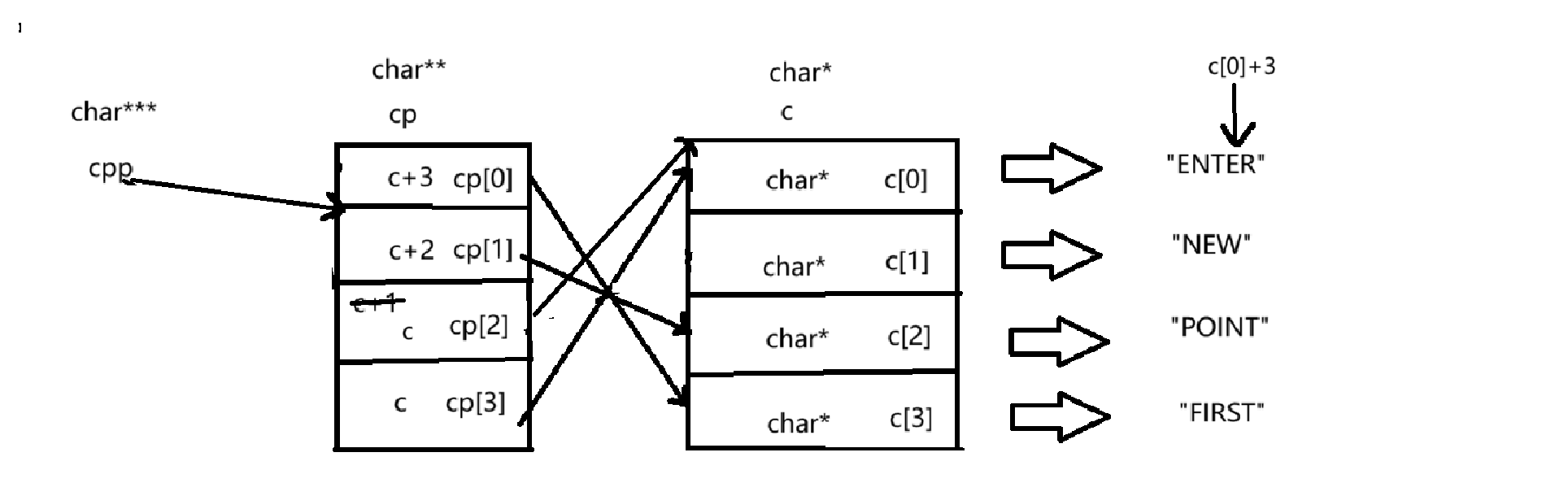
② printf("%s\n", *--*++cpp+3);*--*++cpp+3
剖析一下这个代码的运算顺序
++cpp --> *(++cpp) --> --(* (++cpp) ) --> *(-- (* (++cpp) ) ) --> *(-- (* (++cpp) ) ) +3
++cpp :
由于①中cpp已经前自增过一次,所以这里的cpp指向的是cp[1]
再次++就指向了cp[2],如图所示:
*(++cpp):
解引用拿到了cp[2]这个元素,cp[2]的类型是char**,存放的内容是c[1]这个指针的地址。
--(* (++cpp) ):
这里是对cp[2]的内容进行修改,即让c[1]-1,我们知道c[1]是char*类型,c[1]-1就指向了c[0],如下图所示:
*(-- (* (++cpp) ) ) :
cp[2]现在指向的是c[0],存放的是c[0]的地址,再通过解引用拿到c[0]这个元素,c[0]的类型为char*,指向的是“ENTER”这个字符串,存放的内容是"ENTER"的首元素的地址。
*(-- (* (++cpp) ) ) +3
我们知道了*(-- (* (++cpp) ) )拿到的是c[0]这个元素,存放的是"E"这个字符的地址,通过+3就会指向字符“T”后面的“E”如下图所示:
最后通过*s打印的结果就为“ER”。
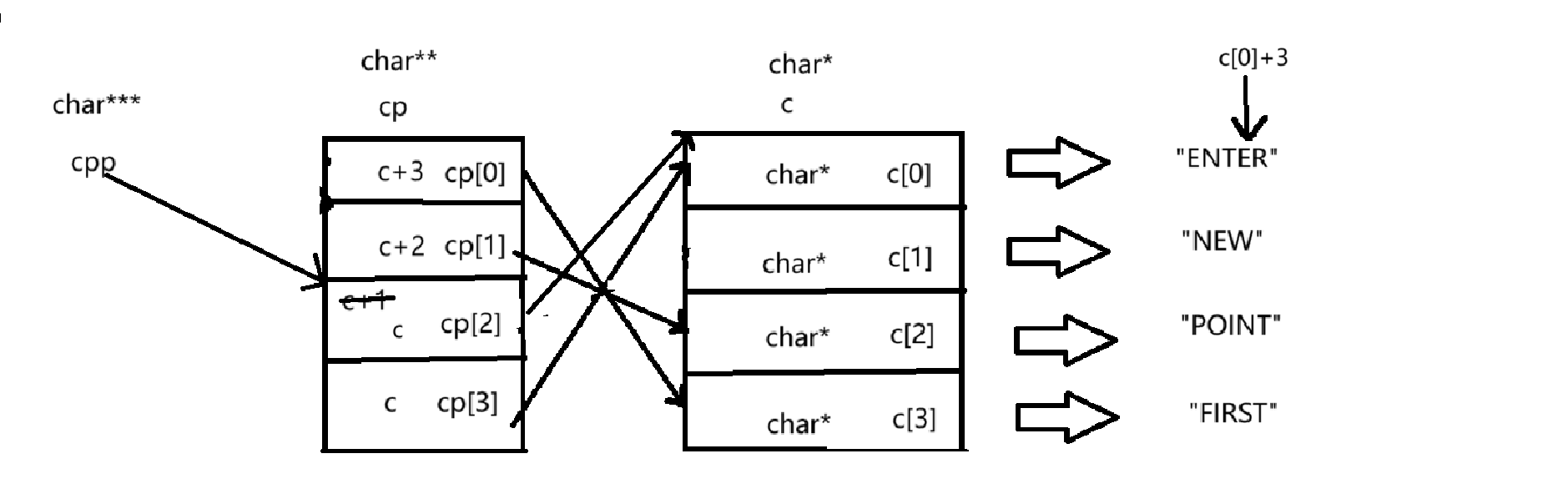
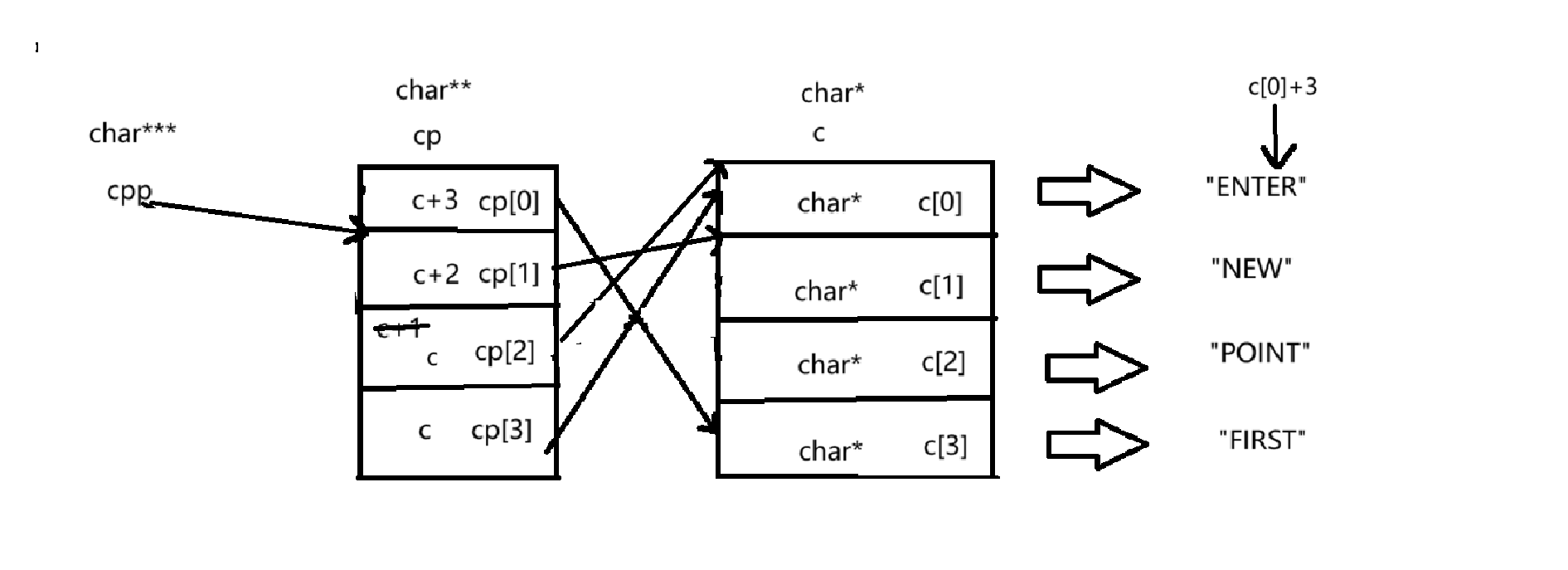
③ printf("%s\n", *cpp[-2]+3);*cpp[-2]+3:
*(cpp-2) --> *(*(cpp-2)) --> *(*(cpp-2))+3
*(cpp-2):
cpp-2:就指向了cp[0],但这里不会改变cpp的值,只有自增自减的情况才会改变cpp的值,所以如下图所示,*(cpp-2)拿到了cp[0]这个元素。
*(*(cpp-2)):
cp[0]的类型为char**,cp[0]指向的是c[3]这个类型为char*的指针,所以cp[0]存放的是c[3]的地址,通过解引用就拿到了c[3]这个元素。*(*(cpp-2))+3:
c[3]是一个字符指针,类型为char*,指向了“FIRST”,存放的就是"F"这个元素的地址,所以c[3]+3,指向了'S'这个字符,如下图所示:
最后以%s形式进行打印,所以打印的结果就是“ST”。
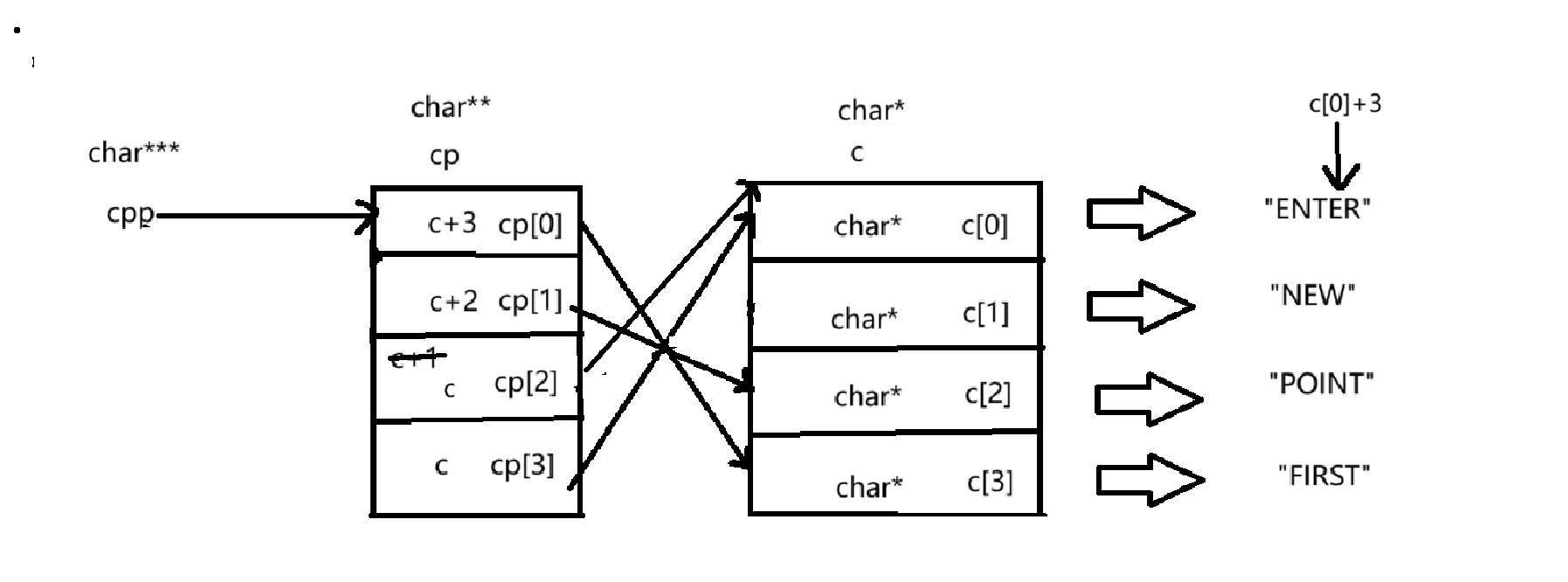
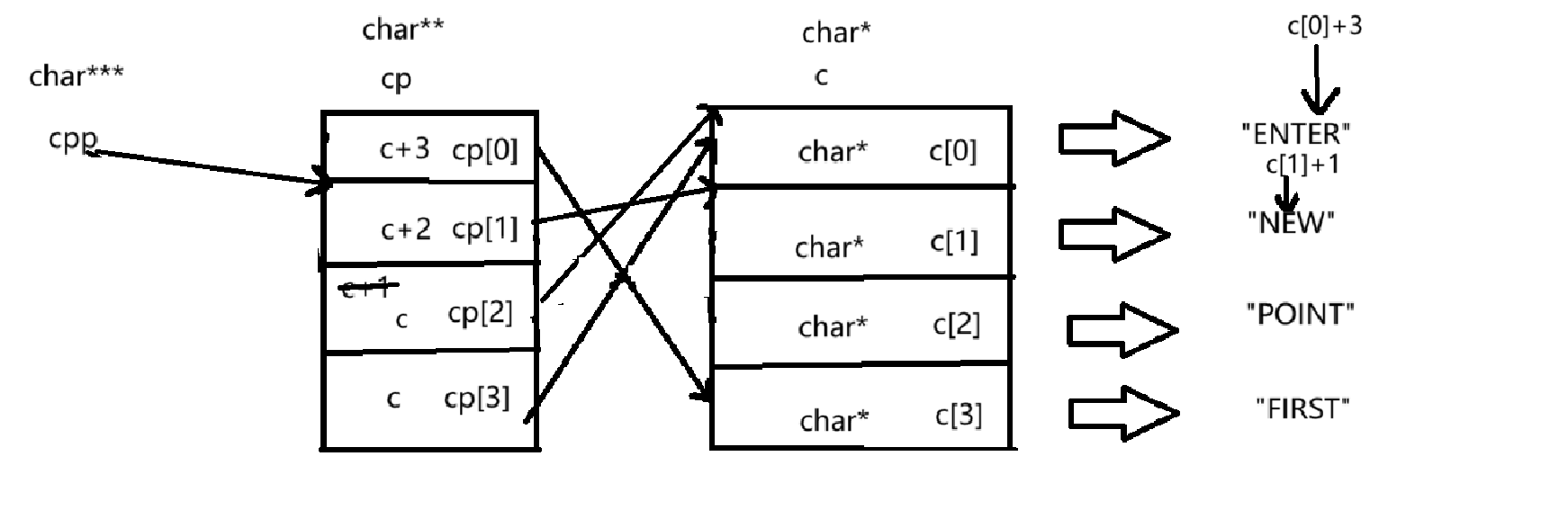
④ printf("%s\n", cpp[-1][-1]+1);cpp[-1][-1]+1:
*(cpp-1) ---> *(*(cpp-1)-1) ---> *(*(cpp-1)-1)+1
*(cpp-1):
cpp-1就指向了cp[1]这个元素,才通过解引用拿到的就是cp[1]这个元素
如下图所示:
*(*(cpp-1)-1):
cp[1]是一个char**的元素,指向的是c[2],存放的是c[2]的地址,cp[1]-1就相当于减少了一个char*字节的地址,指向了c[1],cp[1]通过解引用拿到了从c[1]这个元素。
如下图所示:
*(*(cpp-1)-1)+1:
c[1]+1就指向的是'E'这个字符。
如下图所示:
以%s打印的结果就是:"EW"。
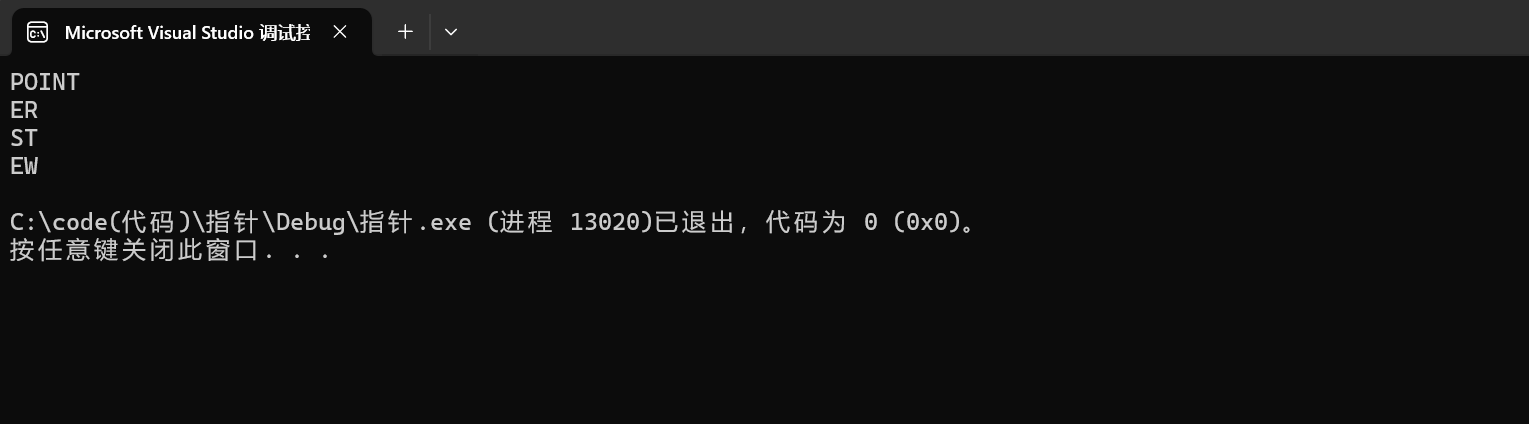
完,谢谢你的观看,都看到这里了,能有幸给个三连吗

















 2090
2090







 到【灌水乐园】发言
到【灌水乐园】发言







