




更多的程序员文章收录在
文章目录
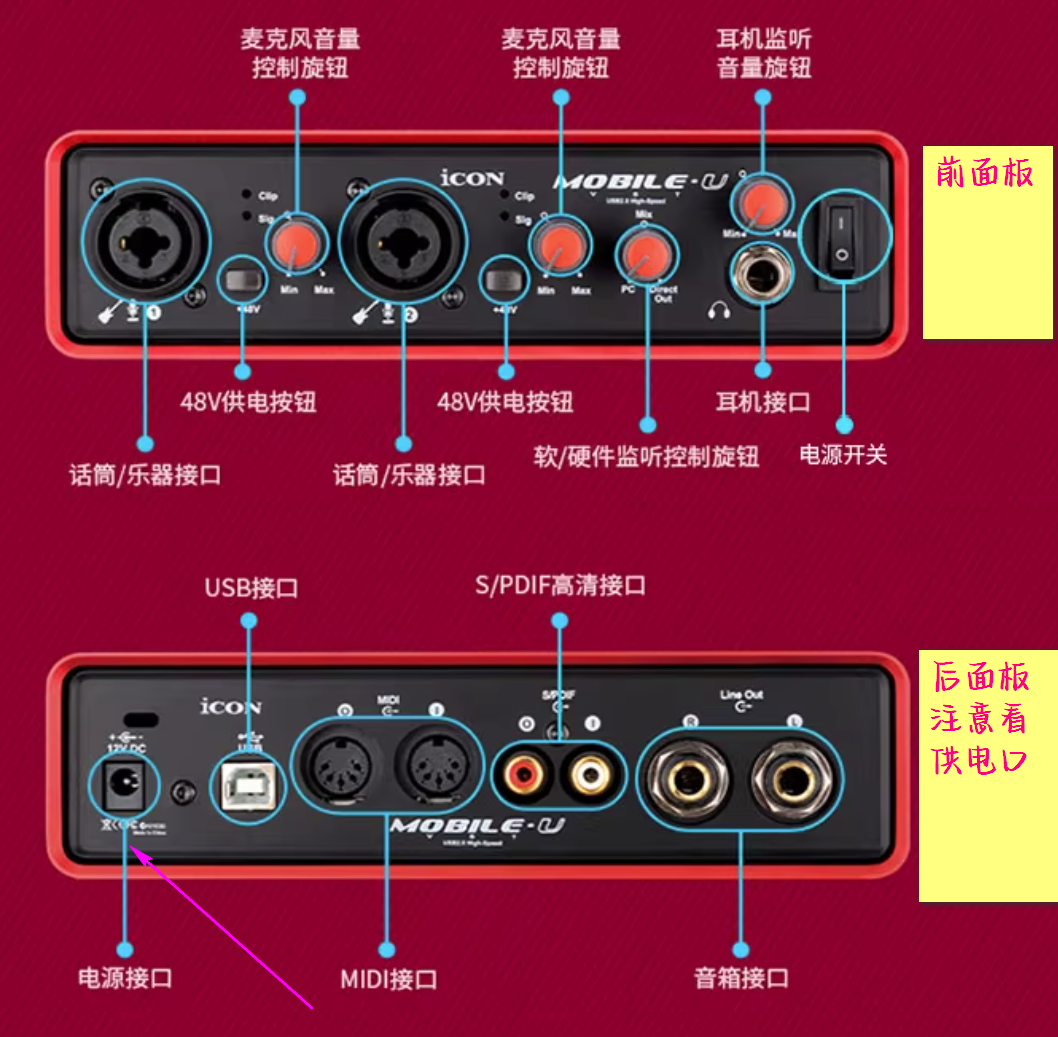
专业的录音要求:
先说一个studio one 一般来说,专业级的录音都会使用这个软件来录音。
==录小说交干音,一般要求底噪-55以下,人声-3到-6; ==
我之前也写过两篇文章:
【短视频】为什么做视频录音或有声书也需要机架–送studio one下载
如何用studio one机架录声音?
-55 以下是什么概念呢?
先来看一下我的降噪之后的效果。这属于勉强及格。
这个时候,周围2米之内电脑都不能开,尤其是桌面之上的电脑,我这台的主机放在了地面上。
电脑如果放在桌面之上,电脑的风扇与桌子之间就会有共振,而且,就算你感觉不到共振,那悬空的电脑的购房声音也比放在地上的要大。
说一句老实话,就算是你家空调来了,风大一点都有可能超过这个-55的概念
经过了周围声音的降噪之后
要注意的是,降噪只能降固定频率的声音,比如风扇之类,空调的风声,那种施工的一下“梆”,那里一下“叮”是降不了了。
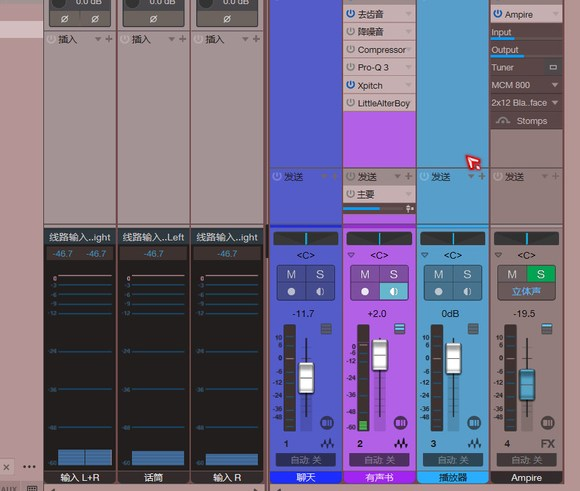
摇 手里的U盘与挂件的声音
也就是你着U盘,或钥匙,不然的话,你不注意都感觉不到的声音。
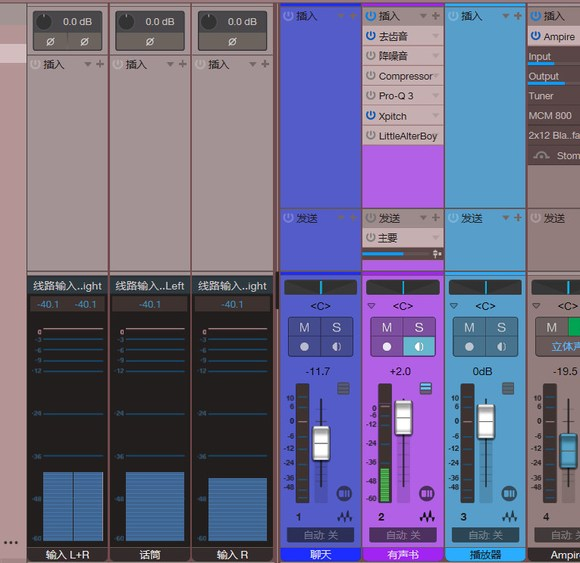
对着麦克风说话时
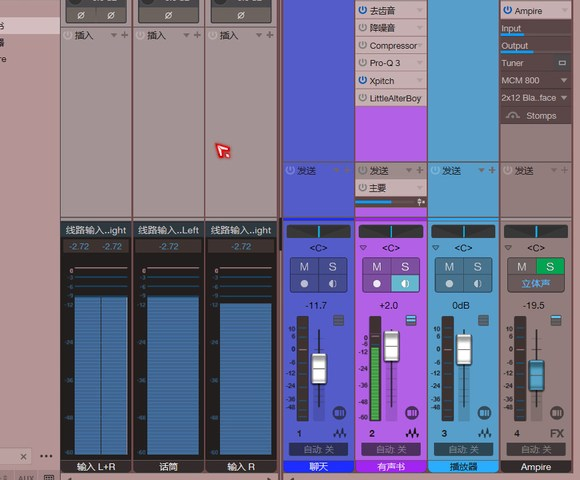
我的设备
声卡:其实这声卡毛病不少。属于一个改进的中间不稳定的版本
麦克风:Takstar/得胜 pc-k820金杯录音电容麦克风
防喷网:没有购买,自己做了个鱼缸的过滤棉,剪刀修了下


声卡不如新的五代声卡
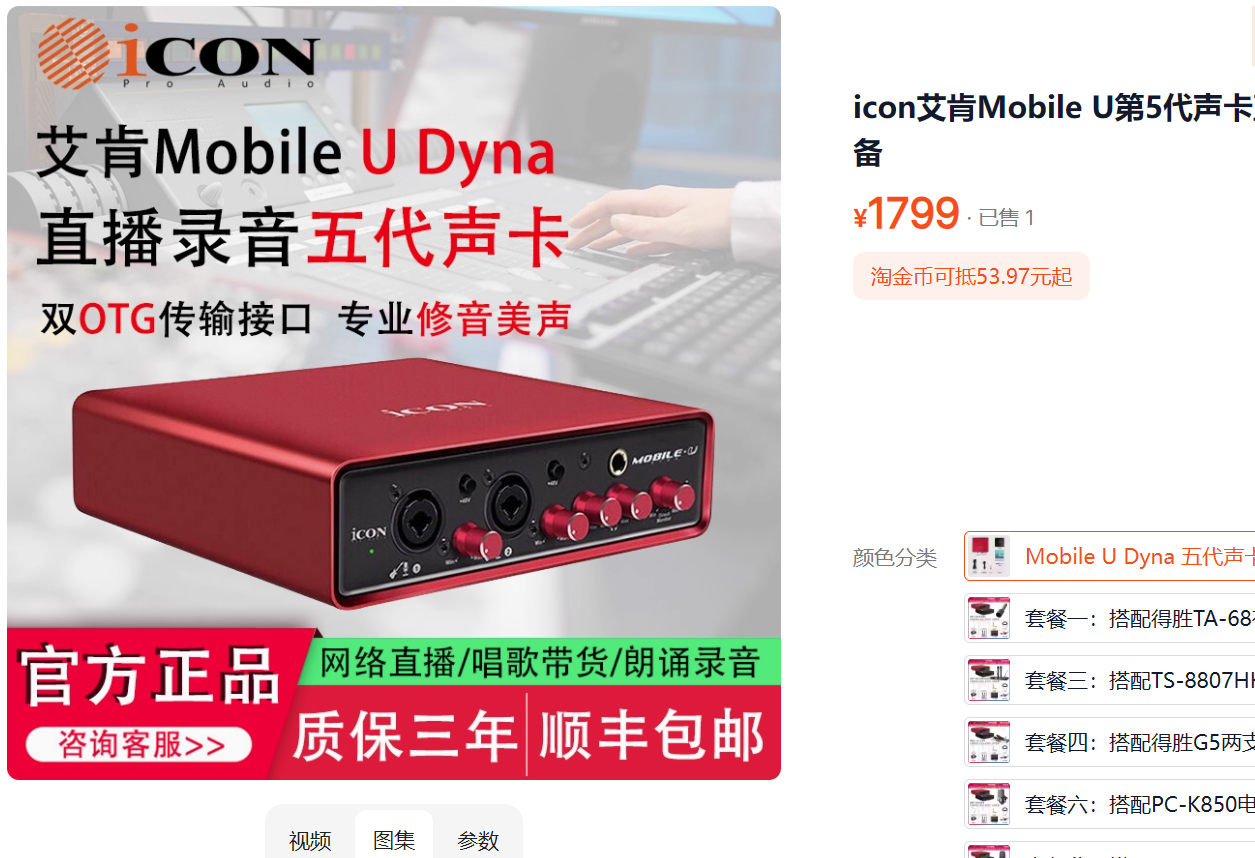
跟老的一代声卡的差别:
主要就是供电。
下图是老式的mobile u 的声卡的供电,就是用的普通变压器单独供电。
这种反而还稳定一些。
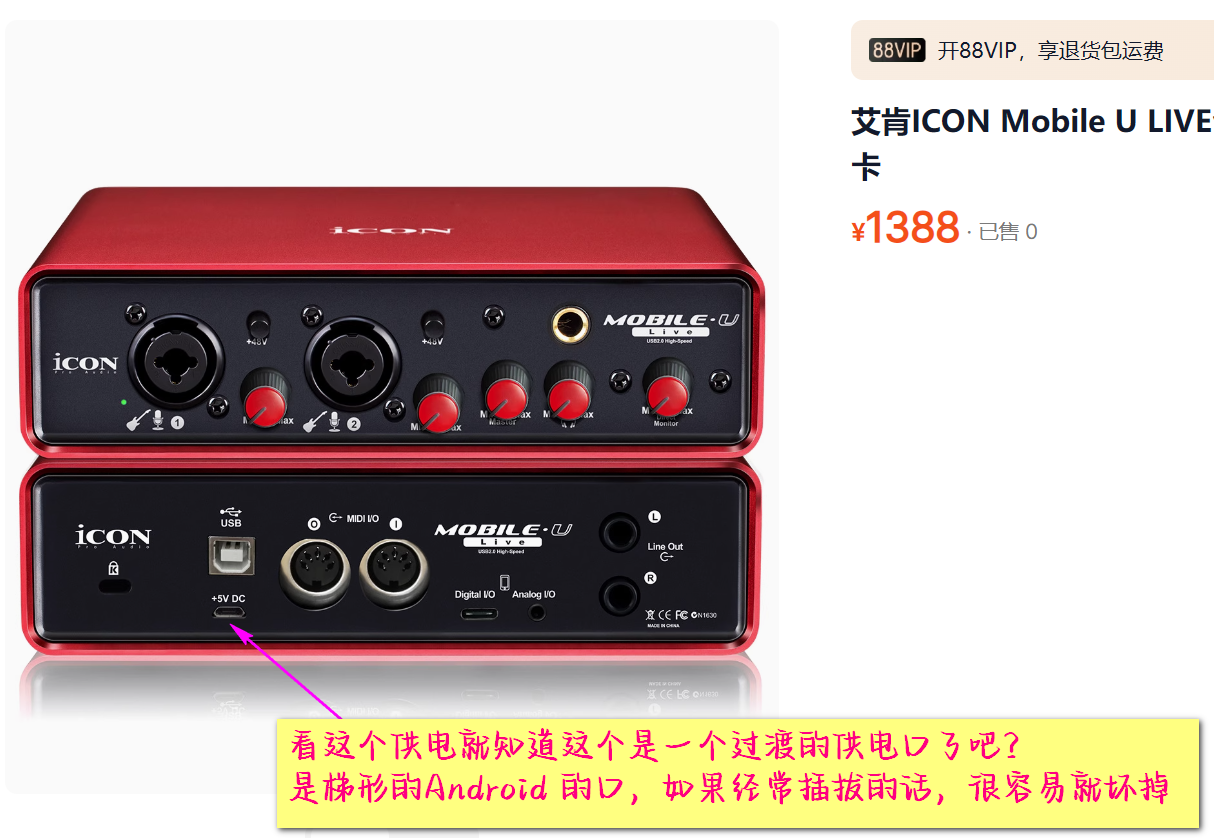
当然了,也不是没有解决的办法:

声卡的选择误区:
声卡的选择误区
1 直接USB联电脑,不用外接电源。
一个是这种要看你的电脑主板的情况,另一个问题就是你一个变电器多少钱?不到20元,你一个主板要多少钱?5V供电稳定,足够的主板,至少得1000元了吧?
所以,供电与信号一体的声卡其实只是你感觉上方便,但是整体算下来可能没有那么的“想像中的好”
2 麦克风推力
这个词如果你经常刷B站的视频就知道了。好一些的麦克风基本上都是48v 供电的,别误会这个48V其实是一个电容电端,并不是真电压,所以叫48v 幻象供电。
那不是就没有推力的问题了?这个问题的根源是麦克风内部也是有电路的。
所以,当你的声卡提供的电流过小的时候,麦克风的表现就不足了。
这也就是为什么很多人说德胜的麦克风“好推”。
其实根本原因就是德胜的麦克风的电路元件要少一些。
当然了,也不能从电路的元器件的多与少来衡量一个麦克风的好坏。
不过一个元件没有的麦克风那肯定是假货。
LGT240麦克风拆解
拆解得胜PCK200麦克风


这也是为什么专业的录音室一般都在要公司的录音室里。
下图为一般的录音环境,墙壁加了吸音板

有一些要求高的,甚至地板都用了软质材料。
更加专业一些的录音室,不只是墙壁加了吸音板,连天花板也加了吸音板。地板也铺了软质材料

录音的市场
2025年录音行业呈现高速增长态势,核心驱动力来自AI技术赋能、硬件创新及声音经济新业态的爆发,全球AI录音设备市场规模预计突破5亿美元,中国AI配音与录音结合市场达100亿元。
市场规模与增长
全球市场:2025年全球AI录音设备(含录音笔、智能耳机等)市场规模预计突破5亿美元,年增长率约8%;AI语音转录与内容整理市场(含软件服务)规模达30亿美元,中国占比25%。
中国市场:
AI录音笔年均增速超30%,主要受益于商务会议、教育及媒体需求。
AI配音+录音结合市场(如短视频、有声书)2025年规模预计100亿元,年复合增长率35%。
技术驱动与产品创新
硬件智能化:
AI录音笔集成实时转录与大模型摘要功能(如GPT-4o),支持脑图生成、多模态交互(如AR/VR空间音频)。
外挂式设备(如iPhone磁吸录音卡)解决通话录音痛点,年销量超10万台。
软件服务升级:
AI与人工混合模式普及,多语言及方言支持需求激增(如川渝方言单日调用量超200万次)。
云端协作成为标配,录音内容自动同步至团队共享平台(如讯飞听见)。
应用场景与需求分化
企业端(B端):
会议记录自动化节省80%人力成本,AI外呼机器人日均拨号3000+次。
影视/游戏配音中AI初配降低成本70%,但高端内容仍依赖人工。
个人端(C端):
短视频创作者推动方言AI配音需求,学生/记者依赖实时转写工具(如讯飞录音笔)。
降噪插件有哪些?
降噪插件主要包括以下几类选择:
原生:一般都是软件或买声卡自带
第三方
Waves Clarity Vx
采用AI算法分离人声与噪声,对空调声、键盘声等背景杂音抑制效果显著,适合后期精细处理6。
Cedar Audio Screenvox
高频降噪能力突出,界面简洁,适合处理麦克风啸叫或齿音伴随的噪声2。
PSEMono
零延迟设计,直播场景首选。需注意配置话筒灵敏度避免过度抑制3。
操作建议
强度控制:唱歌时降噪强度需低于说话场景,避免人声音频断层1。
音质平衡:优先使用原生插件初步降噪,再通过Waves等工具补充处理,减少音损16。
原生插件方案
Expander Noise Gate(自带降噪门)
核心参数:
THRE(阈值旋钮):控制降噪强度。建议先找到噪音消失的临界点(如40dB),再增加5dB缓冲值避免音质损失1。
HLT(恢复时间旋钮):消除尾音残留噪音,取值5-8效果较佳1。
适用场景:直播、人声录音等实时处理,兼顾效率与音质保留1。
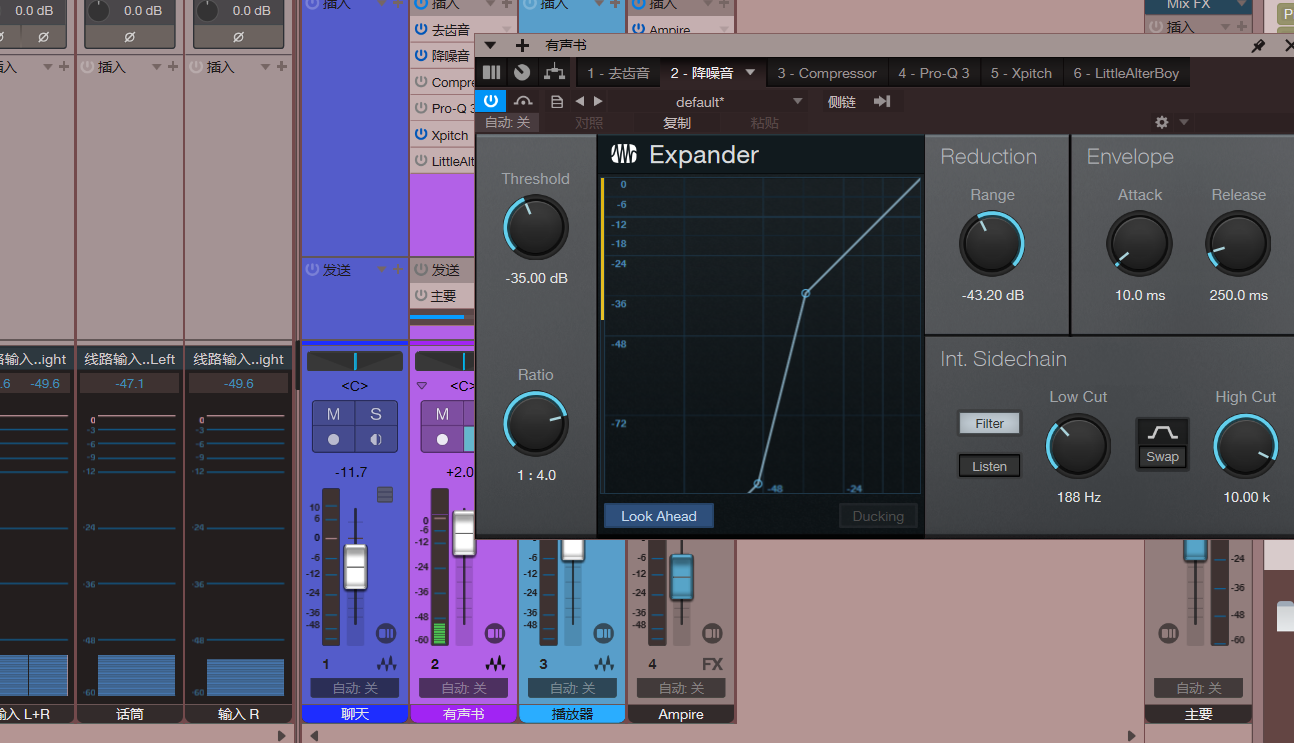
艾肯原生的降噪
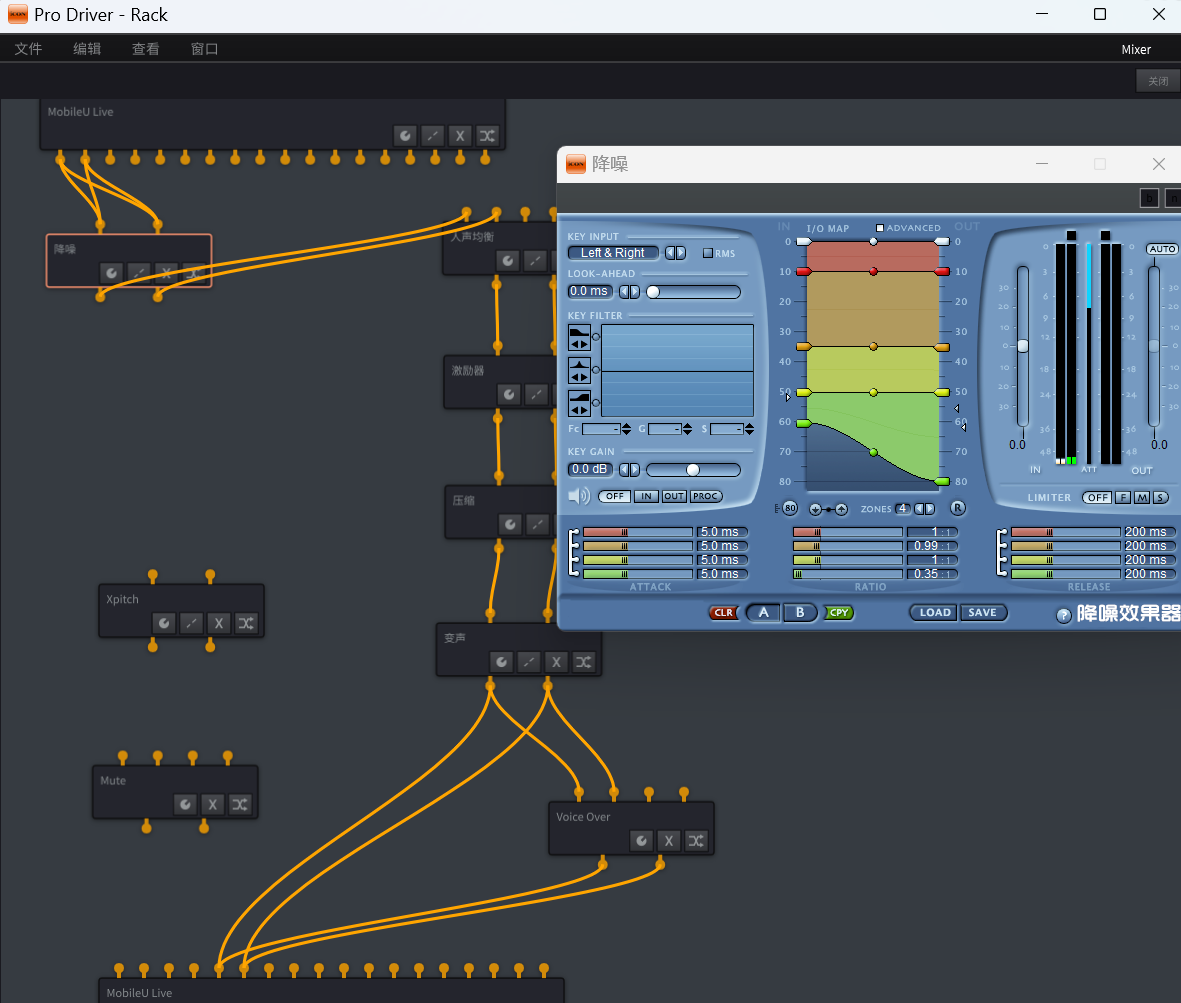
降噪插件的原理
就是多少DB以下的声音,变得更小,0.5:1 就是让你的噪音变成了一半的噪音
再小的,直接切掉,变成了零。
隆重推荐 X-noise降噪插件
因为只有这个降噪插件做到了AI学习,然后再智能降噪。
X-noise降噪插件功能介绍
Waves 插件包,俗称“水星包”、“水银包”插件。
是一款集合了大量VST插件的音频处理插件合集。
X-noise是Waves中实用性较高,应用范围较广的一款降噪插件。
本文将就该款插件的功能与使用方法进行介绍。
一、界面介绍
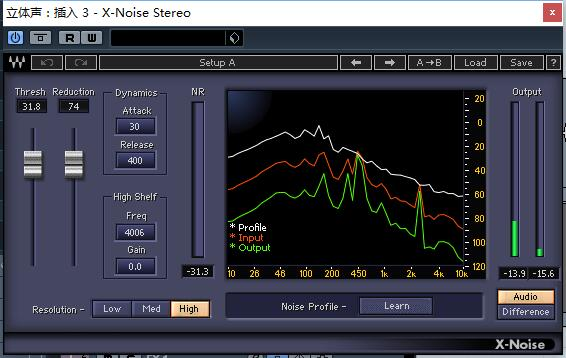
下图为X-Noise Stereo的插件界面。
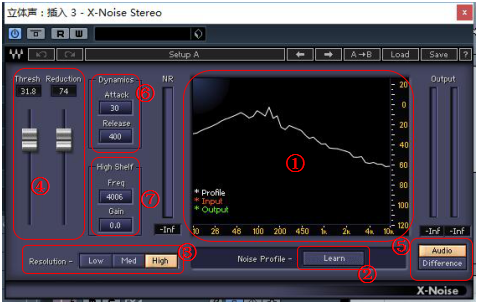
X-noise降噪插件功能介绍
注:Stereo意为“立体声”。说明该插件适合为立体声音轨提供插件效果。
同时单声道版本则为“X-Noise mono”适用于单声道音轨的音效处理。
①频谱仪
② Learn(采样)
Attack(冲击)和Release(释放)
③ Resolution(分辨率)
Freq(频率)和Gain(增益)
④推子
Thresh(阀值)和Reduction(衰减量)
⑤监听切换按钮
Andio和Difference
⑥ Dynamics(动态)
⑦ High Shelf(高频滤波)
以上为我们在做频谱处理时较常用的几个功能模块。
二、功能详解
①、频谱仪
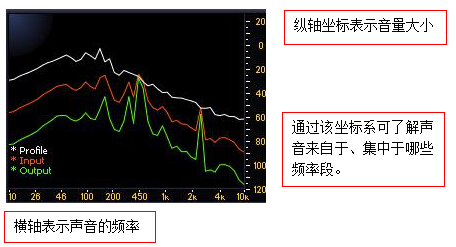
频谱仪是将当前播放的音轨声音进行可视化处理的区域。
通过使用频谱仪我们可以真正意义上地看到声音的形状。
同时我们也通过查看频谱仪来了解我们对音轨做出了哪些修改。
②、Learn(采样)
采样按钮是对输入波形进行记录的功能按钮。X-noise降噪插件功能介绍
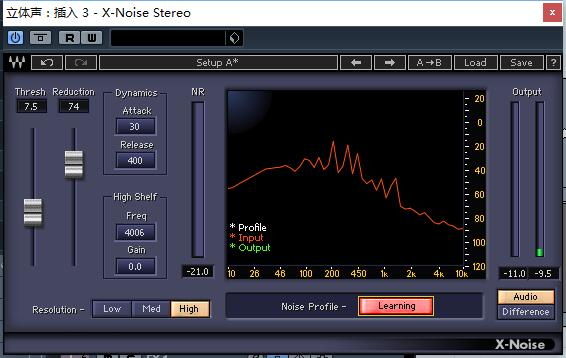
当我们刚插入该插件时,插件处于未工作状态。
此时我们进行当前音轨的播放,在频谱仪上会显示代表了Input(输入)的红色音频波形。
通过观察红色的波形,我们就可以了解到在音频未被处理时的即时状态。
点击Learn按钮,插件会对当前的即时音频波形进行采样。(如图)
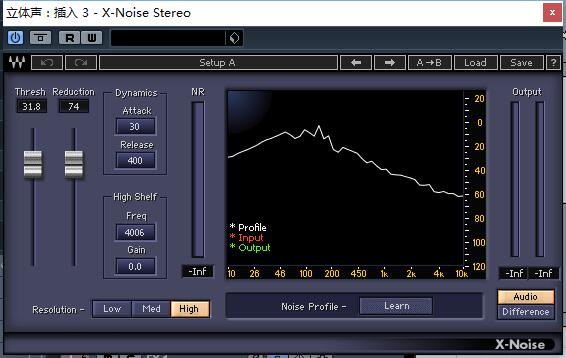
完成采样后,频谱仪上会出现代表Profile(采样剖面)的白色波形。
该波形会保持静止,即使你停止走带也不会消失。
而此时当你开始走带(录音)时,则会出现代表Output(输出)的绿色波形。
注意:采样时机与噪音样本
我们进行录音工作时,都会先录制一份噪音样本。
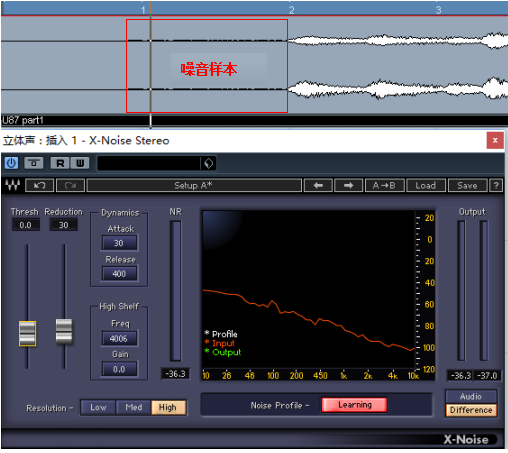
噪音样本的录制方法非常简单,就是将录音设备开启后什么都不做。让其将环境中长期存在的噪音录入进去。成为噪音样本。
图中的红线是典型的环境噪音所产生的音频波形。此时音轨所播放的,正是噪音样本的片段。
降噪插件只能对长期稳定存在于录音环境中的噪音起效。对于那些短促的,突发性的噪音则不具备有效的降噪能力。
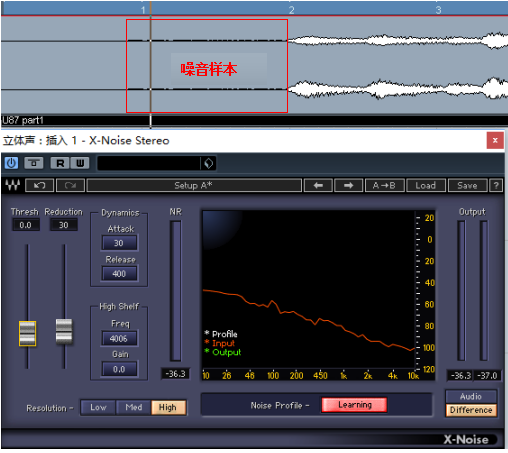
采样完成后,频谱仪内噪音样本采样(白线)与正式录音片段(绿线)的对比图。
③、Resolution(分辨率)
分辨率代表了插件在处理时的精细度。
分别有低、中、高三种模式可以选择。
越高则处理效果越好。
不过相对应的会占用更多内存,在轨道数不多的时候,使用“high”模式对于一般电脑来说都没有什么压力。
④、Thresh(阀值)和Reduction(衰减量)
调整阈值大小,是我们实现降噪效果的最主要手段没有之一。
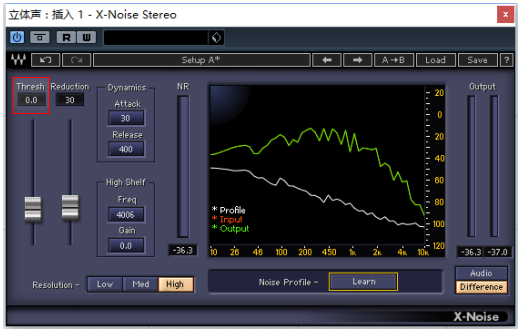
当阈值调整为零时,我们可以看到频谱仪上只显示了绿线与白线。
这是因为此时并没有任何的声音被消除,所以输入=输出。
绿线与红线处于重合状态,在频谱仪上表示为只显示绿线。
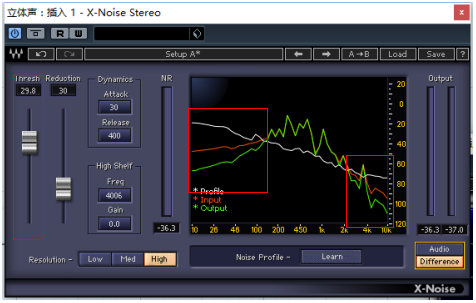
当我们开始提升阈值,频谱仪上的白线也会随之向上平移。
此时我们会发现,当采样波形(白线)移动到高于输入波形(红线)的位置时,输出波形(绿线)与输入波形(红线)呈现出明显差别。表明降噪插件已经成功消除了该区域内与噪音样本类似的声音。
而白线低于红线的部分则不会工作,该区域内的输入波形与输出波形依旧保持重合状态。
注意:当我们不断提升阈值时,我们会明显听到被消除的声音越来越多。
过高的阈值会将正确的声音与噪音一同消除,使得原本我们想保留的声音缺频。产生明显的“失真”现象。
因此,我们在调整阈值时一定要适度,不能过高,也不能过低。
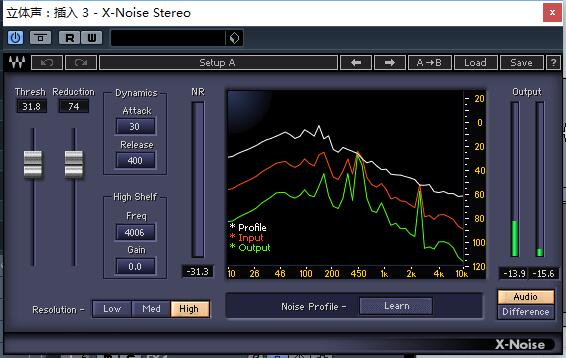
当阈值过高时,我们可以明显看到几乎所有的频段都受到了影响。
Reduction(衰减量)
如果阈值代表了消除音频的范围,那么Reduction(衰减量)代表了该范围内声音的衰减程度。
提升该数值,可以在范围不变的情况下消除更多的声音。过多地提升衰减量同样也会带来失真。
⑤、监听切换
监听切换是一个非常方便的功能。
在插件正常工作的情况下,我们通过Audio模式听到的,是噪音被去除后的声音。
但相对于处理后(保留下来)的声音,我们有时候更需要了解究竟哪些声音被去除了。
这个时候可以通过切换到Difference模式来达成这一目的。
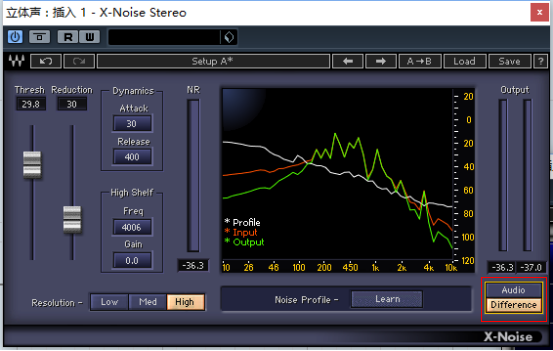
当切换到Difference模式时,我们就可以只听到被消除部分的声音。
在该模式下如果你听到了你不想去除的声音,说明你的阈值过高,将非杂音部分也进行了消除。这往往会使得降噪后的声音出现失真。
⑥、Dynamics(动态)
动态指的是效果器工作的“淡入”与“淡出”程度。
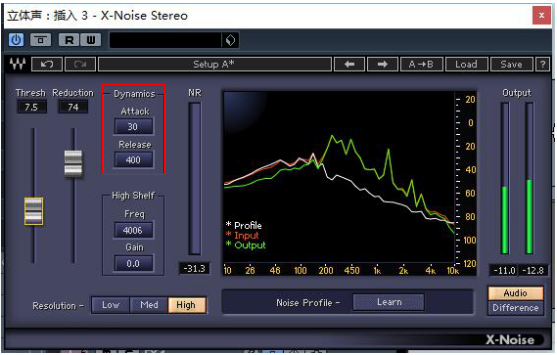
Attack指的是效果器从不工作到工作所消耗的过渡时间。
Release指的是效果器从工作到不工作所消耗的过渡时间。
两者的数值会对音频的听感产生影响。
数值越小,则声音听起来越坚硬有力,比较适合力度感强,速度快的音乐音效。
反之,数值越大,则更适合用于处理舒缓,轻柔的音乐音效。
对于初次接触音频后期的朋友来说,Dynamics的调整并非降噪插件使用中必不可少的一环。
一般我们会在使用压缩效果器的过程中熟悉并掌握关于Dynamics的使用技巧。
⑦、High Shelf(高频滤波)
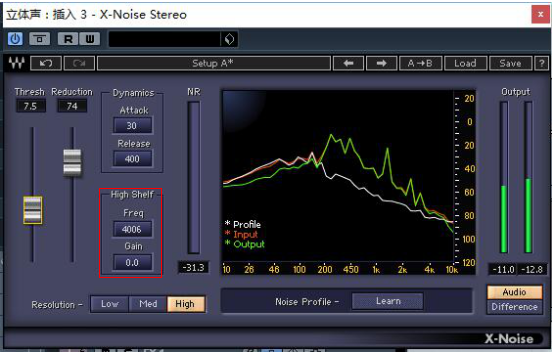
该功能是对你设定的目标频率(Freq)以上的所有频段进行更强效的降噪处理。
置于加强多少,则是通过增益(Gain)功能来进行设置的。
增益功能也可以提供一定的减益效果,让你选定的频段范围获得较少的降噪处理。
如果你是第一次见到这个词,不是很能理解上面的内容。
那么请你当做没有这个功能。
没有它,你也已经可以很好地完成简单的降噪工作了。
而想要使用它,在了解理论的基础上,你还必须有足够多的经验来帮助你进行判断。
胡乱使用只会让一切变得更糟。
结语
当然,想要真正用好这款插件,还需要更多的实践操作积累经验。当你真正掌握了X-Noise的全部能力之后,这款优秀的插件一定能为你的音频后期实力增光添彩。
总结及资源下载
张雪峰老师:解释滑档和退档,希望各位家长注意!
提示:这里对文章进行总结:
如果已经录取了,那么假期里学学C语言吧。
资源下载:
C语言的两大开发工具CodeBlocks/DEVC
只有大一的基础扎实了,你才有未来。否则,不管是上研,还是去工作,都是要C语言的底子的,甚至公务员的题,不也是逻辑题占大半么?
把一本书的所有的C代码全打一遍够不够? 远远不够。
这只是小学生,甚至还不如小学生的水平,因为小学生从小学三年级,四年级就开始找一本书敲代码了,而且,人家还是一对一的老师辅导。
什么时候,把力扣上面的中级题目刷完100道了。不用上网,自己能哗哗的写出来,就像蓝桥杯那样。你的C语言就可以为你的大学四年的计算机学习打下基础了。
选择了也要努力,没有远虑必有近忧!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











