




前言:本文篇幅稍长,但深入阅读将助你全面掌握指针的核心概念。
“行百里者半九十” ———《战国策》
一、浅谈内存与地址
1.对于地址的理解:
在计算机科学中,指针是一种重要的概念,它直接操作内存地址。要深入理解指针,对于地址和内存的理解就密不可分,对于地址的理解:我们可以先从生活中的案例起手了解,比如我们熟悉的宿舍,每一栋楼层每一个房间都有自己的编号划分,这样宿管阿姨就能精准到找到我们的宿舍。
1.一楼:101 102 103 104 105
2.二楼:201 202 203 204 205
3. ......
2.对于内存的理解:
内存(Memory)是计算机系统中的一种关键硬件组件,用于临时存储数据和指令,以便处理器能够快速访问。它是计算机运行程序和处理数据的基础,简而言之就是储存数据与指令的一个中枢。
计算机的CPU(中央处理器)在处理数据时,需要从内存中读取所需数据,处理完成后再将结果写回内存。当我们选购电脑时,常会看到8GB、16GB、32GB等不同容量的内存配置,这些内存是如何实现高效运作的呢?
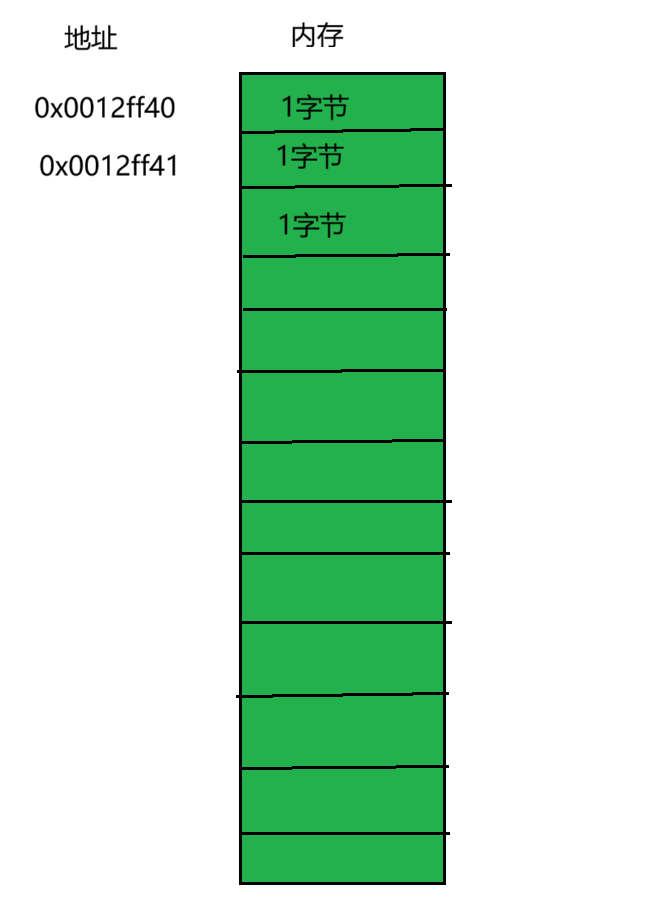
计算机内存地址的概念与宿舍编号有异曲同工之妙。正如每个宿舍房间都有唯一的编号以便管理和定位,计算机内存中的每个存储单元也通过唯一的内存地址进行标识,确保程序能够精准访问所需数据。
实际上,计算机将内存划分为若干个存储单元,每个单元的大小固定为1个字节。这种精细的划分方式为数据的高效存储和访问提供了基础。
二、初识指针
在日常生活中,我们习惯用门牌号来标识具体位置,而在计算机领域,内存单元的编号同样被称为地址。在C语言中,这种内存地址被赋予了一个专门的术语—指针。
三、指针变量和地址
1.指针变量的定义
#include<stdio.h>
int main()
{
int a = 20; //定义整形变量a,向内存申请一块空间存储20
int* pa = &a; //取出a的地址并存储到指针变量pa中
printf("%p\n", &a);
printf("%p\n", pa);
return 0;
}
以整形指针为例,&a拿到a的地址,⽐如:0x0021ff66,这个值也是需要存储起来为方便后面操作,那我们存放在哪里呢?
答案是:指针变量pa中。指针变量也是一种变量,专门用于存储指针-----地址。
2.拆解指针类型
我们看到pa的类型是int *,该如何正确理解这个数据类型呢?
1 int a=20;
2 int* pa=&a;
不妨拆开来理解,这里pa左边有一颗*,这颗*说明pa是指针变量,而*前面的int说明pa指向的是整 形类型(int)的对象a。
3.简述指针类型
1.char* //---字符类型的指针
2.short* //---短整型的指针
3.int* //---整形的指针
4.float* //---单精度浮点型的指针
5.double* //---双精度浮点型的指针
4.一个特殊类型
1. //特殊类型的指针---泛型指针(void*)
2. //温馨提示:void*的指针不能直接进行 "指针的+-操作和解引用操作"
3. void* ;
四、指针变量的操作
1.初探解引用操作
经过上面的了解我们以及明白了如何去定义和保存地址,但是我们将地址保存起来,目的是为了更好的使用它,那么如何去使用呢?
在现实生活中,我们找到了通过地址找到了宿舍,但因为有门锁的原因我们不能直接进入宿舍,所以我们需要一把钥匙去打开这个房门,从而去拿取房间内的物品,在c语言中其实也一样,我们可以通过所存储的地址去找到地址所存储的对象,而这里我们需要去学习解引用操作符---房门的钥匙。
#include<stdio.h>
int main()
{
int a = 10;
int* p = &a;
*p =0; //通过解引用找到a,并将a的内容改为0
printf("%d", a);
return 0;
}
这里通过解引用操作符“ * ” 来进行操作,*p的意思是通过p的所存储的地址找到p所指向的对象,其实这里的*p相当于a了,可以通过*p来改变a的值,这里看似多此一举,有点脱裤子放屁的感觉,但实际上,通过指针解引用还是有很大的用处,请听我娓娓道来。
2.指针的大小
前面我们已经知道了指针与地址密不可分的关系,为了在计算机中高效管理内存,硬件设计提供了专门的机制:地址序列的生成是通过专门的硬件电路——地址线来实现的。
在计算机系统中,32位或64位机器的本质区别在于其地址线的数量——分别对应32根或64根地址线。它们的工作原理实际上就是通过32根地址线/64根地址线所产生的0/1的电信号来形成数字信号,那我们就把32位/64位二进制序列来当作地址序列。
- bit 1byte=8bit
- byte 1kb=1024byte
- kb 1mb=1024kb
- mb 1gb=1024mb
- gb 1tb=1024gb
- tb 1pb=1024tb
- pb
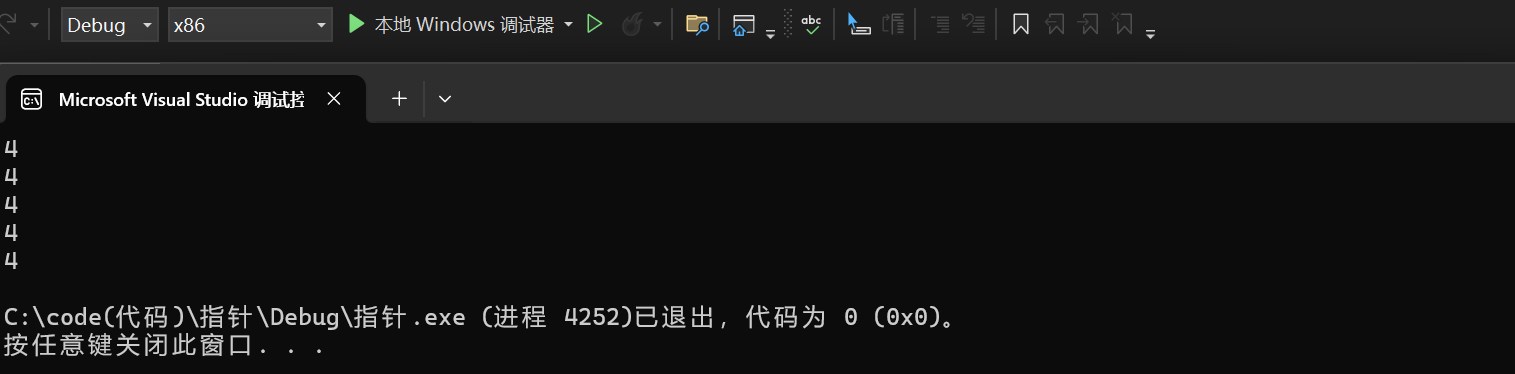
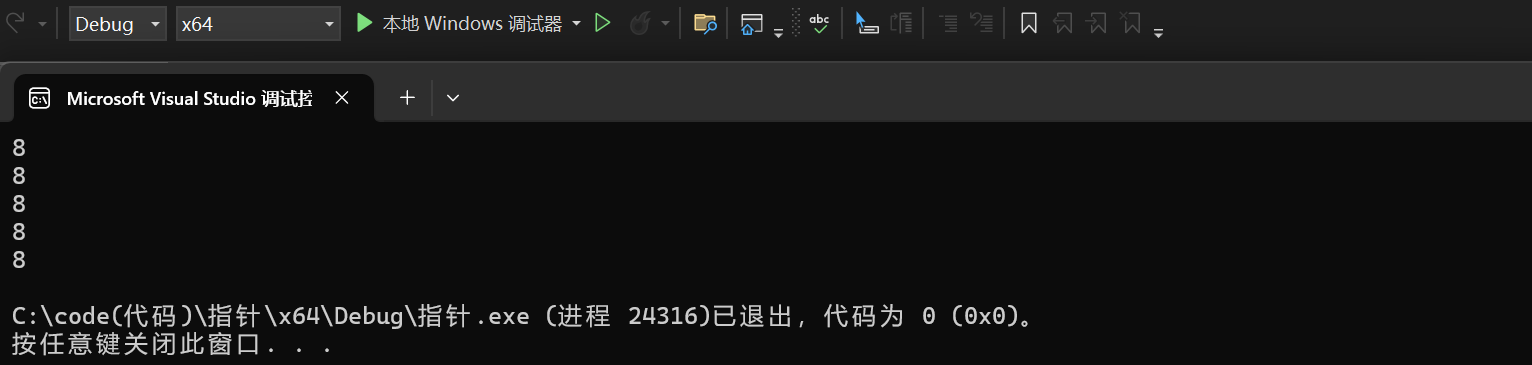
由内存单位转化表可知32bit位相当于4个字节,64bit位相当于8个字节,由此可知指针的大小是多少了,在32位平台下指针的大小是4,在64位平台下指针的大小是8。
#include<stdio.h>
int main()
{
printf("%zd\n", sizeof(int*));
printf("%zd\n", sizeof(char*));
printf("%zd\n", sizeof(float*));
printf("%zd\n", sizeof(double*));
printf("%zd\n", sizeof(short*));
return 0;
}
在x86(32位平台下):
在x64(64位平台下):
由此观之,我们还可以得到一个结论,指针的大小与指针的类型无关,只取决于指针的类型。
五、指针变量类型的意义
1.再探解引用操作
由前面学习我们知道了,指针的大小与指针的类型无关,那么指针的类型究竟起到了什么作用呢?回答这个问题之前我们来看一段代码:
#include<stdio.h>
int main()
{
int a = 0x11223344; //一段十六进制的数字:大小为287454020
int* pa = &a;
*pa = 0;
return 0;
}
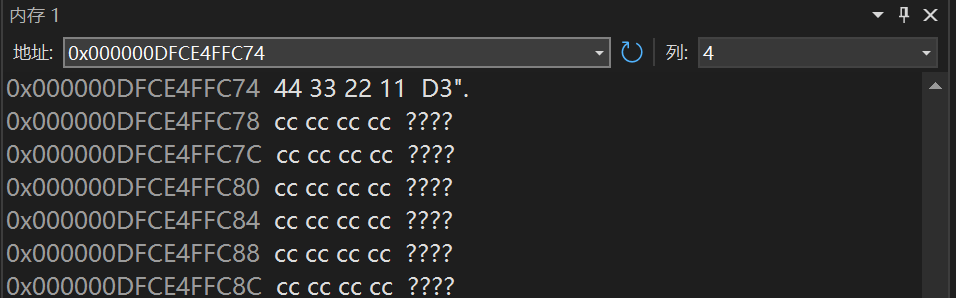
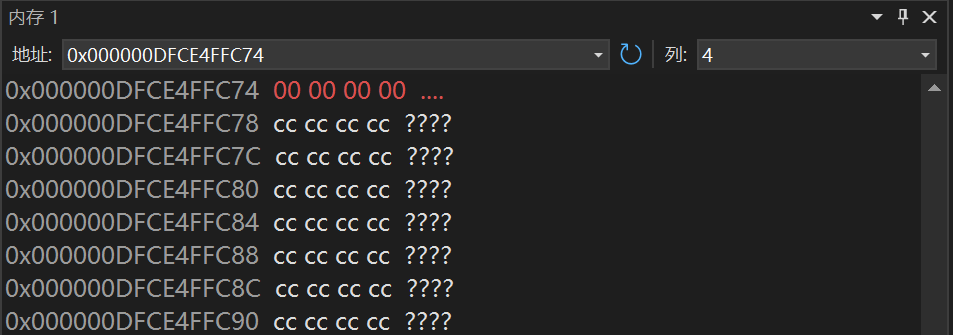
这里看到第一行a的地址为0x000000DFCE4FFC74,所存的值是11223344。
温馨提示:对于十六进制数字每2为代表1字节,这是为什么呢?原因是1个十六进制数字需要4个二进制位来描述,所以2个十六进制位的数字当然是1个字节了。
运行到*pa=0这一行我们可以看到:a的值全变为0了,所以*pa=0可以访问4个字节大小的内容
我们再来看一段代码:
#include<stdio.h>
int main()
{
int a = 0x11223344; //一段十六进制的数字:大小为287454020
char* pa = &a;
*pa = 0;
return 0;
}
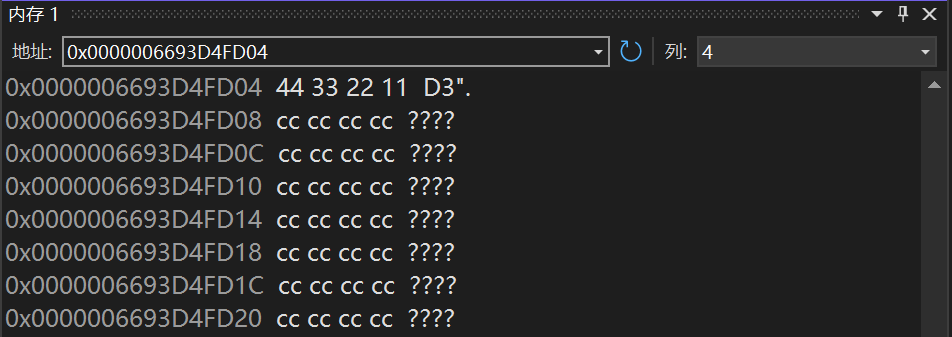
这里看到第一行a的地址为0x0000006693D4FD04,所存的值是11223344。
运行到*pa=0这一行我们可以看到:a的值一个字节变为0了,所以*pa=0可以访问1个字节的内容
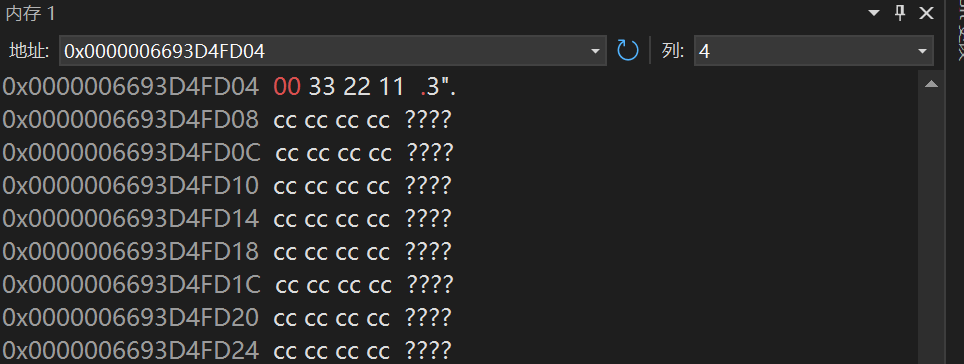
通过这两段代码的分析,我们可以得出一个结论:指针的类型决定了其访问内存的能力,具体能够访问的字节数取决于所指向数据类型的大小。
- 这就说明指针类型决定了指针的权限,即访问字节的大小
- 对于char * ---访问一个字节
- 对于short * ---访问两个字节
- 对于int * ---访问四个字节
- 对于float* ---访问四个字节
- 对于double* ---访问八个字节
2.指针加减整数
我们知道整型变量支持加减运算,那么指针变量是否也具备类似的功能呢?让我们通过以下代码示例来探讨这个问题:
#include<stdio.h>
int main()
{
int a = 10;
int* pa = &a;
char c='w';
char* pc = &c;
printf("pa: %p\n", pa);
printf("pa+1: %p\n", pa + 1);
printf("pc: %p\n", pc);
printf("pc+1: %p\n", pc + 1);
return 0;
}
代码的运行结果如下:

这段代码直观地展示了指针运算的特性:当 int* 指针变量加 1 时,地址会跳过 4 个字节,而 char* 指针变量加 1 时仅跳过 1 个字节。基于这一现象,我们可以推导出通用的指针运算公式:
type* pa = &a; pa + 1 <==> 跳过 1 * sizeof(type)
这一公式清晰地表明,指针的类型直接决定了指针进行加减运算时地址的偏移量大小。
3.泛型指针
在前面的学习中,我们接触到了C语言中一个特殊的指针类型——void*,它也被称为"泛型指针"。这种指针的独特之处在于,它可以指向任意类型的数据,而无需指定具体的数据类型。无论是基本数据类型(如int、float等),还是复杂数据类型(如结构体和数组等),泛型指针都能轻松应对。正是由于这种强大的通用性,我们常常形象地将其称为"垃圾桶"。
但是于此同时,也会产生一个显著的缺陷,那就是void*的指针不能进行加减运算和指针的解引用操作。
1.int a = 10;
2.void* p = &a;
//编译器会出现报错
3.*p = 20;
4. p + 1;
六、const修饰指针
通过前面的学习我们已经了解到,指针解引用操作可以直接修改其指向变量的值。然而,这种特性也带来了潜在风险:程序员的误操作可能导致数据被意外修改。
但是我们要防止出现这样类似的风险我们应该怎么做呢? ----利用const修饰。
1.const关键字
const :
n.常数;恒量
adj.恒定的;不变的
我们先来看一段代码:
#include<stdio.h>
int main()
{
int a=10;
a=20;
const int b=20;
b=30;//编译器会报错
return 0;
}
由上面的代码我们可以知道,通过了const修饰后变量b不能被修该,而没有用const修饰的变量a可以进行正常的修改。
这里又引发了一个问题是否经过const修饰后变量b变成了常量呢?回答这个问题前,我们先看一段代码来进行验证:
#include<stdio.h>
int main()
{
const int b=20;
int arr[b]={0};//编译器会报错
return 0;
}
我们知道在声明一个数组在[ ]里填写的必须是一个常量,而在c语言中经过const修饰后的变量b不是常量,因为在这里会出现编译器报错,但是经过const修饰,变量b具有常属性(即不能修改)。
温馨提示:在cpp中const修饰的变量就变为了常量。
2.运用const修饰指针变量
通过前面的学习,我们已经掌握了const关键字的基本概念及其在整型变量中的应用。然而,经过const修饰的整型变量是否就完全无法改变其值呢?事实并非如此。
这里加的const修饰仅仅只是语法层面上的修饰,我们还可以通过"翻墙"的手段强行修改。利用指针就可以很好的翻越这道语法鸿沟。
我们来看一段代码感受一下:
#include<stdio.h>
int main()
{
const int a = 10; //用const 修饰后a具有了常属性(即不能再被修改)
//直接改变
a = 20; //---报错
//翻墙改变
int* pa = &a;
*pa = 0;
printf("a=%d\n", a);
return 0;
}
由这段代码我们可以清楚的看到,可以利用指针的特性进行强行改变a变量的值。
我们也可以看到这⾥⼀个确实修改了,但是我们还是要思考⼀下,为什么a要被const修饰呢?就是为了不能被修改,如果pa拿到a的地址就能修改a,这样就打破了const的限制,这是不合理的。所以应该让 pa拿到a的地址也不能修改a,那接下来怎么做呢?------用const来修饰指针
2.1.const 放在*左边
#include<stdio.h>
int main()
{
//1.
//放在*的左边,限制的是:指针所指向的内容
//但是却可以指向其他变量 (移情别恋)
int a=20;
int const* p = &a;
int b = 10;
p = &b;//---这样是正确的
*p = 200;//---因const修饰而报错
return 0;
}
针对于const放在*的左边int const * p=&a,我们这样理解:const修饰的是(*p)所以*p不能被修改,而p这个指针变量存放的地址却可以更改。
2.2.cosnt 放在*右边
#include<stdio.h>
int main()
{
//2.
//放在*的右边,限制的是:指针所指向的地址
//但是不却可以指向其他变量 (专心致志)
int a=20;
int * const p = &a;
int b = 10;
*p = 200;//---这样是正确的
p = &b;//---因const修饰而报错
return 0;
}
针对于const放在*的左边int * const p=&a,我们这样理解:const修饰的是"p",所以p不能被修改,而*p这个指针变量存放的内容却可以更改。
七、指针运算
指针的运算包括以下三种:
- 指针+- 整数
- 指针-指针
- 指针的关系运算
1.指针加减运算的应用
#include<stdio.h>
int main()
{
//利用指针访问数组----数组在内存中是连续存放得
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]); //求出数组的长度
int* p = arr;
for (int i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
return 0;
}
这里我们能感受到指针和数组有某种特殊的联系,在后面我会详细讲解一下指针和数组的关联。
2.指针-指针
#include<stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
//指针-指针的前提条件是:两个指针指向同一块空间
//指针1+整数==指针2 <===> 指针2-指针1==整数
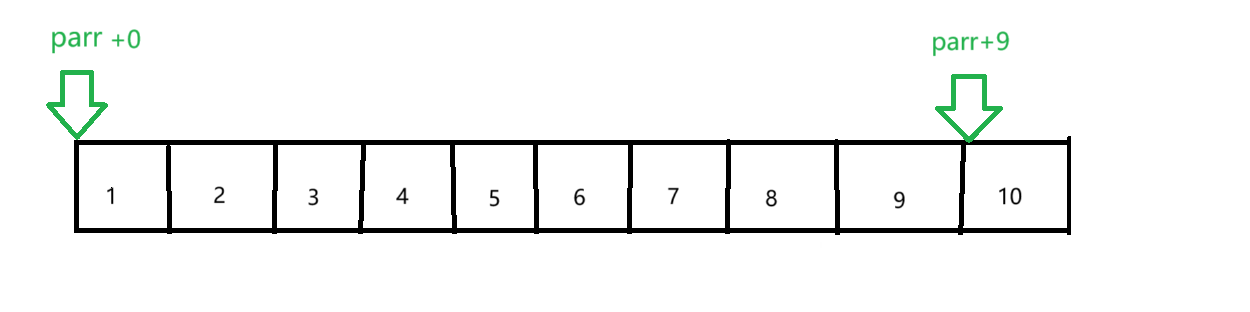
printf("%zd", &arr[9] - &arr[0]);
return 0;
}
#include<stdio.h>
int my_strlen(char *p)
{
char* start= p;
while (*p != '\0')
{
p++;
}
return p - start;
}
int main()
{
printf("%d",my_strlen("abc"));
return 0;
}
这段代码先由读者自行体会,后面笔者会详细讲解有关于传值调用和传址调用的区别。
3.指针的关系运算
#include<stdio.h>
int main()
{
int arr[10]={1,2,3,4,5,6,7,8,9,10};
int *p=arr;
int sz=sizeof(arr)/sizeof(arr[0]);
while(p<p+sz) //这里就运用到了指针关系运算
{
p++;
}
return 0;
}
八、野指针
野指针的定义:野指针就是指针指向的区域是未知的,不确定,没有明确限制的,简单来说也就是指向了不属于你该访问的地址。
1.出现野指针的原因
1.指针未初始化2.指针出现越界3.指针指向的空间释放
1.1指针未初始化
#include<stdio.h>
int main()
{
int *p; //未初始化指向随机值
*p=100l;
return 0;
}
1.2指针越界
#include<stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = arr;
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i <= sz; i++;)
{
p++;
}
return 0;
}
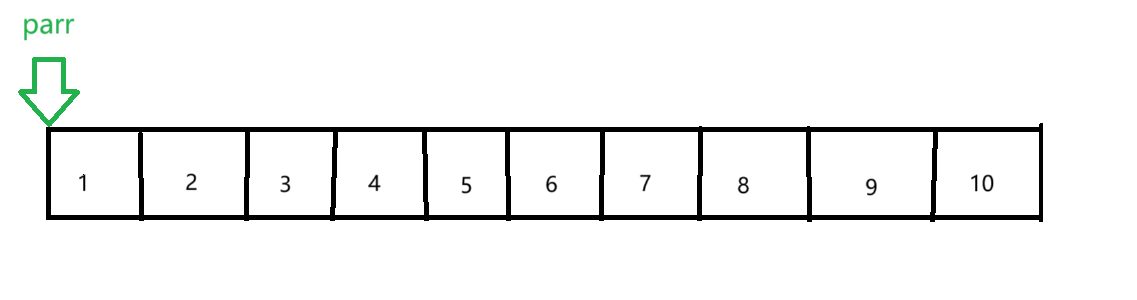
我们看这个循环部分,当i==sz(即i=10时)p的指向如下图所示:
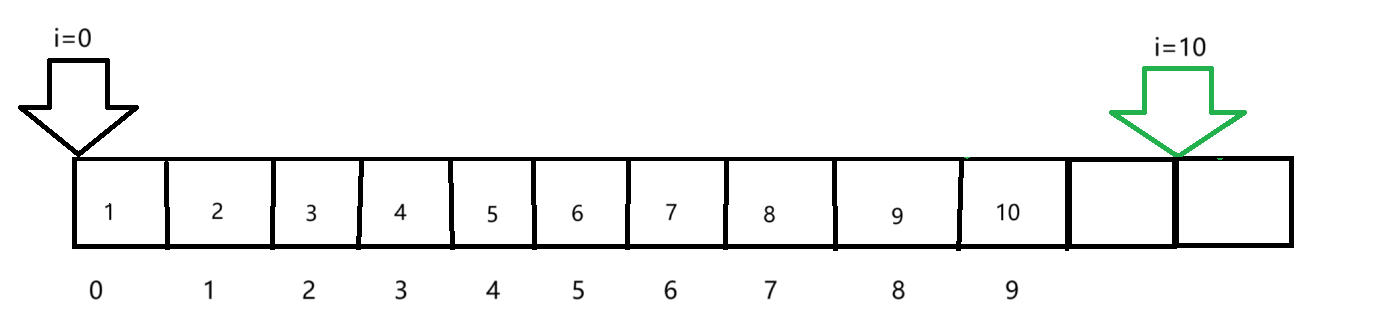
这里就严重造成了指针的越界,所以在使用指针时要注意边界情况。
1.3指针指向的空间已被释放
#include<stdio.h>
int *test()
{
int a=1001;
return &a;
}
int main()
{
int *pa=test();
printf("%d",*pa);
return 0;
}
这里因为在函数调用完的那一刻,函数test中整形变量a的内存被计算机系统给回收了,所以我们无法在继续通过解引用的方式去访问到这一块空间。
2.如何规避野指针
要避免野指针可以从下面几个方面入手:
1.对指针进行初始化
2.小心指针越界
3.指针变量不再使⽤时,及时置NULL,指针使⽤之前检查有效性
2.1对指针进行初始化
#include<stdio.h>
int main()
{
int *p=NULL;
return 0;
}
2.2小心指针越界
避免出现这样的代码:
#include<stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = arr;
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i <= sz; i++;)//出现指针越界
{
p++;
}
return 0;
}
2.3及时置NULL
//指针变量不再使用时,应及时置NULL,以避免悬空指针问题。
//例如,在释放动态分配的内存后,将指针置NULL可以防止后续误用。
int *ptr = (int *)malloc(sizeof(int));
free(ptr);
ptr = NULL; // 置NULL
2.4检查有效性
if (ptr != NULL) {
*ptr = 10; // 安全解引用
}
九、assert断言
在C语言中,<assert.h>头文件定义了assert()宏。该宏用于在程序运行时进行断言检查,若表达式为假,则输出错误信息并终止程序执行。
#include<stdio.h>
int main()
{
int a=10;
int *p=&a;
assert(p!=NULL);
return 0;
}
当表达式为真时,程序将正常执行;若表达式为假,系统会立即抛出错误提示,并精确定位到问题指针所在的行号,这为程序员的调试工作提供了极大便利。
十、传值调用和传址调用
1.传值调用
传值调用简单来说就是在函数中实参直接将数值传给形参
我们来看一段简单的两数交换代码:
#include<stdio.h>
int main()
void swap(int a1,int b1)
{
int temp=a1;
a1=b1;
b1=temp;
}
{
int a=10,b=20;
swap(a,b);
printf("%d %d",a,b);
return 0;
}


这段代码采用了简单的传值调用方式,但无法实现预期的两数交换效果。原因在于:swap函数中操作的是两个临时变量会独立开辟自己的空间(不同于实参),当函数调用结束后,这些临时变量空间会被系统自动回收,而原始实参的值并未发生改变。
2.传址调用
传址调用简单来说就是在函数中实参直接将地址传给形参
#include<stdio.h>
int main()
void swap(int *a1,int *b1)
{
int temp=*a1;
*a1=*b1;
*b1=temp;
}
{
int a=10,b=20;
swap(&a,&b);
printf("%d %d",a,b);
return 0;
}

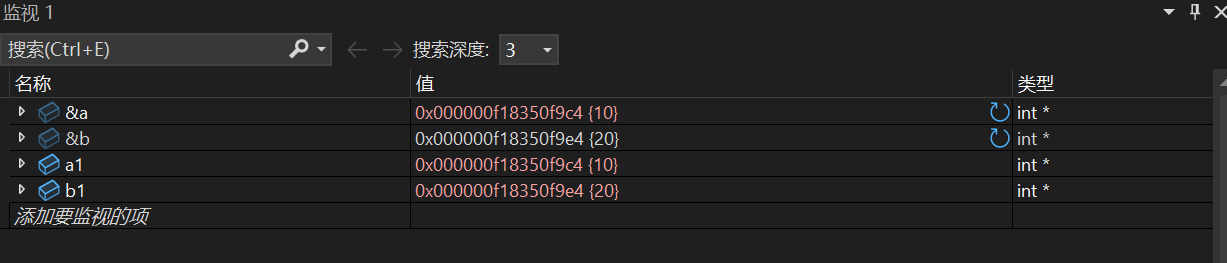
这样a1的地址为a所传递,b1的地址为b所传递,通过指针的解引用方式直接改变两个值,就避免上述出现的开辟独立空间的情况。
十一、深入了解数组名
1.简介数组名
前面我们看到过这样一段代码:
int arr[10]={1,2,3,4,5,6,7,8,9,10};
int *p=&arr[0];
这里我们通过指针拿到数组首元素的地址,但是我想告诉你的其实是数组名本身就是数组首元素的地址,我们可以通过下面代码进行验证一下:
int arr[10]={1,2,3,4,5,6,7,8,9,10};
printf("%p\n",arr);
printf("%p\n",&arr[0]);

这就验证了数组名确实是数组首元素的地址,但是肯定有同学对下面这一段代码有疑问:
int arr[10]={1,2,3,4,5,6,7,8,9,10};
printf("%zd",sizeof(arr));

为什么这里会是40呢?你不是说数组名是数组首元素的地址吗?sizeof(arr)的大小应该是4才对啊,为什么会是40呢?其实这里有两个特例需要读者自行记忆:
• sizeof(数组名),sizeof中单独放数组名,这⾥的数组名表⽰整个数组,计算的是整个数组的⼤⼩, 单位是字节• &数组名,这⾥的数组名表⽰整个数组,取出的是整个数组的地址(整个数组的地址和数组⾸元素的地址是有区别的)
我们可以从下面这段代码中来验证上面的结论:
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
printf("arr= %p\n", arr);
printf("arr+1= %p\n", arr+1);
printf("&arr[0]= %p\n", &arr[0]);
printf("&arr[0]+1= %p\n", &arr[0]+1);
printf("&arr= %p\n", &arr);
printf("&arr+1= %p\n", &arr+1);
printf("%zd\n", sizeof(arr));
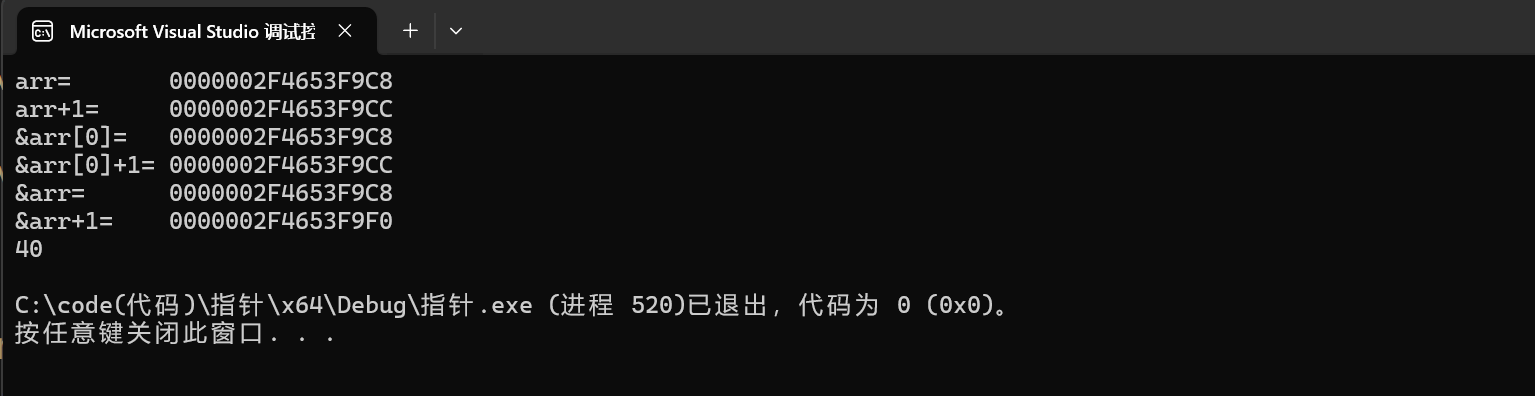
这样就详细解释了&arr是拿到整个数组的地址,因为&arr+1跨越了整个数组字节大小,
由计算结果40表明:sizeof(数组名)中的数组名也是整个数组的地址。
同时我们也主要到arr和&arr的地址是相同的,但是他们的含义完全不同,数组名是拿到的数组首元素的地址,而&数组名拿到的却是整个数组的地址。
2.数组名的应用
对此,结合数组的元素是连续存放的,我们可以得到指针的一个运用:通过指针访问数组:
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
for (int i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}

同时也可以这么写:
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
for (int i = 0; i < sz; i++)
{
printf("%d ", *p);
p++;
}
还可以通过数组下标直接访问:
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
for (int i = 0; i < sz; i++)
{
printf("%d ", p[i]);
}
由此我们可以得到一个小结论:arr[i]<===>*(p+i)<===>p[i]
十二、一维数组传参的本质
1.简介数组传参的本质
通过前面的学习,我们已经了解到数组名本质上就是数组首元素的地址,因此可以使用指针来接收数组名。接下来,我们将深入探讨数组在函数中的应用,特别是如何通过指针来实现函数的参数传递。
我们来比较一段代码:
代码1:
void test(int arr[])
{
int sz = sizeof(arr) / sizeof(arr[0]);//error
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr[10]={1,2,3,4,5,6,7,8,9,10}
test(arr);
}

代码2:
void test(int arr[],int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr[10]={1,2,3,4,5,6,7,8,9,10}
int sz = sizeof(arr) / sizeof(arr[0]);
test(arr,sz);
}
代码1与代码2的主要区别是在于:代码1在test函数中直接求数组的长度,而代码2通过在主函数中求好数组的长度,通过函数传参的方式,将数组长度传递到test函数中,而这一差别导致了,两者的打印结果完全不同。
2.数组传参的简单应用
基于对数组传参特性的理解,我们可以利用这一特点实现一个经典案例:冒泡排序算法。
这里我们不进行详述冒泡排序算法的思想,简单看一下实现的过程:
//冒泡排序
void swap(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void bubble_sort(int arr[], int sz)
{
//趟数
for (int i = 0; i < sz - 1; i++)
{
//一趟
for (int j = 0; j < sz-1-i; j++)
{
if (arr[j] > arr[j + 1])
{
swap(&arr[j], &arr[j + 1]);
}
}
}
}
void print_arr(int arr[], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
十三、二级指针
1.二级指针的定义
在前面的学习中,我们已经深入探讨了指针变量的概念。既然指针变量本质上也是一种变量,那么它自然也有自己的地址。那么,指针变量的地址应该存放在哪里呢?
这就得引入二级指针这一概念:
int a=10;
int *p=&a;
int **pp=&p;
*p=20; //通过解引用访问a的值
**pp=20; //通过两次解引用访问a的值
我们用图示去理解这一代码:
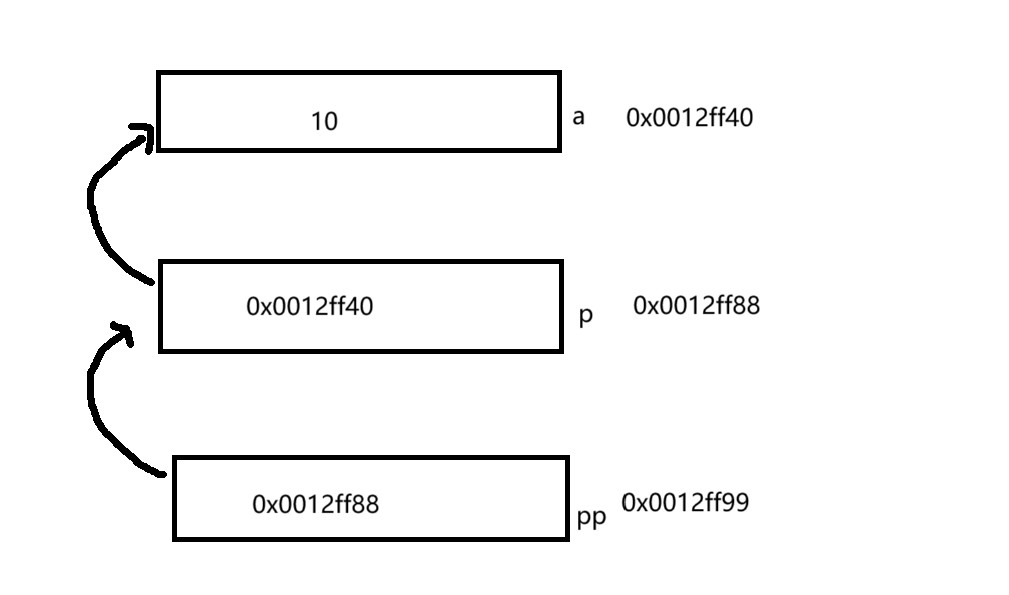
如图所示,一级指针变量p指向变量a,二级指针变量pp指向一级指针变量p,也就是说p存放的是整形变量a的地址,而pp存放的指针变量p的地址,通过对p解引用我们可以访问a的值,通过对pp进行解引用我们可以访问p的值,再次解引用就可以访问a的值。
2.对二级指针剖析
int* *pp
类似于一级指针int * , 二级指针“ int* * ” 最右边这颗星说明了这个变量是指针变量,int*说明指针指向的对象是整形指针。
十四、指针数组
1.指针数组的定义
前面我们学习了指针和数组,那么指针数组到底是指针还是数组呢?我们可以类比理解一下这个概念:整形数组是一个数组,数组元素都为整形。 字符数组是一个数组,数组元素都为字符。
由此可以得出指针数组是一个数组,数组元素都为指针。
int *p1=NULL;
int *p2=NULL;
int* arr[2]={p1,p2};
类似于整形数组,指针数组的元素为指针。
2.指针数组的应用
利用指针数组我们可以来模拟实现二维数组,看下面一段代码:
#include<stdio.h>
int main()
{
int arr1[] = { 1,2,3,4 };
int arr2[] = { 2,3,4,5};
int arr3[] = { 3,4,5,6};
int* parr[] = { arr1,arr2,arr3 };
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 4; j++)
{
//本质上是指针运算:(parr[i][j])<==>*(*(parr+i)+j)
printf("%d ", parr[i][j]);
}
printf("\n");
}
return 0;
}
我们知道数组名是数组首元素的地址,其类型是int*,所以当然可以存放在指针数组中
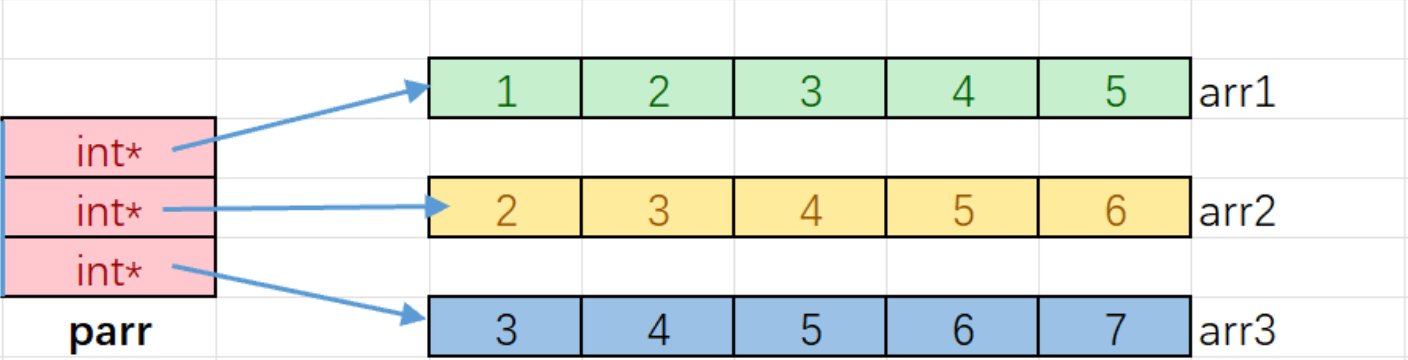
parr[i]其实访问的就是指针数组中的元素{arr1,arr2,arr3},例如:通过parr[0]拿到arr1的地址,再利用一维数组访问元素的方法arr1[j]就可以遍历arr1整个数组元素)
这段代码的本质其实也是指针的运算,*(parr+i)拿到{arr1,arr2,arr3},*(*(parr+i)+j)便是{arr1,arr2,arr3}数组的元素,这就实现了二维数组的访问。
十五、字符指针
在前面我们学习了整形指针,接下来我们可以类比学习字符指针:
1.指向单个字符
char c='a';
char *pc=&c;
*pc='w';
与整形指针类似,可以指向单个字符,通过解引用的方式访问字符。
2.指向字符数组
char arr[10] = "abcdef";
char* p1= arr;
与整形数组类型,字符数组的数组名也是字符首元素地址
3.指向常量字符串
char* p2 = "abcdef";//指向常量字符串
重点要理解的是指针指向常量字符串,这里是将常量字符串放进p2变量中吗?显然不是,因为我们知道了指针本质是地址,所以这里其实是将常量字符串的首元素的地址放进p当中,也就是这里面字符a的地址。
十六、数组指针
数组指针是数组还是指针呢?前面我们学习了整形指针,字符指针。同时也看到过浮点型指针,短整型指针,泛型指针,那么数组指针是什么呢?
1.简介数组指针
int *p -----存放整形的地址
char *p -----存放字符的地址
short *p -----存放短整型的地址
float *p -----存放浮点型的地址
由此可猜测数组数组指针,应该是存放数组的地址。
int arr[10]={1,2,3,4,5,6,7,8,9,10}
1.int *p[10];
2.int (*p)[10];
其中1,2哪个会是数组指针呢?
我们来分析一下1和2的区别:
代码1,p先和[]结合说明其是数组,数组的元素类型是int*,也就是说p是一个指针数组变量
代码2,p前面有一颗星说明其是指针,指向的是什么呢,我们把变量名拿掉,发现指向的其实是数组,为什么呢?int [ ] 这不就是数组吗。
2.数组指针变量的初始化
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int (*p2)[10]=&arr;
提示: 这里的&arr不同于数组名,数组名是数值首元素的地址,而&arr拿到的是整个数组的地址
int (*p) [10] = &arr;| | || | || | p指向数组的元素个数| p是数组指针变量名p指向的数组的元素类型
3.剖析数组指针与指针
我们来辨别一下数组指针与指针:
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p1 = arr;
//p1---int* arr---int*
int (*p2)[10] = &arr;
//p2---int(*)[10] &arr---int(*)[10]
int*p1=arr,指向的是数组首元素的地址,而int (*p2)[10]指向的是整个数组的地址,它们在数值上的大小是完全一致,但是在含义上面完全不一样。
4.二维数组传参的本质
回顾二维数组 : int arr[3][4] = { {1,2,3,4},{2,3,4,5},{3,4,5,6 } };
0 1 2 3 0 1 2 3 4 1 2 3 4 5 2 3 4 5 6
对于二维数组我们要更加深入了解一个层面:
1.二维数组的数组名也是数组"首元素"的地址
2.二维数组可以认为是一维数组的拼接
3."首元素"就是第一行
void test1(int p[][4],int r,int c) //int (*p)[4]<==>int p[][4]
{
for (int i = 0; i < r; i++)
{
for (int j = 0; j < c; j++)
{
printf("%d ", p[i][j]);
}
printf("\n");
}
}
void test2(int (*p)[4],int r,int c) //int (*p)[4]<==>int p[][4]
{
for (int i = 0; i < r; i++)
{
for (int j = 0; j < c; j++)
{
printf("%d ", *(*(p+i)+j)); //<==>p[i][j]
}
printf("\n");
}
}
int main()
{
//二维数组的数组名也是数组"首元素"的地址
//二维数组可以认为是一维数组的拼接
//"首元素"就是第一行
int arr[3][4] = { {1,2,3,4},{2,3,4,5},{3,4,5,6 } };
int(*p)[4] = &arr;//指向第一行数组
test1(arr,3,4);
test2(arr,3,4);
return 0;
}
所以根据数组名就是数组首元素地址这个原理,二维数组的数组名就是二维数组第一行数组的地址,根据上面这个例子,二维数组的第一行是{1,2,3,4},所以数组指针应该是:
int (*p)[4]=&arr;
在二维数组传参时,实际传递的是一个一维数组的地址,因此需要使用数组指针来接收。我们可以在函数形参中这样声明:int (*p)[4]。
此外,我们也可以使用int a[][4]这种写法,这也是正确的。需要注意的是,二维数组传参时,第二维的大小不能省略,因为数组指针需要明确指定数组的维度。
十七、函数指针
函数指针是一种特殊的指针类型。与整型指针存储整型变量的地址类似,函数指针存储的是函数的地址。每个函数在内存中都有一个特定的地址,函数指针正是用来指向这个地址的。
1.函数地址的简介
函数是否有地址呢?为了回答这个问题,我们可以通过一段代码来验证一下:
#include <stdio.h>
void test()
{
printf("hello world\n");
}
int main()
{
printf("test: %p\n", test);
printf("&test: %p\n", &test);
return 0;
}

函数不仅有地址,而且我们发现函数名和&函数名的地址居然是一样的,那是不是和数组一样呢?数组的数组名是数组首元素的地址,&数组名得到的是整个数组的地址,而函数却不是这样的,在c语言中,函数名是函数的地址,&函数名也函数的地址,这两者在本质没有根本上的区别。
2.函数指针的定义
上面我们了解到了函数也有地址,那么如何存放函数地址呢?这里就需要用到函数指针了,我们先来看一下函数指针如何定义和书写的,其实与数组指针很类似。
我们先回顾一下数组指针是如何书写的:
int arr[10]={0,1,2,3,4,5,6,7,8,9};
int (*p)[10]=&arr;
这里*p说明p是指针变量,而拿掉*p我们就可以看到指向的类型为 int [10]这就是数组,由此我们萌发出一个想法:先写一个*p变量表示指针类型,然后写出函数的参数和返回类型作为指向的对象。
返回类型 (* 指针变量名) (参数1类型,参数2类型,.....);
下面我们通过一段代码来验证我们的猜想:
#include <stdio.h>
int add(int x,int y)
{
return x+y;
}
int main()
{
int (*p) (int,int)=&add;
printf("p=%p\n",p);
printf("&add=%p\n",&add);
return 0;
}

我们发现确实是与我们猜想的一样。
3.函数指针的剖析
函数指针类型的剖析:int (*p) (int x, int y)| | || | || | p指向函数的参数类型和个数的交代| || 函数指针变量名p|p指向函数的返回类型:int (*) (int x, int y) //函数指针变量的类型
温馨提示:int (*) (int x, int y) 函数的参数变量名可以省略。
4.函数指针的应用
既然函数指针变量存储的是函数地址,而函数名本身也代表函数地址,同时解引用函数指针同样可以定位到函数,基于这些特性,我们可以编写如下代码:
#include <stdio.h>
int Add(int x, int y)
{
return x+y;
}
int main()
{
int(*pf3)(int, int) = Add;
printf("%d\n", (*pf3)(2, 3));
printf("%d\n", pf3(3, 5));
return 0;
}
十八、函数指针数组
1.函数指针数组的简介
类比于整形指针数组,一个存放整形指针的数组,我们类似的也可以得到函数指针数组,我们先来回顾一下整形指针的数组。
int a=10,b=20;
int *p1=&a;
int *p2=&b;
int *p[2]={p1,p2};
代码解释:这里[]的优先级更高,p优先于[]结合形成数组,int*为数组元素的类型。
对此,那么我们是不是可以猜想一下,函数指针数组就是存放函数指针,也就是函数地址的一个数组。
返回类型 (* 数组变量名[]) (参数类型1,参数类型2.....)
通过拿掉数组名[],我们可以发现数组的元素类型为:
返回类型 (*) ( 参数类型1,参数类型2.....) ---------函数指针类型
我们惊奇的发现这就是函数指针数组,为了验证我们的猜想我们可以写出这样一段代码:
#include<stdio.h>
int add(int a, int b)
{
return a + b;
}
int sub(int a, int b)
{
return a - b;
}
int mul(int a, int b)
{
return a*b;
}
int div(int a, int b)
{
return a / b;
}
int main()
{
int (*p[4])(int ,int)={add,sub,mul,div};
printf("%d",p[0](2,3));
return 0;
}
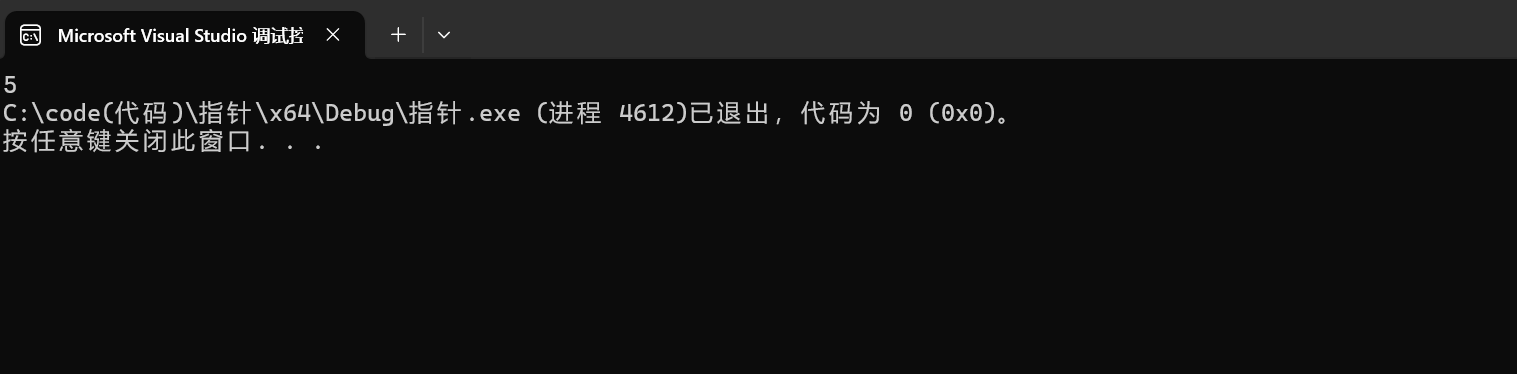
与我们的推测完全吻合,在这段代码中,我们通过p[0](2, 3)调用了数组中的第一个函数add,并传递了参数2和3。程序执行后,输出结果为5,这正是add(2, 3)的返回值。这一结果与我们的推测完全吻合,证明了p确实是一个函数指针数组,并且我们可以通过数组索引来调用不同的函数。
2.函数指针数组的应用
利用上面函数指针可以存放函数的特性,我们可以引出下面一个概念——转移表。
转移表是一种通过函数指针数组来实现多路分支的技术,常用于替代复杂的switch-case或if-else语句,以提高代码的可读性和执行效率。
以实现简易计算器为例:
计算器1:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
//加法
int add(int a, int b)
{
return a + b;
}
//减法
int sub(int a, int b)
{
return a - b;
}
//乘法
int mul(int a, int b)
{
return a * b;
}
//除法
int div(int a, int b)
{
return a / b;
}
int main()
{
int input = 0; //选择何种操作
int ret = 0; //存放答案
int x = 0, y = 0; //两个操作数
//打印菜单
do
{
printf("************************\n");
printf("*****1:add 2:sub*****\n");
printf("*****3:mul 4:div*****\n");
printf("*******0:exit***********\n");
scanf("%d", &input);
switch (input)
{
case 1:
printf("输入操作数:");
scanf("%d %d", &x, &y);
ret = add(x, y);
printf("ret = %d\n", ret);
break;
case 2:
printf("输入操作数:");
scanf("%d %d", &x, &y);
ret = sub(x, y);
printf("ret = %d\n", ret);
break;
case 3:
printf("输入操作数:");
scanf("%d %d", &x, &y);
ret = mul(x, y);
printf("ret = %d\n", ret);
break;
case 4:
printf("输入操作数:");
scanf("%d %d", &x, &y);
ret = div(x, y);
printf("ret = %d\n", ret);
break;
default:
printf("选择错误\n");
break;
}
} while (input);
return 0;
}
通过这段代码我们发现,case分支中代码过度臃肿和冗余,不太简洁,这时我们可以通过,转移表来简化这段代码,以使得代码清晰易懂。
我们先来介绍一下如何使用转移表,就是将函数地址存放在函数指针数组当中,通过这里的选择来实现不同函数的过程。
int (*p[5])(int ,int)={0,add,sub,mul,div};
这里我们通过将数组的第一个元素设置为0地址,以达到数组下标与输入的函数相对应。
于是我们可以改进得到这样的代码:计算器2
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int add(int a, int b)
{
return a + b;
}
int sub(int a, int b)
{
return a - b;
}
int mul(int a, int b)
{
return a * b;
}
int div(int a, int b)
{
return a / b;
}
int main()
{
int input = 0;
int ret = 0;
int x = 0, y = 0;
int (*p[5])(int, int) = { 0,add,sub,mul,div };
do
{
printf("************************\n");
printf("*****1:add 2:sub*****\n");
printf("*****3:mul 4:div*****\n");
printf("*******0:exit***********\n");
scanf("%d", &input);
if ((input <= 4 && input >= 1))
{
printf("输入操作数:");
scanf("%d %d", &x, &y);
ret = (*p[input])(x, y);
printf("ret = %d\n", ret);
}
else if (input == 0)
{
printf("退出计算器\n");
break;
}
else
{
printf("输入有误\n");
}
} while (input);
return 0;
}
这里将case的各个分支用转移表的形式呈现,以实现代码的简化。
十九、利用指针实现回调函数
1.回调函数的概念
如果你把函数的指针(地址)作为参数传递给另⼀个函数,当这个指针被⽤来调⽤其所指向的函数 时,被调⽤的函数就是回调函数。回调函数不是由该函数的实现⽅直接调⽤,⽽是在特定的事件或条 件发⽣时由另外的⼀⽅调⽤的,⽤于对该事件或条件进⾏响应。简而言之就是通过函数指针去作为媒介,来调用其他函数的过程。
2.回调函数改进简易计算器
我们可以通过将switch语句封装成函数来简化计算器1的代码结构。在前面的学习中,我们已经掌握了函数指针的使用方法,这为实现回调函数提供了可能。接下来,让我们看看如何利用这一特性对计算器代码进行优化。
将下面这段代码进行封装,就会遇到下面这样的问题,因为不同的计算需要调用不同的函数,而封装成一个函数就只能使用这样一个add计算函数
void cacl()
{
int x=0,y=0;
int ret=0;
printf("输入操作数:");
scanf("%d %d", &x, &y);
ret = add(x, y);
printf("ret = %d\n", ret);
break;
}
为应对此类问题,我们可以利用函数指针机制接收不同函数的地址,实现函数封装的效果。通过这种方式,封装函数能够灵活调用不同的计算函数。
计算器3:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
//回调函数:在函数中通过函数指针调用其他函数
int add(int a, int b)
{
return a + b;
}
int sub(int a, int b)
{
return a - b;
}
int mul(int a, int b)
{
return a * b;
}
int div(int a, int b)
{
return a / b;
}
void clc(int (*pf)(int, int))
{
printf("输入操作数:");
int x = 0, y = 0;
int ret = 0;
scanf("%d %d", &x, &y);
ret = pf(x, y);
printf("ret = %d\n", ret);
}
int main()
{
int input = 0;
do
{
printf("************************\n");
printf("*****1:add 2:sub*****\n");
printf("*****3:mul 4:div*****\n");
printf("*******0:exit***********\n");
scanf("%d", &input);
switch (input)
{
case 1:
clc(add);
break;
case 2:
clc(sub);
break;
case 3:
clc(mul);
break;
case 4:
clc(div);
break;
}
} while (input);
return 0;
}
这样的calc函数也被称为回调函数,在函数中通过函数指针调用其他函数。
3.利用回调函数实现qsort
为了进一步加深对回调函数的理解,我们再来一个模仿实现qsort函数的案例,我们可以先来看一下qsort函数的函数头:
void qsort (void* base, size_t num, size_t size, int (*compar)(const void*,const void*));
先来分析一下函数的四个参数:
1.void* base : 指向要排序的数组的第一个对象的指针,转换为 void*
2.size_t num:待排序数组的元素个数
3.size_t size:待排序数组的元素字节大小
4.int (*compar)(const void*,const void*)) :① 指向比较两个元素的函数的指针,此函数被重复调用以比较两个元素。
②指向的函数原型需要为:
int compar (const void* p1, const void* p2)
qsort函数的功能是:通过对任意数据类型的元素按照你想要的排序方式进行排序,可以进行降序排序或者进行升序排序。
我们简单回顾一下冒泡排序,基于冒泡排序实现qsort函数:
#include<stdio.h>
//冒泡排序
void swap(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void bubble_sort(int arr[], int sz)
{
//趟数
for (int i = 0; i < sz - 1; i++)
{
//一趟
for (int j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
swap(&arr[j], &arr[j + 1]);
}
}
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
return 0;
}
当前代码仅支持整型数组的冒泡排序,我们需要对其进行扩展,使其能够处理通用类型数组的排序需求。
先关注一下这段代码的结构,和需要进行改进的部分:
void bubble_sort(int arr[], int sz)
{
//趟数
for (int i = 0; i < sz - 1; i++)
{
//一趟
for (int j = 0; j < sz - 1 - i; j++)
{
if ( arr[j] > arr[j + 1] )
{
swap(&arr[j], &arr[j + 1]);
}
}
}
}
基于红色部分的代码无需要进行改进,这是冒泡排序的核心思想,而只需要改进紫色代码,改进if语块的部分。
1.首先if (arr[j] > arr[j + 1])这里只能进行整形部分的比较,我们需要对这部分进行改造。
2.其次swap(&arr[j], &arr[j + 1])这里仅能进行对整形部分交换,我们也需要对这部分改造
3.最后对函数头进行改造
3.1.函数头改造为:
void qsort (void* base, size_t num, size_t size, int (*compar)(const void*,const void*));
3.2改造if语句判断部分
利用函数指针去调用使用者写的compar函数,将两个相邻元素的地址传入,根据用户想选择的类型,进行强制转换。
if ( compar( (char*)base+(size)*j , (char*)base + (size)*(j+1)) )
如何理解这里的:1.(char*)base+(size)*j 2.(char*)base + (size)*(j+1)
这里读者肯定有以下这么几个疑惑:
1.为什么要将base转化为char* ?
2.为什么要base+(size)*j ?
解释:
①因为base是void*的指针不能直接解引用而要进行类型转化,为什么要转换为char*类型的指针呢,我们前面学习到char*的指针解引用访问一个字节,利用这样的特性。
②结合我们传入的size部分,size为待排序数组元素的字节大小,通过用char*的指针加上size就可以访问到下一个元素,而使得能够进行相邻元素的比较。
3.3改造swap函数
void swap(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
这里仅仅只是对整形元素进行交换,不能达到我们的对于通用类型数据的功能。
前面我们已经将我们传入的待排序数组元素转化为char*类型的指针,这里我们就需要用char*类型的指针进行接收,那么这里可不可以直接进行解引用进行两个元素的交换呢?
显然不行,因为char*的元素解引用只能访问一个字节,而我们是不确定我们待排数组的元素字节大小呢,所以我们也需要通过传入size,利用将两个元素的每个字节进行交换。
温馨提示:
(对于这个交换法完全不了解的,读者可以搜索一下c语言中常见的三种交换元素的方法进行学习。)
void Swap(char* p1, char* p2, int size)
{
for (int i = 0; i < size; i++)
{
char temp = *(p1 + i);
*(p1 + i) = *(p2 + i);
*(p2 + i) = temp;
}
}
3.4完整的代码
void Swap(char *p1, char* p2,int size)
{
for (int i = 0; i < size; i++)
{
char temp = *(p1+i);
*(p1+i) = *(p2+i);
*(p2+i) = temp;
}
}
void q_sort(void *base,int num, int size,int (*compar)(void *,void *))
{
for (int i = 0; i < num - 1; i++)
{
for (int j = 0; j < num - 1 - i; j++)
{
//第j个元素的地址
void* elem_j = (char*)base + size * j;
//第j+1元素的地址
void* elem_j1 = (char*)base + size * (j + 1);
if ( compar(( elem_j, elem_j1 ) )
{
Swap((elem_j, elem_j1 , size);
}
}
}
}
3.5测试函数
void Swap(char *p1, char* p2,int size)
{
for (int i = 0; i < size; i++)
{
char temp = *(p1+i);
*(p1+i) = *(p2+i);
*(p2+i) = temp;
}
}
void q_sort(void *base,int num, int size,int (*compar)(void *,void *))
{
for (int i = 0; i < num - 1; i++)
{
for (int j = 0; j < num - 1 - i; j++)
{
//第j个元素的地址
void* elem_j = (char*)base + size * j;
//第j+1元素的地址
void* elem_j1 = (char*)base + size * (j + 1);
if ( compar(( elem_j, elem_j1 ) )
{
Swap((elem_j, elem_j1 , size);
}
}
}
}
struct stu
{
int age;
char name[20];
};
int cmp1(void* a, void* b)
{
return *(int *)a > *(int *)b;
}
int cmp2(void* a, void* b)
{
return *(char*)a > *(char*)b;
}
int cmp3(void* a, void* b)
{
return ((struct stu*)a)->age > (((struct stu*)b)->age);
}
int cmp4(void* a, void* b)
{
return ((struct stu*)a)->name > ((struct stu*)b)->name;
}
void test01()
{
int arr[10] = { 9,7,8,6,5,3,4,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
q_sort(arr, sz, sizeof(int), cmp1);
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void test02()
{
char c[] = "gfedcba";
int sz = strlen(c);
q_sort(c, sz, sizeof(char), cmp2);
printf("%s", c);
printf("\n");
}
void test03()
{
struct stu p[] = { {10,"zhangshan"},{20,"wangwu" } };
int sz = sizeof(p) / sizeof(p[0]);
q_sort(p, sz, sizeof(p[0]), cmp3);
for (int i = 0; i < sz; i++)
{
printf("%d ", p[i].age);
}
printf("\n");
}
void test04()
{
struct stu p[] = { {10,"zhangshan"},{20,"wangwu" } };
int sz = sizeof(p) / sizeof(p[0]);
q_sort(p, sz, sizeof(p[0]), cmp4);
for (int i = 0; i < sz; i++)
{
printf("%s ", p[i].name);
}
printf("\n");
}
int main()
{
test01();
test02();
test03();
test04();
return 0;
}
总结:
compar调用的完整流程:
- 地址计算:
q_sort根据base、size、j计算第 j 个和 j+1 个元素的地址(elem_j和elem_j1);- 参数传递:
q_sort将这两个地址作为参数传给compar函数;- 比较执行:
compar函数将void*转换为具体类型指针,按自定义规则比较,返回 “是否需要交换” 的结果(1 或 0);- 交换判断:
q_sort根据compar的返回值,决定是否调用Swap交换元素。整个过程中,
q_sort始终不知道元素的具体类型,全靠compar函数 “翻译” 和比较 —— 这就是函数指针实现 “通用排序” 的核心逻辑。
二十、思考两个有趣的指针代码
大家可以把自己的思考打在评论区中
1. (* ( void (*)( ) ) 0 ) ( )
2. void ( * signal( int , void(*)(int) ) ) (int)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









