



 本文详细介绍了线性回归的基本形式、成本函数及其多种变体,包括普通最小二乘法、岭回归、Lasso和弹性网络。通过对误差的平方和最小化来寻找最佳函数匹配,同时探讨了概率解释。文章还讨论了求解方法,如梯度下降法的不同策略,并特别提到了岭回归中L2正则化的应用。
本文详细介绍了线性回归的基本形式、成本函数及其多种变体,包括普通最小二乘法、岭回归、Lasso和弹性网络。通过对误差的平方和最小化来寻找最佳函数匹配,同时探讨了概率解释。文章还讨论了求解方法,如梯度下降法的不同策略,并特别提到了岭回归中L2正则化的应用。
文章目录
基本形式
线性模型试图学的一个通过属性的线性组合来进行预测的函数,函数形式为:
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
d
x
d
+
b
f(x)=w_1x_1+w_2x_2+...+w_dx_d+b
f(x)=w1x1+w2x2+...+wdxd+b
向量表示
f
(
x
)
=
w
T
x
+
b
f(x)=w^Tx+b
f(x)=wTx+b
我们的目标是学习得到
w
w
w和
b
b
b,这样模型就确定了。
这里有一个小技巧,我们令
x
0
=
1
x_0=1
x0=1这样,模型就可以进行简化、统一为
h
θ
(
x
)
=
θ
0
x
0
+
θ
1
x
1
+
.
.
.
+
θ
n
x
n
=
θ
T
x
h_\theta(x)=\theta_0x_0+\theta_1x_1+...+\theta_nx_n=\theta^Tx
hθ(x)=θ0x0+θ1x1+...+θnxn=θTx
θ
0
\theta_0
θ0为截距,在sklearn中为intercept_
Cost function
定义
线性回归的损失函数有很多种形式,但都可以称为最小二乘法。最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。 (最小二乘法)
下面以sklearn的线性回归为例:
普通最小二乘法(RSS)
J ( θ ) = ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta)=\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2 J(θ)=i=1∑m(hθ(x(i))−y(i))2
岭回归(Ridge)
使用了L2正则
J
(
θ
)
=
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
α
∑
j
=
0
n
θ
j
2
J(\theta)=\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2+\alpha\sum_{j=0}^n\theta_j^2
J(θ)=i=1∑m(hθ(x(i))−y(i))2+αj=0∑nθj2
Lasso
使用了L1正则
J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
α
∑
j
=
0
n
∣
θ
j
∣
J(\theta)=\frac{1}{2m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2+\alpha\sum_{j=0}^n|\theta_j|
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2+αj=0∑n∣θj∣
弹性网络
结合了L1和L2
J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
α
ρ
∑
j
=
0
n
∣
θ
j
∣
+
α
(
1
−
ρ
)
2
∑
j
=
0
n
θ
j
2
J(\theta)=\frac{1}{2m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2+\alpha\rho\sum_{j=0}^n|\theta_j|+\frac{\alpha(1-\rho)}{2}\sum_{j=0}^n\theta_j^2
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2+αρj=0∑n∣θj∣+2α(1−ρ)j=0∑nθj2
由来(概率解释)
假设目标变量和输入值存在如下等量关系
y
(
i
)
=
θ
T
x
(
i
)
+
ϵ
(
i
)
y^{(i)}=\theta^Tx^{(i)}+\epsilon^{(i)}
y(i)=θTx(i)+ϵ(i)
其中
ϵ
(
i
)
\epsilon^{(i)}
ϵ(i)是误差项。假设
ϵ
(
i
)
\epsilon^{(i)}
ϵ(i)是独立的且符合高斯分布
ϵ
(
i
)
∼
N
(
0
,
σ
2
)
\epsilon^{(i)}\sim N(0, \sigma^2)
ϵ(i)∼N(0,σ2)
故
p
(
ϵ
(
i
)
)
=
1
2
π
σ
exp
(
−
(
ϵ
(
i
)
)
2
2
σ
2
)
p
(
y
(
i
)
∣
x
(
i
)
;
θ
)
=
1
2
π
σ
exp
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(\epsilon^{(i)})^2}{2\sigma^2})\\ p(y^{(i)}|x^{(i)};\theta) = \frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(y^{(i)} - \theta^Tx^{(i)})^2}{2\sigma^2})
p(ϵ(i))=2πσ1exp(−2σ2(ϵ(i))2)p(y(i)∣x(i);θ)=2πσ1exp(−2σ2(y(i)−θTx(i))2)
使用最大似然估计(MLE)
L
(
θ
)
=
∏
i
=
1
m
p
(
y
(
i
)
∣
x
(
i
)
;
θ
)
=
∏
i
=
1
m
1
2
π
σ
exp
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
L(\theta) =\prod_{i=1}^{m} p(y^{(i)}|x^{(i)};\theta) =\prod_{i=1}^{m}\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(y^{(i)} - \theta^Tx^{(i)})^2}{2\sigma^2})
L(θ)=i=1∏mp(y(i)∣x(i);θ)=i=1∏m2πσ1exp(−2σ2(y(i)−θTx(i))2)
取对数
l
o
g
L
(
θ
)
=
l
o
g
∏
i
=
1
m
1
2
π
σ
exp
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
l
o
g
L
(
θ
)
=
∑
i
=
1
m
l
o
g
1
2
π
σ
−
1
σ
2
⋅
1
2
∑
i
=
1
m
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
log\ L(\theta) =log\ \prod_{i=1}^{m}\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(y^{(i)} - \theta^Tx^{(i)})^2}{2\sigma^2})\\ log\ L(\theta)=\sum_{i=1}^{m}log\ \frac{1}{\sqrt{2\pi}\sigma}-\frac{1}{\sigma^2}\cdot\frac{1}{2}\sum_{i=1}^{m}(y^{(i)} - \theta^Tx^{(i)})^2
log L(θ)=log i=1∏m2πσ1exp(−2σ2(y(i)−θTx(i))2)log L(θ)=i=1∑mlog 2πσ1−σ21⋅21i=1∑m(y(i)−θTx(i))2
第一项为常数项,要使
l
o
g
L
(
θ
)
log\ L(\theta)
log L(θ)最大,所以要第二项尽可能的小,所以要使
1
2
∑
i
=
1
m
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
\frac{1}{2}\sum_{i=1}^{m}(y^{(i)} - \theta^Tx^{(i)})^2
21i=1∑m(y(i)−θTx(i))2
尽可能的小
求解
有了Cost Function之后,我们就需要对目标函数进行求解
普通最小二乘法
正规方程
以西瓜书的推导为范本 P55 3.11
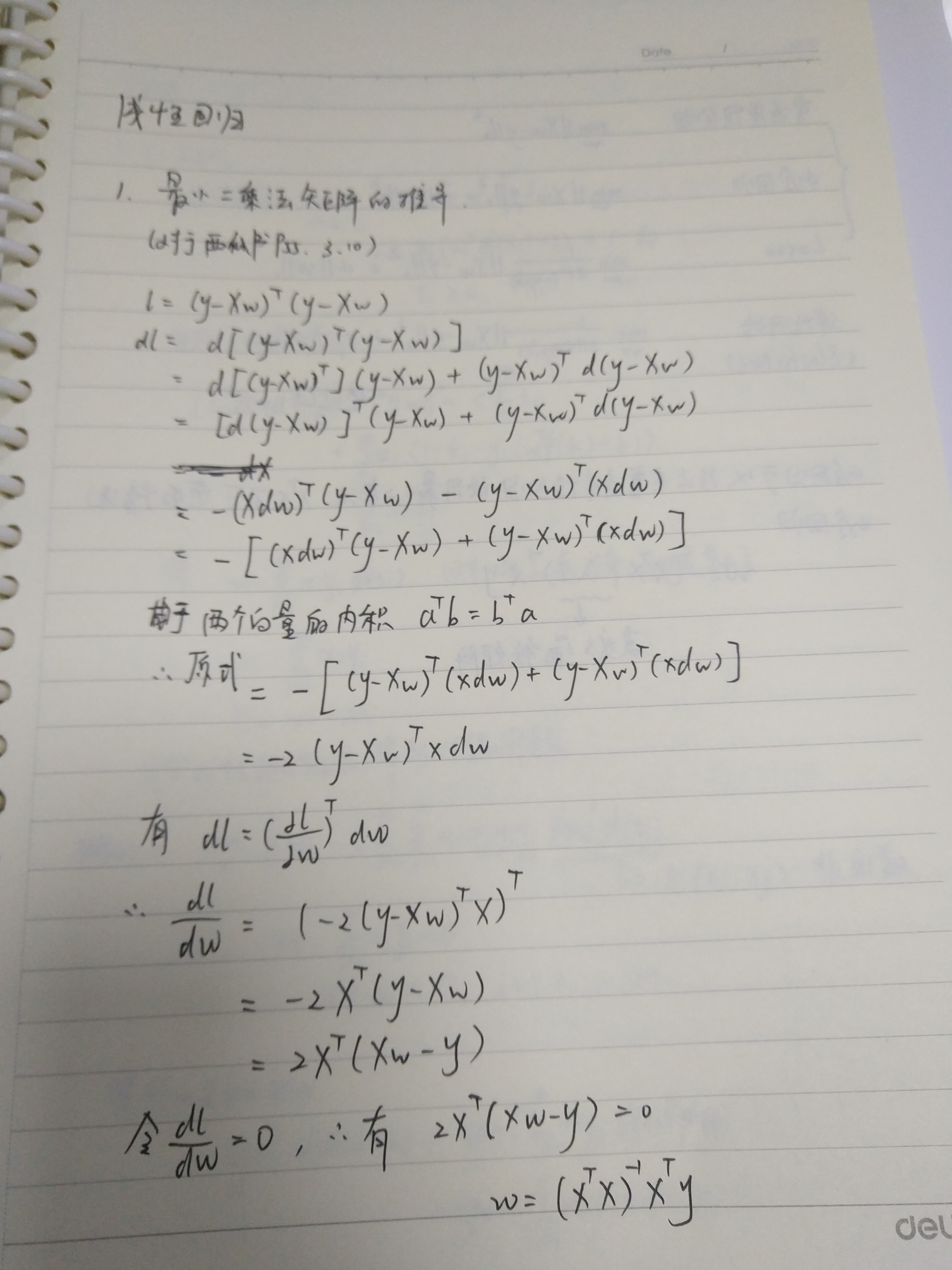
梯度下降
这里以吴恩达的为范本,吴恩达的损失函数为
J
(
θ
)
=
1
2
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J(\theta)=\frac{1}{2}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2
J(θ)=21∑i=1m(hθ(x(i))−y(i))2
梯度下降就是从某一个
θ
\theta
θ 的初始值开始,然后逐渐重复更新
θ
j
:
=
θ
j
−
α
∂
∂
θ
j
J
(
θ
)
\theta_j:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta)
θj:=θj−α∂θj∂J(θ)
其中
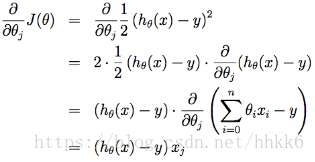
批量梯度下降(Batch Gradient Descent)
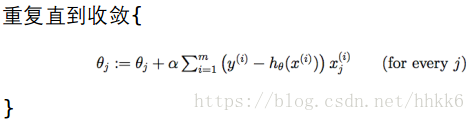
优点:得到全局最优解
缺点:当样本数目很多时,训练过程会很慢
随机梯度下降(Stochastic Gradient Descent)
也叫作增量梯度下降法(incremental gradient descent)
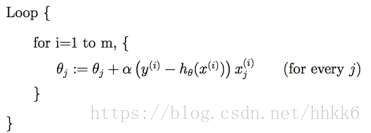
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。
随机梯度下降法,和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。
对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。
对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
优点:训练速度快
缺点:准确度下降,可能跳出最优解,不是全局最优
小批量梯度下降法(Mini-batch Gradient Descent)
SGD相对来说要快很多,但是也有存在问题,由于单个样本的训练可能会带来很多噪声,使得SGD并不是每次迭代都向着整体最优化方向,因此在刚开始训练时可能收敛得很快,但是训练一段时间后就会变得很慢。
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,每次取一定数量的样本进行迭代更新。
岭回归
岭回归加入的L2正则可以避免正规方程中存在不可逆的问题
正规方程
损失函数的向量写法为
l
=
(
y
−
X
w
)
T
(
y
−
X
w
)
+
λ
w
T
w
l=(y-Xw)^T(y-Xw)+\lambda w^Tw
l=(y−Xw)T(y−Xw)+λwTw
最终
w
=
(
X
T
X
+
λ
I
)
−
1
X
T
y
w=(X^TX+\lambda I)^{-1}X^Ty
w=(XTX+λI)−1XTy
一定是一个可逆矩阵
Lasso
由于L1不可导,所以不能使用正规方程,梯度下降等。sklearn中的Lasso使用的是坐标下降求解的
https://www.cnblogs.com/pinard/p/6018889.html
附录
各种误差

MSE(均方误差)、RMSE(均方根误差)、MAE(平均绝对误差)、R-Squared
参考
https://yezuolin.com/2018/10/Machine-Learning(Linear-Regression)/
https://blog.youkuaiyun.com/Datawhale/article/details/82931967

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









