




 本文对比了MLCVNet与Pointformer在3D对象检测中的创新,MLCVNet利用自注意力模块提升点云特征融合,GSC模块增强场景理解;Pointformer以UNet为基础,集成局部和全局特征,运用Linformer降低计算复杂度。两者在信息提取和效率上各有特色。
本文对比了MLCVNet与Pointformer在3D对象检测中的创新,MLCVNet利用自注意力模块提升点云特征融合,GSC模块增强场景理解;Pointformer以UNet为基础,集成局部和全局特征,运用Linformer降低计算复杂度。两者在信息提取和效率上各有特色。
论文题目:MLCVNet: Multi-Level Context VoteNet for 3D Object Detection
论文题目:3D Object Detection with Pointformer
两篇文章要对比着来看
首先,我们来看看mlcvnet做了些什么
万物的起源:mlcvnet将attention模块引入了点云目标检测中:
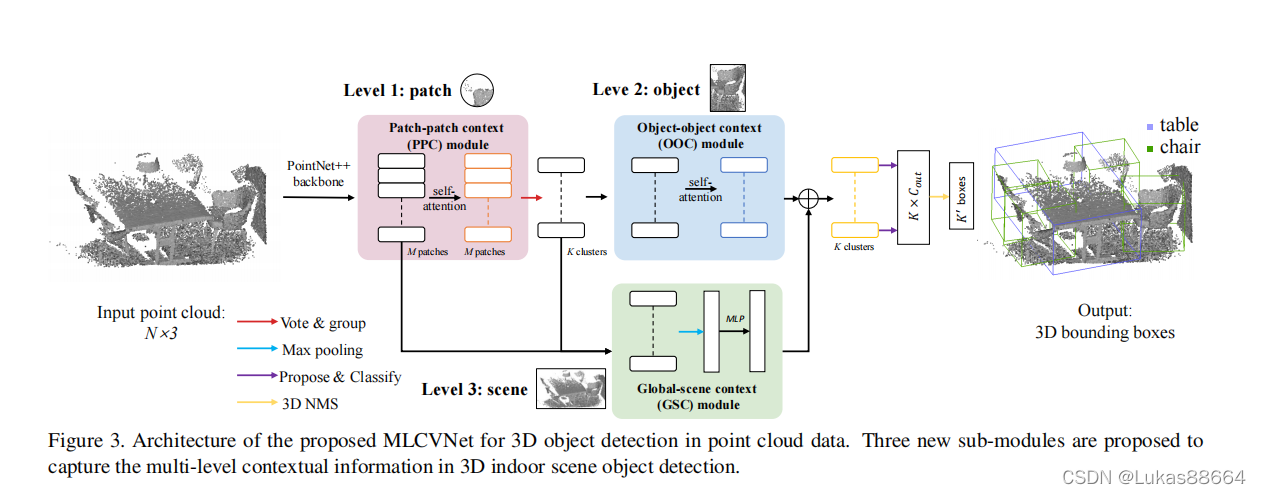
文章主要由三个部分组成:ppc ooc及GSC
首先我们利用pointnet++作为backbone生成一系列的patches,这些patch的生成显然是通过一层层叠加的SA层得到的,他们有着周围信息的丰富语义信息。
将他们打包输入到PPC中。
之前提出的votenet是怎么对这些patch进行操作的呢?
他主要是采用了一个vote block的环节,将这些patch作为输入,同时回归物体中心的偏移量,这个预测值是通过mlp模仿hough voting过程得到的。
而本文中则采用的是一个自注意力模块,提取patch之间的信息。
具体的操作如下所示:
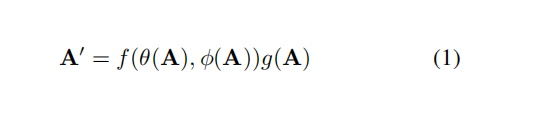
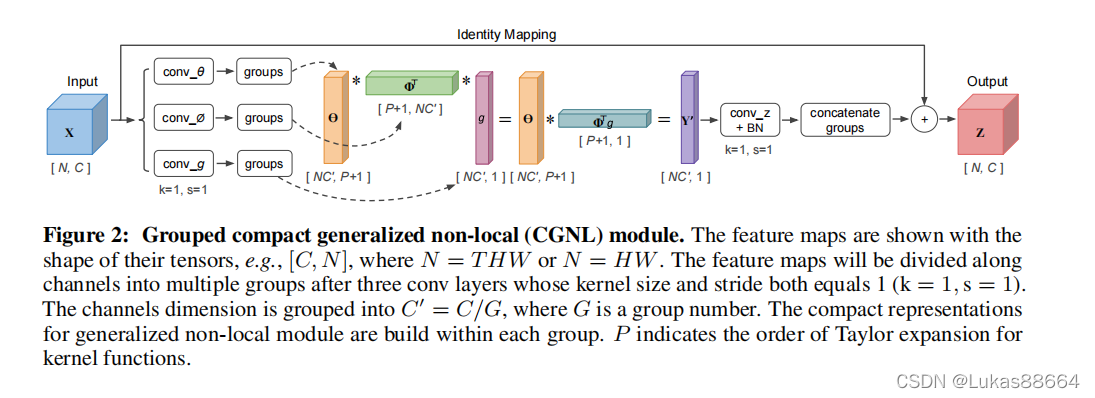
这一块主要是通过CGNL模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5330
5330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









