




 Votenet,一种全新的3D点云目标检测方法,由Facebook AI Research和斯坦福大学联合发布,彻底改变了传统依赖2D检测器的3D检测流程。通过引入霍夫投票机制,Votenet能够直接处理原始点云数据,生成更精确的目标提议,不仅提高了检测精度,还减少了对计算资源的需求。
Votenet,一种全新的3D点云目标检测方法,由Facebook AI Research和斯坦福大学联合发布,彻底改变了传统依赖2D检测器的3D检测流程。通过引入霍夫投票机制,Votenet能够直接处理原始点云数据,生成更精确的目标提议,不仅提高了检测精度,还减少了对计算资源的需求。
Facebook AI Research ,Stanford University, 22 Aug 2019, Kaiming He1 ,3D点云检测网络
个人观点:
Voting by Grouping Dependent Parts,ECCV 10
Combined object categorization and segmentation with an implicit shape model. In Workshop on statistical learning in computer vision, ECCV, volume 2, page 7, 2004. 1
Robust object detection with inter leaved categorization and segmentation. International journal of computer vision, 77(13):259–289, 2008. 2, 3
旧的方法引入到新的技术中也可以带来新的进展,不能以为有了可以train的CNN,一些基础的知识就可以不学了,基础知识没学,CNN也设计不出来
kaiming大佬的成果,直接否定了原来 leverage 2D dectectors 的思路,而是重新设计了一种利用raw point cloud data的方式来做,既不依赖于2D检测器的性能,也不会出现为了照顾计算量导致的细节数据丢失。那么为什么原来直接利用点云的方法没有得到如此高的精度呢?论文认为这是由于以往的方法没有根据点云的天生特点来进行设计,而是直接照搬2D的流程:提特征然后加RPN。但是点云不同于稠密的图像像素,在3D情况下目标中心附近一般没有点云,因为点云只存在于目标的表面。增大感受野可以 将距离目标中心的较近的点考虑进来,但是也会引入其他目标表面的点,因此结果往往都不尽如人意。
而论文提出的霍夫投票,将 位于目标表面的点云 用 投票生成的更加接近中心的vote点来代替,这样再进行提议生成 就能很好的解决之前的问题。
从本质上直接解决了点云检测的固有问题,抛弃了依赖2D检测器或者2D流程的所有思路,真的强
论文总结
目前的3D检测严重依赖于2D的方法。主要有以下两种:
- 把3D点云转换为规则的网格(voxel grids 或者鸟瞰图)
- 在2D图像上做检测然后作为3D的提议
本文致力于提出一个泛化的pipeline( as generic as possible)完成点云目标检测的任务,即Votenet,克服了3D目标的中心远离其表面的点因而很难在一步内完成准确的回归的问题。
数据集:ScanNet , SUNRGBD,在使用几何信息而没有使用有RGB信息的前提下,仍然达到了SOTA
论文介绍&相关工作
介绍了之前的一些代表性工作,都是依赖于2D检测器的网络。体素化或者网格化导致信息细节丢失,而2D区域提议则将漏检所有2D检测器漏检的目标。
本文提出的网络则直接基于点云数据,不依赖于任何2D检测器(基于Point net++)
(大家都默认Pointnet++在3D检测中的地位和ResNet在2D检测中的地位相同了)
尽管Point net ++在3D分类和分割任务中取得了很大的成功,但是很少有人研究如何在3D检测中利用好它,一种Naive的思想是根据2D检测的流程,在Point net++的输出特征后面接一个RPN,得到目标框。然而点云的稀疏性导致结果不尽如人意,这里是有问题的:
- 在图像中目标中心都是有像素存在的
- 在3D情况下目标中心附近一般没有点云,因为点云只存在于目标的表面
因此,基于点云的网络很难在目标中心附近学习场景的上下文。
此外作者指出盲目增加感受野是没有效果的,只会把更多的目标中心点纳入到计算来
基于此,论文方法提出了vote机制,生成新的处于目标中心点的点云,来作为box proposals
综上,本文贡献:
- 在深度学习中引入Hough Vote机制 ,设计了一个可以端到端训练的模型,VoteNet
- 在两大数据集上的达到SOTA
- 深入分析了vote在点云三维目标检测中的重要性。
Deep Hough Voting
传统的Hough vote2D检测器:
包括离线和在线步骤。首先,在给定带注释对象边界框的图像集合的情况下,使用图像块(或其特征)与其到相应对象中心的偏移之间的存储映射来构造码本。在推断时,interest points是从图像中选择出来的,然后根据interest points 提取 patches。将这些patches与代码簿中的patches进行比较,以检索偏移量并计算投票。由于对象patches倾向于一致投票,cluster将在对象中心附近形成。最后,通过将cluster投票回溯到其生成的patches来检索目标边界。
- 基于投票的机制比区域建议网络(RPN)更适合稀疏数据。RPN必须在可能位于空白空间的对象中心附近生成建议,这会导致额外的计算。
- 投票机制基于自下而上的原则,少量的空间信息累计形成一个confident detection
- 即使CNN有较大的感受野,引入投票机制仍然有可能提升性能
为了成功将vote机制引入到deep learning中,本文对hough vote 的部件进行了如下调整:
- Interest Points(即seed points)过CNN提取而不是手工提取
- Vote 生成是通过网络学习到的而不是通过codebook,此外vote location可以通过特征向量进行扩充,从而实现更好的聚合
- Vote aggregation 通过可训练的点云处理层实现,利用投票功能,网络可以筛选出低质量的vote,并生成改进后的提议。
- Object proposals 的坐标、维度、朝向、语义类别都可以直接从聚合的特征中生成,少了回溯vote patches的过程。
VoteNet 结构
整体结构:
point cloud --> seed points --> votes --> vote cluster --> boundind boxes 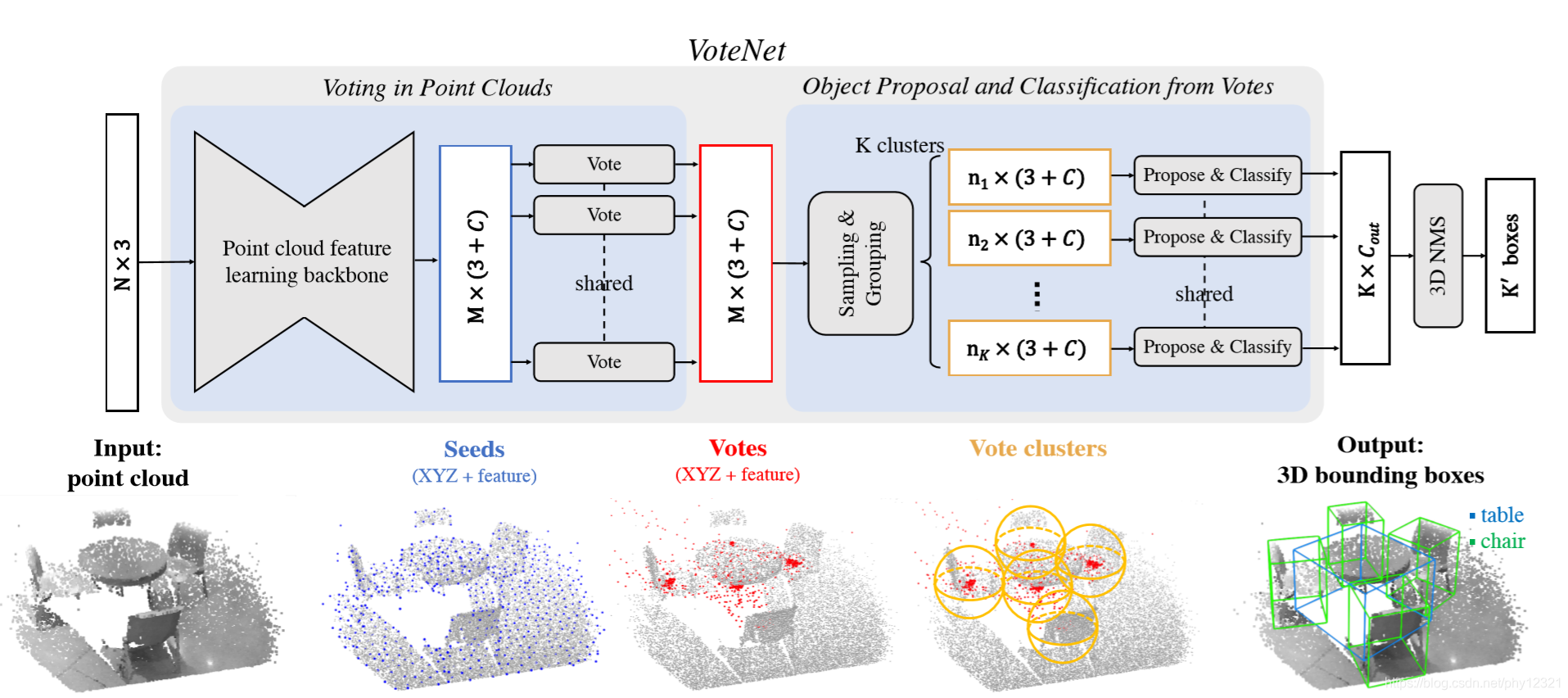
整个网络可以分成两个部分:
一个是处理现有的点云以产生vote;另一个是在虚拟点(即vote)上运行的部分来产生提议和分类。
1.通过点云产生 投票(vote)
输入点云Nx3,输出M个votes,每个vote包含3D坐标和高维特征向量
点云特征学习
使用point net++来做,输出一个带有特征向量的点云的子集(M个 seed points),每个维度是(3 + C).,一个seed point生成一个vote。
使用深度网络进行霍夫投票
相比于使用预先计算好的码本的传统霍夫投票,这里直接使用深度网络。
输入为seed points = [ x , f ],输出为 ∆ = [ ∆x , ∆f ]
voting模块是一个全连接的多层感知网络,输出坐标偏移量∆x,以及特征偏移量 ∆f,最终得到 vote = [ x + ∆x , f + ∆f ],这样得到的vote相比于seed points 不在局限于目标的表面,更加互相接近
训练∆x的loss函数 : 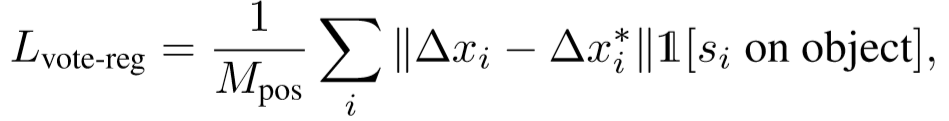
Mpos是seed points 的总数, ∆x* 是ground truth
2.区域提议,从投票结果分类
vote点使得位于同一目标内的特征更加靠近,更易于聚类和学习上下文特征
通过采样和聚类进行投票聚类
采用均匀抽样进行采样,通过空间接近程度进行聚类:
根据最远点采样从M个vote中采样出k个,然后通过寻找 k 个样本的邻接votes 形成k个聚类 ,论文评价这种方法简单但是有效
通过聚类中心进行提议和分类
vote本质上是一组高维空间的特征点,可以利用一个通用的点集学习网络(一个shared PointNet)来聚合vote,从而生成目标提议(一个聚类中心生成一个提议)
对于每个聚类:
- 聚类中的所有vote坐标点经过归一化后被输入到一个类pointnet的网络MLP1进行处理,相互之间独立
- 将得到的输出输入到MLP2中池化,融合各个vote的信息
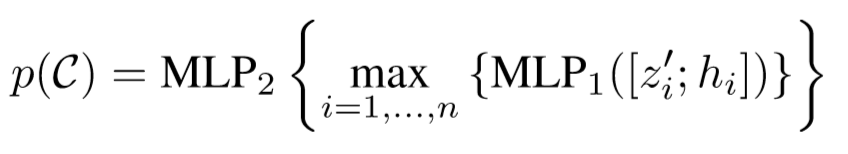
p©表示聚类C的提议向量,包含目标得分,目标框坐标,语义标签信息
损失函数
三部分:objectness, bounding box estimation, semantic classification losses.
- objectness:交叉熵
- bounding box estimation:包括中心点回归,朝向和尺寸估计。只对正样本计算,
- semantic classification losses:交叉熵
实验
相比于SOTA模型
在SUNRGBD数据集上:根据提供的相机参数 将深度图转化为点云数据,
在Scan netV2数据集上:从重建的网格中提取顶点作为输入点云。由于Scan net没有朝向信息的真值,网络改为预测轴对齐目标框 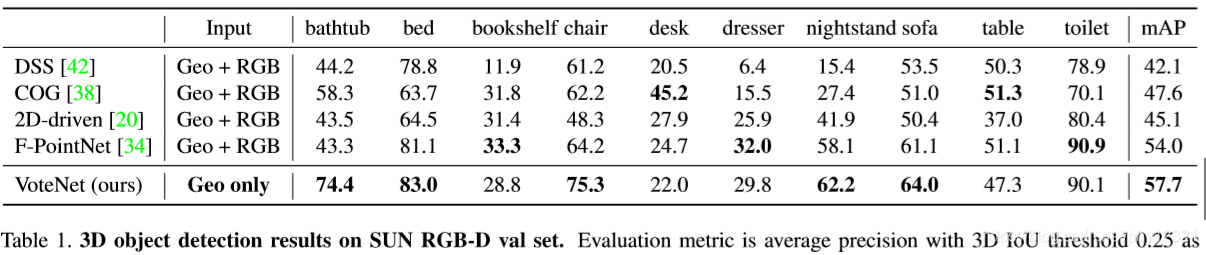

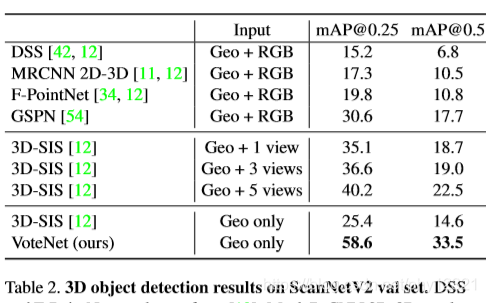
实验分析
是否需要vote?
boxnet:不使用vote机制,直接从采样的点云(seed points)生成预测框,对比结果:
vote融合效果
vote的融合使得vote点之间的信息可以交互,是votenet中非常重要的一环。
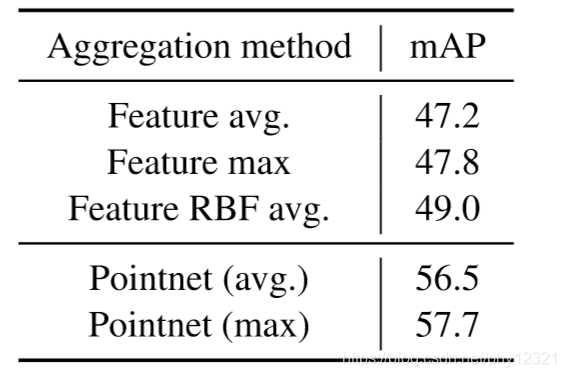
使用pointnet网络学习的vote聚合比在局部邻域中手动汇集特征要有效得多。
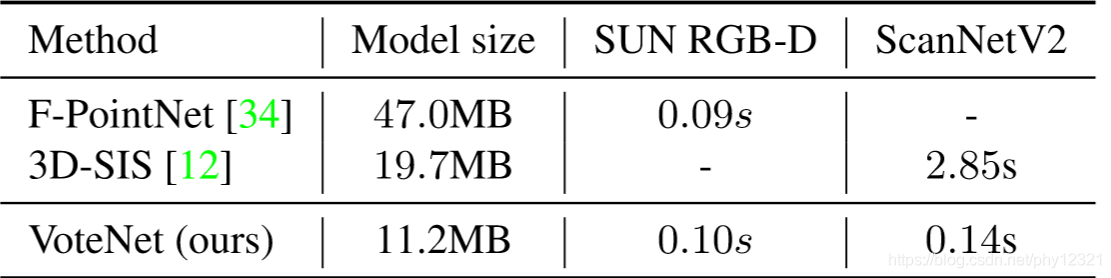
模型尺寸和速度
4× smaller than FPointNet in size
more than 20× times faster(online) than 3D-SIS(off-line)(3D-SIS好像本来就很慢?而且人家做的是分割,不是检测啊。。)
定量结果和讨论
仍然有局限性:
由于我们没有利用RGB信息,因此检测门、窗和某些场景中用黑色边框表示的图片几乎是不可能的。 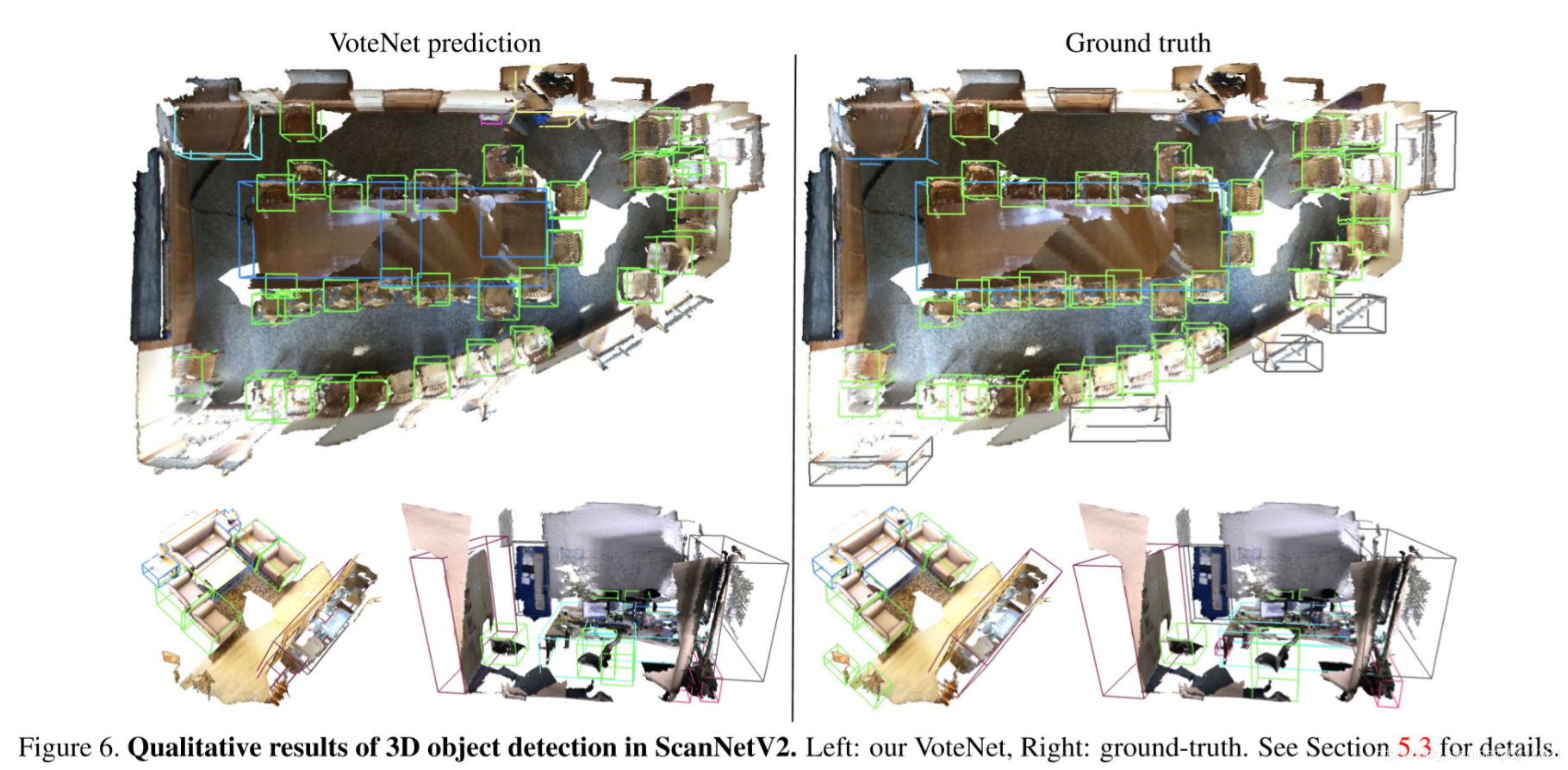
优势:
在左上角场景中检测到的椅子比地面真相提供的椅子多。在右上角的场景中,我们可以看到,尽管只看到沙发的一部分,但Votene却能很好地预测出amodal包围盒。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









