 改进对象检测:FitnessNMS与BoundedIoULoss
改进对象检测:FitnessNMS与BoundedIoULoss





 本文探讨了如何通过FitnessNMS和BoundedIoULoss优化对象检测,指出训练和测试阶段IoU阈值一致的重要性。作者提出新的score函数和匹配策略,增强了对高IoU框的重视。实验表明,这种方法能提高召回率,并且与SoftNMS兼容。此外,改进的BoundingBoxRegression也提升了ROI准确性和召回率。论文的贡献在于增强分类器对负样本的敏感度以及优化高IoU重叠框的处理。
本文探讨了如何通过FitnessNMS和BoundedIoULoss优化对象检测,指出训练和测试阶段IoU阈值一致的重要性。作者提出新的score函数和匹配策略,增强了对高IoU框的重视。实验表明,这种方法能提高召回率,并且与SoftNMS兼容。此外,改进的BoundingBoxRegression也提升了ROI准确性和召回率。论文的贡献在于增强分类器对负样本的敏感度以及优化高IoU重叠框的处理。
论文题目:《Improving Object Localization with Fitness NMS and Bounded IoU Loss》
发现这篇文章网络上资源较少,来写一下自己看完这篇文章的一些想法,可能不成熟,欢迎指正。谢谢!
本文对于NMS进行了改进,提出了一个叫Fitness NMS的模块,在DeNet基础上进行的改进。
文章介绍了一下nms,这里 也简单写一下:

这里score(.)函数用来评价选择bbox的置信度,而same(.)用来检测两个框的iou值。因此算法的核心思想就是:对于Bounding Box的列表B及其对应的置信度S,采用下面的计算方式.选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空.
本文就是对于上述的score及same函数进行了修改来得到一个新的nms。

作者先做实验对比了train和test采用不同iou阈值时的map表现结果:
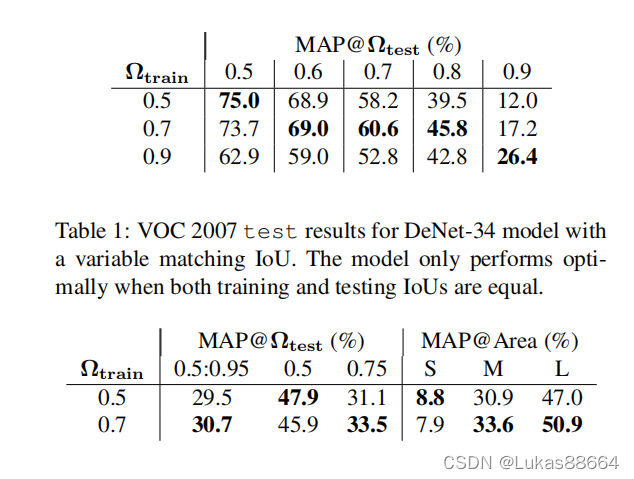
结果可以看到只有当训练和测试选择iou阈值一致时输出的结果才比较好,而且0.5表现出来的map最高,这便引出了本文想要解决的问题:并不是要选择所有超过该阈值的所有bbox,而是要选择最高的一个。
- Detection Clustering
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4788
4788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









