




confluent-kafka
pip3 install confluent-kafka
Producer 生产
Consumer消费

Kafka 生产者和消费者配置及优化建议
Kafka 生产者配置及优化
1. 生产者配置
from confluent_kafka import Producer
# Kafka 配置
config = {
'bootstrap.servers': '10.10.x.x:3082',
'security.protocol': 'SASL_PLAINTEXT',
'sasl.mechanism': 'SCRAM-SHA-512',
'sasl.username': 'kafka-974a3a34-bpxuser1',
'sasl.password': 'zjavIj4OPZNV2vALc2F>zesn8izaHEYP(ZK0IETrtKrMR5w+gUNpL60xkGhX3ca9' # 请替换为您的实际密码
}
# 创建生产者实例
producer = Producer(**config)
# 异步发送消息
def delivery_report(err, msg):
if err is not None:
print('Message delivery failed: {}'.format(err))
else:
print('Message delivered to {} [{}]'.format(msg.topic(), msg.partition()))
# 发送消息
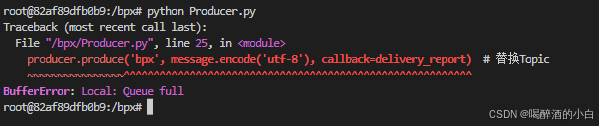
for _ in range(10):
producer.produce('bpx', 'Hello, Kafka!', callback=delivery_report) # 替换Topic
# 等待消息被发送
producer.flush()
2. 错误信息 BufferError: Local: Queue full 的解决方法
-
检查 Kafka 集群状态:
- 确保 Kafka 集群运行正常,并且没有分区不可用或者 broker 宕机的情况。
- 使用
kafka-topics.sh命令检查主题状态:kafka-topics.sh --describe --topic <topic-name> --bootstrap-server <broker-address>
-
增加生产者队列大小:
- 在创建 Kafka 生产者时,可以通过设置
buffer_memory配置项来增加队列大小。例如:producer = Producer({ 'bootstrap.servers': '10.10.x.x:3082', 'security.protocol': 'SASL_PLAINTEXT', 'sasl.mechanism': 'SCRAM-SHA-512', 'sasl.username': 'kafka-974a3a34-bpxuser1', 'sasl.password': 'zjavIj4OPZNV2vALc2F>zesn8izaHEYP(ZK0IETrtKrMR5w+gUNpL60xkGhX3ca9', 'buffer.memory': 33554432 # 32MB })
- 在创建 Kafka 生产者时,可以通过设置
-
减少消息发送频率:
- 检查代码中的消息发送逻辑,尝试降低消息发送的频率。例如,可以使用
time.sleep减少发送频率:import time for _ in range(10): producer.produce('bpx', 'Hello, Kafka!', callback=delivery_report) time.sleep(0.1) # 每次发送间隔0.1秒
- 检查代码中的消息发送逻辑,尝试降低消息发送的频率。例如,可以使用
-
优化消息大小:
- 如果可能,减小单个消息的大小,这样可以在相同的队列容量下容纳更多的消息。
-
增加分区数量:
- 为 Kafka 主题增加更多的分区,可以提高 Kafka 集群处理消息的能力。使用
kafka-topics.sh命令增加分区数量:kafka-topics.sh --alter --topic <topic-name> --partitions <new-partition-count> --bootstrap-server <broker-address>
- 为 Kafka 主题增加更多的分区,可以提高 Kafka 集群处理消息的能力。使用
-
检查和优化网络:
- 确保生产者和 Kafka 集群之间的网络连接没有问题,网络延迟或丢包可能会影响消息发送。
- 使用
ping和traceroute检查网络延迟和路径:ping -c 10 <broker-ip> traceroute <broker-ip>
-
监控 Kafka 性能:
- 使用 Kafka 的监控工具(如 JMX Exporter, Prometheus, Grafana 等)来监控 Kafka 集群的性能,找出瓶颈所在。
-
调整批处理设置:
- Kafka 生产者默认会将多个消息批次合并后再发送,以提高效率。可以通过调整
batch.size和linger.ms配置项来优化这一行为:producer = Producer({ 'bootstrap.servers': '10.10.x.x:3082', 'security.protocol': 'SASL_PLAINTEXT', 'sasl.mechanism': 'SCRAM-SHA-512', 'sasl.username': 'kafka-974a3a34-bpxuser1', 'sasl.password': 'zjavIj4OPZNV2vALc2F>zesn8izaHEYP(ZK0IETrtKrMR5w+gUNpL60xkGhX3ca9', 'batch.size': 16384, # 16KB 'linger.ms': 100 # 100毫秒 })
- Kafka 生产者默认会将多个消息批次合并后再发送,以提高效率。可以通过调整
-
检查回调函数:
- 如果使用了回调函数
delivery_report,请确保它能够快速执行完毕,避免阻塞消息队列。
- 如果使用了回调函数
-
重启生产者实例:
- 如果以上方法都不能解决问题,可以尝试重启 Kafka 生产者实例,清空积压的消息。
Kafka 消费者配置及优化
1. 消费者配置
from confluent_kafka import Consumer
# Kafka 配置
config = {
'bootstrap.servers': '10.10.x.x:3082',
'security.protocol': 'SASL_PLAINTEXT',
'sasl.mechanism': 'SCRAM-SHA-512',
'sasl.username': 'kafka-974a3a34-bpxuser1',
'sasl.password': 'zjavIj4OPZNV2vALc2F>zesn8izaHEYP(ZK0IETrtKrMR5w+gUNpL60xkGhX3ca9',
'group.id': 'my-python-group' # 添加 group.id 配置项
}
# 创建消费者实例
consumer = Consumer(**config)
consumer.subscribe(['bpx']) # 替换Topic
try:
while True:
msg = consumer.poll(1.0) # 等待消息,超时为1秒
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
# End of partition event
print('End of partition reached {0}/{1}'.format(msg.topic(), msg.partition()))
elif msg.error():
raise KafkaException(msg.error())
else:
print('Received message: {}'.format(msg.value().decode('utf-8')))
finally:
# 关闭消费者连接
consumer.close()
2. 消费者优化建议
-
调整
fetch.min.bytes和fetch.max.wait.ms:fetch.min.bytes:消费者从服务器获取数据的最小字节数。增加这个值可以减少网络请求的次数,但可能会增加延迟。fetch.max.wait.ms:服务器在响应消费者请求之前等待更多数据的最长时间。增加这个值可以提高吞吐量,但可能会增加延迟。
consumer = Consumer({ 'bootstrap.servers': '10.10.x.x:3082', 'security.protocol': 'SASL_PLAINTEXT', 'sasl.mechanism': 'SCRAM-SHA-512', 'sasl.username': 'kafka-974a3a34-bpxuser1', 'sasl.password': 'zjavIj4OPZNV2vALc2F>zesn8izaHEYP(ZK0IETrtKrMR5w+gUNpL60xkGhX3ca9', 'group.id': 'my-python-group', 'fetch.min.bytes': 1048576, # 1MB 'fetch.max.wait.ms': 500 # 500毫秒 }) -
调整
max.poll.records:max.poll.records:每次poll调用返回的最大记录数。增加这个值可以提高吞吐量,但可能会增加内存使用量。
consumer = Consumer({ 'bootstrap.servers': '10.10.x.x:3082', 'security.protocol': 'SASL_PLAINTEXT', 'sasl.mechanism': 'SCRAM-SHA-512', 'sasl.username': 'kafka-974a3a34-bpxuser1', 'sasl.password': 'zjavIj4OPZNV2vALc2F>zesn8izaHEYP(ZK0IETrtKrMR5w+gUNpL60xkGhX3ca9', 'group.id': 'my-python-group', 'max.poll.records': 500 # 每次poll返回500条记录 }) -
自动提交偏移量:
enable.auto.commit:是否自动提交偏移量。自动提交可以简化代码,但可能会导致消息重复消费。auto.commit.interval.ms:自动提交偏移量的间隔时间。
consumer = Consumer({ 'bootstrap.servers': '10.10.x.x:3082', 'security.protocol': 'SASL_PLAINTEXT', 'sasl.mechanism': 'SCRAM-SHA-512', 'sasl.username': 'kafka-974a3a34-bpxuser1', 'sasl.password': 'zjavIj4OPZNV2vALc2F>zesn8izaHEYP(ZK0IETrtKrMR5w+gUNpL60xkGhX3ca9', 'group.id': 'my-python-group', 'enable.auto.commit': True, 'auto.commit.interval.ms': 1000 # 每1000毫秒自动提交一次 }) -
手动提交偏移量:
- 如果需要更精细的控制,可以手动提交偏移量,确保消息处理完成后才提交偏移量。
try: while True: msg = consumer.poll(1.0) if msg is None: continue if msg.error(): if msg.error().code() == KafkaError._PARTITION_EOF: print('End of partition reached {0}/{1}'.format(msg.topic(), msg.partition())) elif msg.error(): raise KafkaException(msg.error()) else: print('Received message: {}'.format(msg.value().decode('utf-8'))) consumer.commit(msg) # 手动提交偏移量 finally: consumer.close() -
处理消费者组再平衡:
- 消费者组再平衡可能会导致消息重复消费或丢失。可以通过设置
session.timeout.ms和heartbeat.interval.ms来优化再平衡过程。
consumer = Consumer({ 'bootstrap.servers': '10.10.x.x:3082', 'security.protocol': 'SASL_PLAINTEXT', 'sasl.mechanism': 'SCRAM-SHA-512', 'sasl.username': 'kafka-974a3a34-bpxuser1', 'sasl.password': 'zjavIj4OPZNV2vALc2F>zesn8izaHEYP(ZK0IETrtKrMR5w+gUNpL60xkGhX3ca9', 'group.id': 'my-python-group', 'session.timeout.ms': 30000, # 30秒 'heartbeat.interval.ms': 10000 # 10秒 }) - 消费者组再平衡可能会导致消息重复消费或丢失。可以通过设置
总结
通过以上配置和优化建议,可以进一步提高 Kafka 生产者和消费者的性能和稳定性。确保在实际应用中根据具体情况进行调整和优化,以达到最佳的性能表现。

















 2606
2606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









