



 本文介绍如何使用亚马逊商品评论、IMDB电影评论及Yelp点评数据集进行情感分析模型的搭建,包括词袋模型与TF-IDF结合逻辑回归的基础模型,以及词袋模型结合多层感知器的深度学习模型。
本文介绍如何使用亚马逊商品评论、IMDB电影评论及Yelp点评数据集进行情感分析模型的搭建,包括词袋模型与TF-IDF结合逻辑回归的基础模型,以及词袋模型结合多层感知器的深度学习模型。
本次采用的数据集分别是亚马逊商品评论数据(amazon_cells_labelled.txt)、IMDB电影评论数据(imdb_labelled.txt)、Yelp网站点评数据(yelp_labelled.txt)。数据下载地址为:https://download.youkuaiyun.com/download/herosunly/13183198
0. 读取数据
import pandas as pd
file_dict = {
'amazon': 'amazon_cells_labelled.txt',
'imdb': 'imdb_labelled.txt',
'yelp':'yelp_labelled.txt'
}
total_df = pd.DataFrame()
for k, v in file_dict.items():
single_df = pd.read_csv(v, sep = '\t', names = ['sent', 'label'])
single_df['source'] = k
total_df = total_df.append(single_df)
total_df = total_df.dropna() #取出所有只要有NA的行
1. baseline模型
每次都先以Yelp数据集为例。
1.1 词袋模型 + 逻辑回归
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
yelp = total_df[total_df.source == 'yelp']
x = yelp['sent']
y = yelp['label']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state = 1000)
vectorizer.fit(x_train)
x_train = vectorizer.transform(x_train)
x_test = vectorizer.transform(x_test)
logisitic_regression = LogisticRegression()
logisitic_regression.fit(x_train, y_train)
logisitic_regression.score(x_test, y_test) # 0.796
def get_df_predict_score(df):
df = df[df['label'].notnull()]
x = df['sent']
y = df['label']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state = 1000)
vectorizer = CountVectorizer()
vectorizer.fit(x_train)
x_train = vectorizer.transform(x_train).toarray()
x_test = vectorizer.transform(x_test).toarray()
logisitic_regression = LogisticRegression()
logisitic_regression.fit(x_train, y_train)
score = logisitic_regression.score(x_test, y_test)
return score
for i in file_dict.keys():
score = get_df_predict_score(total_df[total_df['source'] == i])
print('{} data score is {}'.format(i, score))
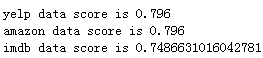
1.2 TF-IDF模型 + 逻辑回归
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
yelp = total_df[total_df.source == 'yelp']
x = yelp['sent']
y = yelp['label']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state = 1000)
vectorizer.fit(x_train)
x_train = vectorizer.transform(x_train)
x_test = vectorizer.transform(x_test)
logisitic_regression = LogisticRegression()
logisitic_regression.fit(x_train, y_train)
logisitic_regression.score(x_test, y_test) # 0.796
def get_df_predict_score(df):
df = df[df['label'].notnull()]
x = df['sent']
y = df['label']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state = 1000)
vectorizer = TfidfVectorizer()
vectorizer.fit(x_train)
x_train = vectorizer.transform(x_train).toarray()
x_test = vectorizer.transform(x_test).toarray()
logisitic_regression = LogisticRegression()
logisitic_regression.fit(x_train, y_train)
score = logisitic_regression.score(x_test, y_test)
return score
for i in file_dict.keys():
score = get_df_predict_score(total_df[total_df['source'] == i])
print('{} data score is {}'.format(i, score))
2. 深度学习模型
在深度学习中,通过观察训练过程中loss和metrics(在分类问题中可能为准确率)的变化,才能对模型的质量有个大体的评估。在Keras中,绘制loss和准确率曲线的代码如下所示:
其中plt.legend()是显示图例,如下图所示:

import matplotlib.pyplot as plt
def plot_history(history, name):
train_acc = history.history['acc']
train_loss = history.history['loss']
val_acc = history.history['val_acc']
val_loss = history.history['val_loss']
x = range(1, len(train_acc) + 1)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(x, train_acc, 'b', label='Training acc')
plt.plot(x, val_acc, 'r', label='Validation acc')
plt.title('Training and Validation accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(x, train_loss, 'b', label='Training loss')
plt.plot(x, val_loss, 'r', label='Validation loss')
plt.title('Training and Validation loss')
plt.legend()
plt.show()
plt.savefig(str(name) + '.png')
2.1 词袋模型 + MLP
from sklearn.feature_extraction.text import CountVectorizer
import keras
from keras.models import Sequential
from keras.layers import Dense, Activation
from sklearn.model_selection import train_test_split
x = yelp['sent']
y = yelp['label']
#划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state = 1000)
vectorizer = CountVectorizer()
vectorizer.fit(x_train)
x_train = vectorizer.transform(x_train).toarray()
x_test = vectorizer.transform(x_test).toarray()
input_dim = x_train.shape[1]
model = Sequential()
model.add(Dense(units = 10, input_dim = input_dim))
model.add(Dense(units = 1, activation = 'sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_train, y_train, batch_size = 32, epochs = 20)
loss, accuracy = model.evaluate(x_test, y_test)
print('test accuracy is', accuracy)
import keras
from keras.layers import Dense
from keras.models import Sequential
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
def get_df_predict_score(df):
df = df[df['label'].notnull()]
x = df['sent']
y = df['label']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state = 1000)
vectorizer = CountVectorizer()
vectorizer.fit(x_train)
x_train = vectorizer.transform(x_train).toarray()
x_test = vectorizer.transform(x_test).toarray()
input_dim = x_train.shape[1]
model = Sequential()
model.add(Dense(input_dim = input_dim, units = 10, activation="relu"))
model.add(Dense(units = 1, activation = 'sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs = 20, batch_size = 32, validation_split=0.2, verbose = False)
plot_history(history, 'result')
loss, accuracy = model.evaluate(x_test, y_test)
return accuracy
for i in file_dict.keys():
score = get_df_predict_score(total_df[total_df['source'] == i])
print('{} data score is {}'.format(i, score))



















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











