







互联网职位爬虫实现细节
本文是对互联网职位爬虫程序的流程进行基本的描述,概述了爬虫程序的运行流程,相关表结构,网页解析规则,反爬策略的应对措施等。
具体实现参考源码:https://github.com/laughoutloud61/jobSpider
开发环境
开发使用的框架:scrapy, scrapy-redis
开发使用的数据库(服务器):Elasticsearch, redis
实现目标
开发分布式爬虫系统,爬取目标网页(拉勾网)详细页面信息的抓取。并将抓取的信息进行清洗,存入Elasticsearch服务器中。
表结构的定义
分析详细页面,确定要爬取的信息
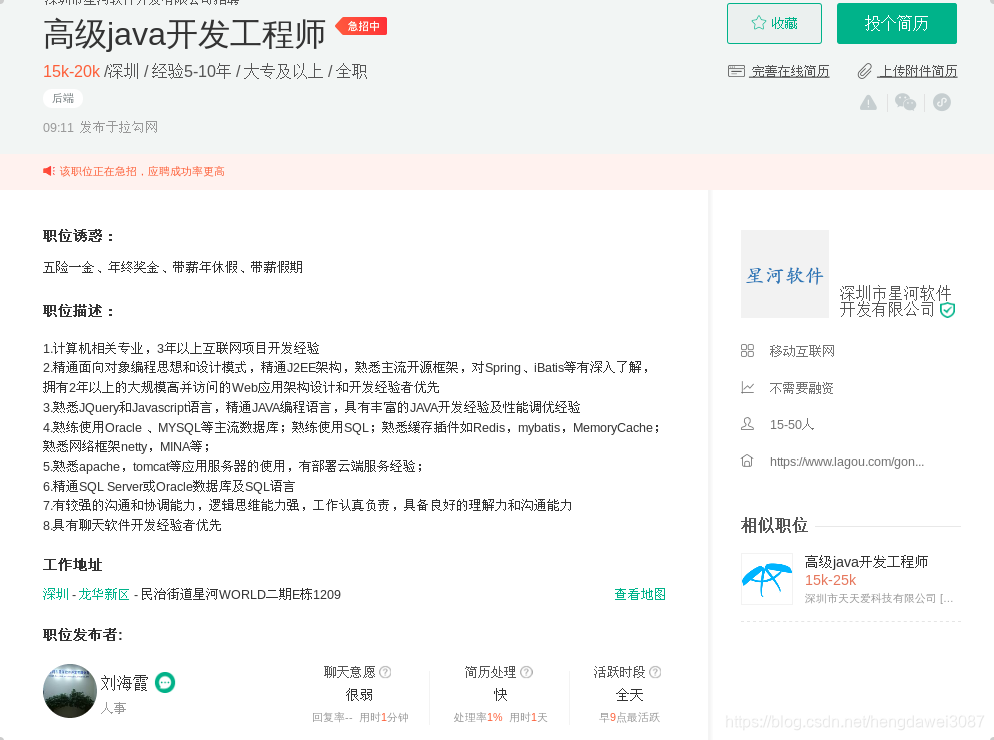 根据页面信息分析,定义如下爬虫数据结构
根据页面信息分析,定义如下爬虫数据结构
class JobSpiderItem(Item):
id = Field(
input_processor=MapCompose(get_id)
)
job_name = Field()
url = Field()
salary = Field(
input_processor=MapCompose(extract_digital),
output_processor=MapCompose(get_value)
)
city = Field()
work_experience = Field(
input_processor=MapCompose(extract_digital),
output_processor=MapCompose(get_value)
)
education = Field(
input_processor=MapCompose(education_process)
)
skills = Field(
input_processor=MapCompose(extract_word),
output_processor=MapCompose(get_value)
)
tags = Field(
output_processor=MapCompose(get_value)
)
platform = Field()
release_time = Field(
input_processor=MapCompose(extract_time)
)
company_name = Field(
inpu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1746
1746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









