








爬取拉勾网站岗位数据
1、调用网页
查找网页链接规律

写一个for循环,爬取每一个网页的职位信息
def down():
for i in range(1,4):
if i == 1:
strUrl = "http://72.itmc.org.cn/JS001/open/show/zhaopin/index.html"
else:
strUrl ="http://72.itmc.org.cn/JS001/open/show/zhaopin/index_" + str(i) + ".html"
print(strUrl)
2、找到网页节点
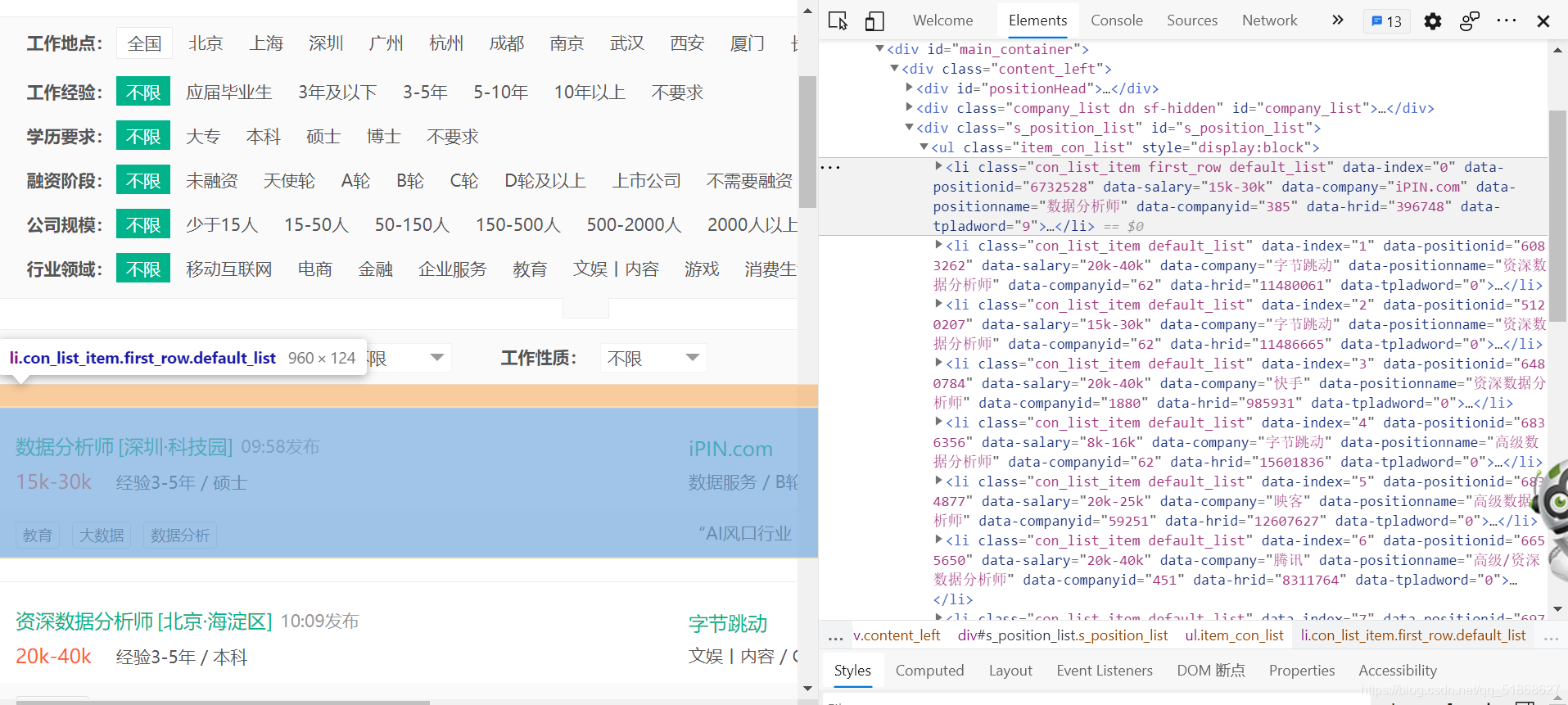
网页源代码里面的 li 标签对已经包含了每个岗位的职位名称、发布公司、薪酬等,现在只需要用BeautifulSoup的find功能找到所有的 li 节点
def parserWebContent(content):
bs = BeautifulSoup(content,"html.parser")
dicts = {
"class":"item_con_list",
"style" : "display:block"
}
ulTag = bs.find("ul",dicts)
#print(ulTag)
liTags = ulTag.find_all("li")
#print(len(liTags))
for liTag in liTags:
parseProductTag(liTag)
3、取出需要的职位信息
def parseProductTag(productTag):
index = 0
for subTag in productTag.div.contents:
#print(index)
#print(subTag)
pass #以上是调试代码
name = productTag["data-positionname"]
salary = productTag["data-salary"]
company = productTag["data-company"]
print(name,salary,company)
采用直接取出
【data-positionname】职位名称
【data-salary】工资待遇
【data-company】招聘公司
4、全部代码
import requests
from bs4 import BeautifulSoup
heads = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
#模拟用户登录,防止反爬虫
def parseProductTag(productTag):
index = 0
for subTag in productTag.div.contents:
#print(index)
#print(subTag)
pass
name = productTag["data-positionname"]
salary = productTag["data-salary"]
company = productTag["data-company"]
print(name,salary,company)
#写入文件
f = open("rencaiwang.txt",mode="a+",encoding="utf-8")
f.write(name + ";" + salary + ";" + company +"\n")
f.close()
def parserWebContent(content):
bs = BeautifulSoup(content,"html.parser")
dicts = {
"class":"item_con_list",
"style" : "display:block"
}
ulTag = bs.find("ul",dicts)
#print(ulTag)
liTags = ulTag.find_all("li")
#print(len(liTags))
for liTag in liTags:
parseProductTag(liTag)
def downWebContent(url):
r = requests.get(url,headers = heads)
print(r.status_code)
r.encoding = r.apparent_encoding
#print(r.text)
parserWebContent(r.text)
def down():
for i in range(1,4):
if i == 1:
strUrl = "http://72.itmc.org.cn/JS001/open/show/zhaopin/index.html"
else:
strUrl ="http://72.itmc.org.cn/JS001/open/show/zhaopin/index_" + str(i) + ".html"
print(strUrl)
downWebContent(strUrl)
break
down()#调用上面定义的函数

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









