







Java堆和栈是Java虚拟机(JVM)内存管理中的两个重要部分,它们在存储和管理数据方面有着显著的区别。理解这些区别对于编写高效、稳定的Java程序至关重要。本文将详细讨论Java堆和栈的主要区别,帮助你更好地理解Java内存管理。
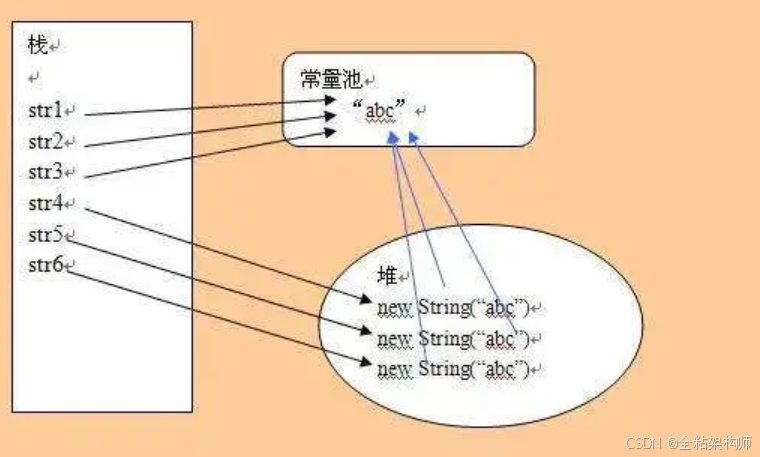
一、存储方式
Java堆是动态分配的内存空间,主要用于存储对象实例。它是所有线程共享的区域,因此具有可扩展性。当系统运行时,可以根据需要自动调整堆的大小。堆内存的分配主要通过垃圾回收器自动管理,程序员一般不需要手动介入。
相对而言,Java栈是每个线程私有的一块内存区域,用于存储基本数据类型、对象引用和对象本身。每个方法在执行时都会创建一个栈帧,用于存储局部变量、操作数栈、动态链接和方法出口信息。每个线程在创建时都会创建一个栈,并且这个栈会随着方法的执行而不断增长和缩小。因此,栈内存的生命周期与线程相同。
二、内存特点
- 堆内存的特点是动态分配和动态扩展。它是所有线程共享的区域,主要用于存储对象实例。堆内存的大小可以在运行时动态调整,但堆内存的分配和回收需要经过垃圾回收器的处理。由于堆内存的动态性,它可能会导致内存碎片化的问题。
- 栈内存的特点是线程私有和先进后出(LIFO)。每个线程在创建时都会创建一个栈,并且这个栈会随着方法的执行而不断增长和缩小。栈内存的生命周期与线程相同,当一个方法被调用时,会在栈上为其创建一个栈帧,当方法执行完成后,该栈帧会被销毁。由于栈内存的线程私有性,它不会出现并发访问的问题。此外,由于栈内存的先进后出特点,可以很好地支持方法的递归调用。
三、垃圾回收机制
- 堆内存:堆内存中的对象由垃圾回收器自动管理。当一个对象不再被引用时,垃圾回收器会自动将其标记为可回收的对象,并在适当的时候释放其占用的内存。垃圾回收器的具体算法包括标记-清除(Mark and Sweep)、复制(Copying)、标记-压缩(Mark and Compact)等。
- 栈内存:由于栈内存的生命周期与线程相同,当一个线程结束执行时,其占用的栈内存也会被自动回收。因此,垃圾回收器一般不需要对栈内存进行特殊处理。
四、性能影响
- 堆内存:由于堆内存的动态分配和扩展性,可能会导致内存碎片化的问题。频繁的内存分配和回收操作也可能影响程序的性能。此外,由于堆内存是所有线程共享的区域,因此可能会出现并发访问的问题,需要进行适当的同步控制。
- 栈内存:由于栈内存的先进后出特点,可以很好地支持方法的递归调用。同时,由于栈内存的线程私有性,不会出现并发访问的问题。此外,由于栈内存的生命周期与线程相同,当一个线程结束执行时,其占用的栈内存也会被自动回收,因此不会出现内存泄漏的问题。
五、使用场景
- 堆内存:堆内存主要用于存储对象实例,因此几乎所有的Java程序都会使用到堆内存。对于需要频繁创建和销毁对象的程序,需要注意堆内存的使用情况,避免出现OutOfMemoryError错误。
- 栈内存:由于每个方法执行时都会在栈上创建一个栈帧,因此对于方法调用较为频繁的程序,需要注意栈内存的使用情况。如果一个方法调用的层级过深或者局部变量过多,可能会导致栈溢出的问题。此外,对于一些需要长时间运行的程序(如线程或者服务),需要注意其占用的栈空间大小,避免出现栈溢出或者过度消耗系统资源的情况。
六、总结
Java堆和栈作为Java虚拟机内存管理的重要组成部分,在存储方式、内存特点、垃圾回收机制和使用场景等方面有着显著的区别。理解这些区别可以帮助我们更好地编写高效、稳定的Java程序。在实际开发中,需要根据程序的特性和需求选择合适的数据结构和算法,合理地利用堆和栈的优势来提高程序的性能和稳定性。同时,也需要关注堆和栈的使用情况,避免出现内存溢出或者资源过度消耗的问题。


















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











