






 本文介绍了使用sqoop将数据从Hive导出到MySQL的过程,强调了需要预先在MySQL中创建表,明确Hive表在HDFS中的位置,并启动MapReduce History Server以查看报错日志。特别注意MapReduce日志对于排查错误的重要性,以及正确配置字段分隔符和行终止符。
本文介绍了使用sqoop将数据从Hive导出到MySQL的过程,强调了需要预先在MySQL中创建表,明确Hive表在HDFS中的位置,并启动MapReduce History Server以查看报错日志。特别注意MapReduce日志对于排查错误的重要性,以及正确配置字段分隔符和行终止符。
首先把修正后的脚本放出来,然后在说说踩得那些坑!
可以直接下滑到中间从看特别注意开始看。
sqoop export 脚本:
/home/huser/sqoop-1.4.7/bin/sqoop export --connect "jdbc:mysql://localhost9:3306/analysisuseUnicode=true&characterEncoding=
utf-8" \
--username mysql \
--password Pass2020 \
--table tmp_dws_visit_source \
--columns days,visitSourceType,visitSource \
--input-fields-terminated-by '^A' \
--input-lines-terminated-by '\n' \
--input-null-string '\\N' \
--input-null-non-string '\\N' \
--export-dir "hdfs://hadooprt:9000/user/hive/warehouse/rt1.db/dws_visit_source/everyday=2020-08-06/" \
-m 1;mysql创建表脚本:
#!/bin/bash
everyday="2020-08-06"
sql=$(cat << !EOF
use database;
drop table dws_visit_source;
create table if not exists dws_visit_source(
days string,
visitSourceType string,
visitSource string
)
partitioned by (everyday string)
row format delimited
fields terminated by '^A'
lines terminated by '\n'
stored as textfile;
insert into table dws_visit_source partition(everyday='$everyday1')
select everyday,visitSourceType,visitSource
from cr_t_test08 where everyday='$everyday' group by visitSourceType,visitSource;
exit;
!EOF)
$HIVE_HOME/bin/hive -e "$sql"
exitCode=$?
if [ $exitCode -ne 0 ];then
echo "[ERROR] hive execute failed!" >> tmplog.txt
exit $exitCode
fimysql数据库字符设置:
alter database analysis character set utf8 collate utf8_general_ci;==============================================================
注意事项:
sqoop 导出hive到mysql,需要mysql中创建好表:
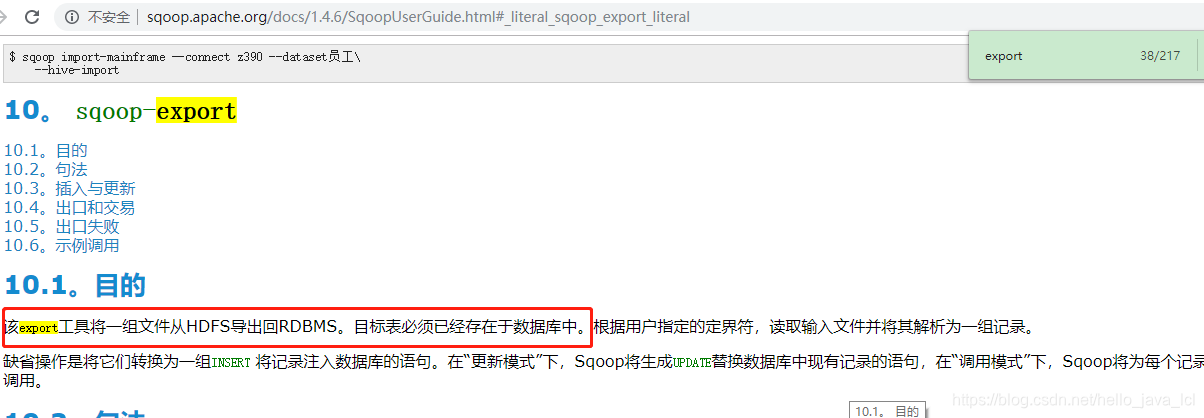
sqoop导出hive表,需要知道表在hdfs中的位置,指定的是hive表在文件中的路径:
--export-dir "hdfs://hadooprt:9000/user/hive/warehouse/rt1.db/dws_visit_source/everyday=2020-08-06/" \查询hive表的存储位置:
show create table dws_visit_source; 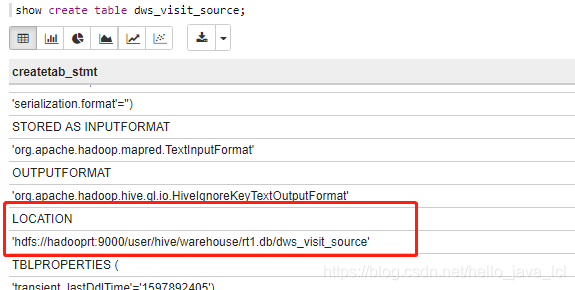
======================================================================
特别注意:如果用sqoop导出导入数据,需要把MapReduce History server启动起来,方便查看报错日志,启动命令:
$HADOOP_HOME/sbin/mr-jobhistory-deamon.sh start historyserver查看网页:http://hadoop(主机名或IP地址):18088/cluster
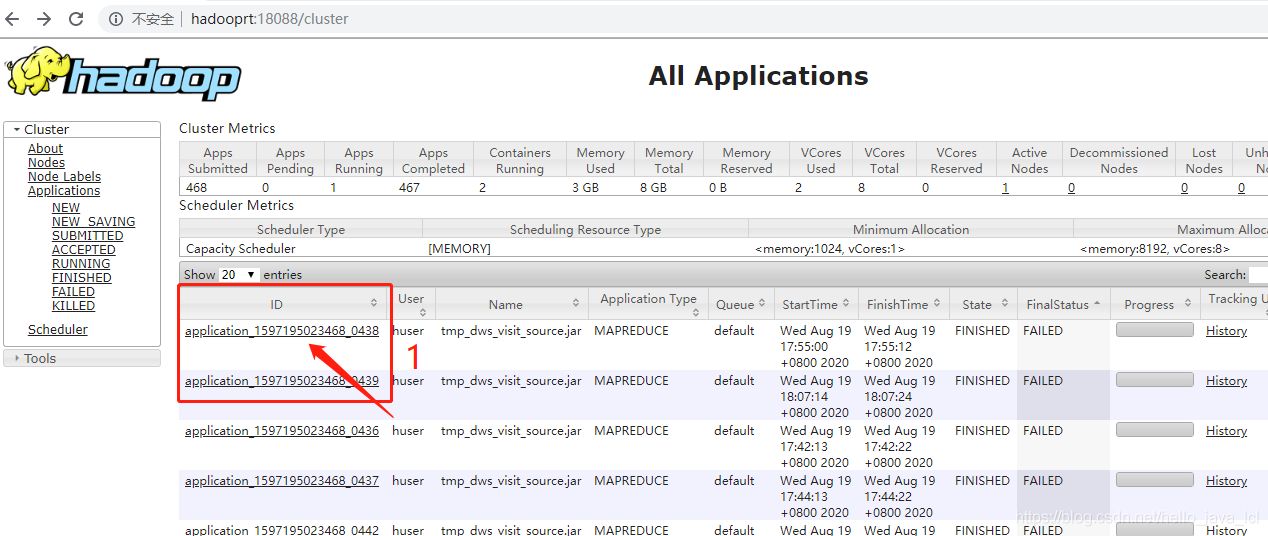
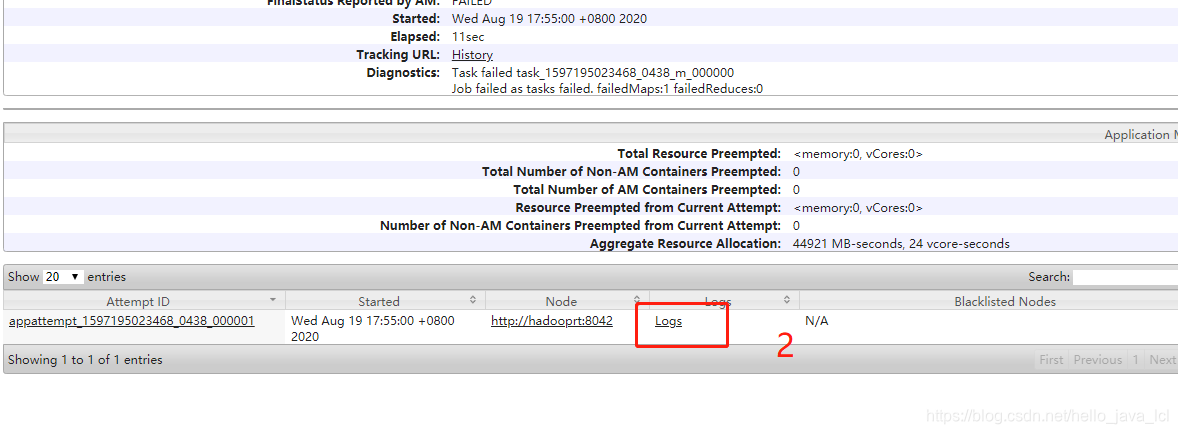
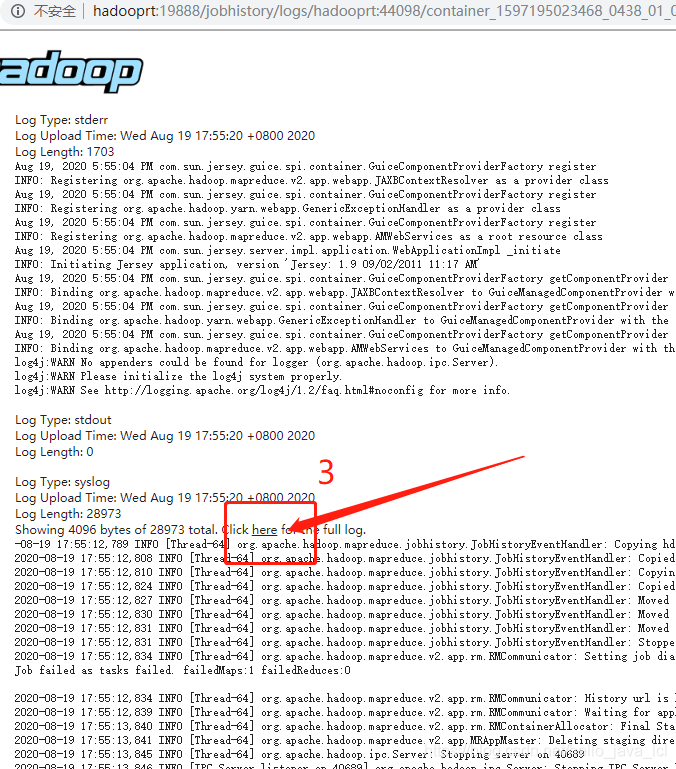
就可以查看详细日志了。
=====================================================================
如果日志中有如下类似报错,需要查看几处地方:
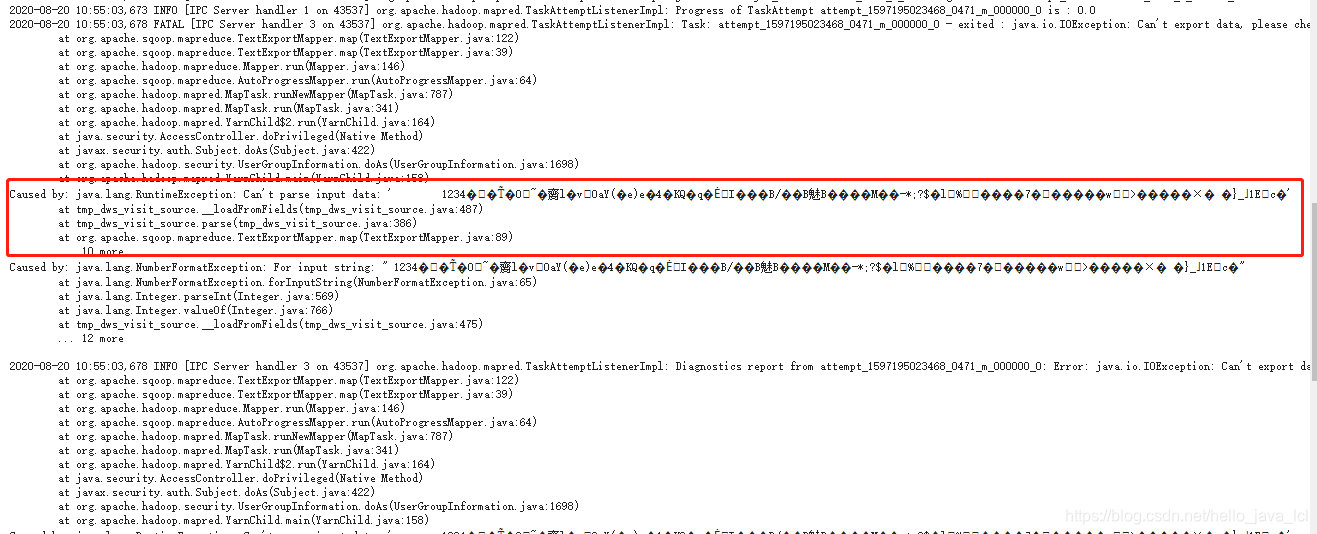
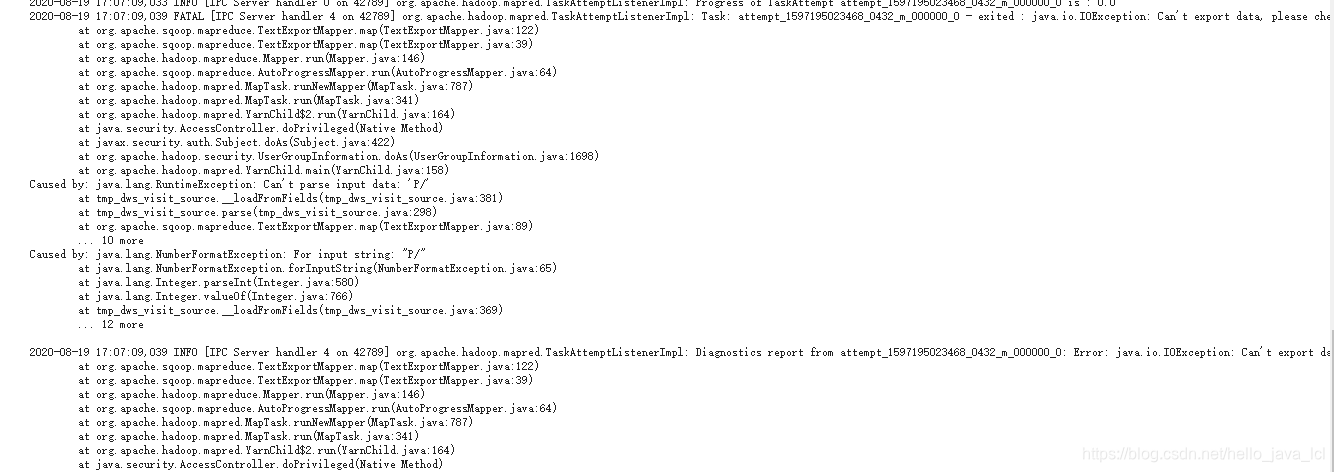
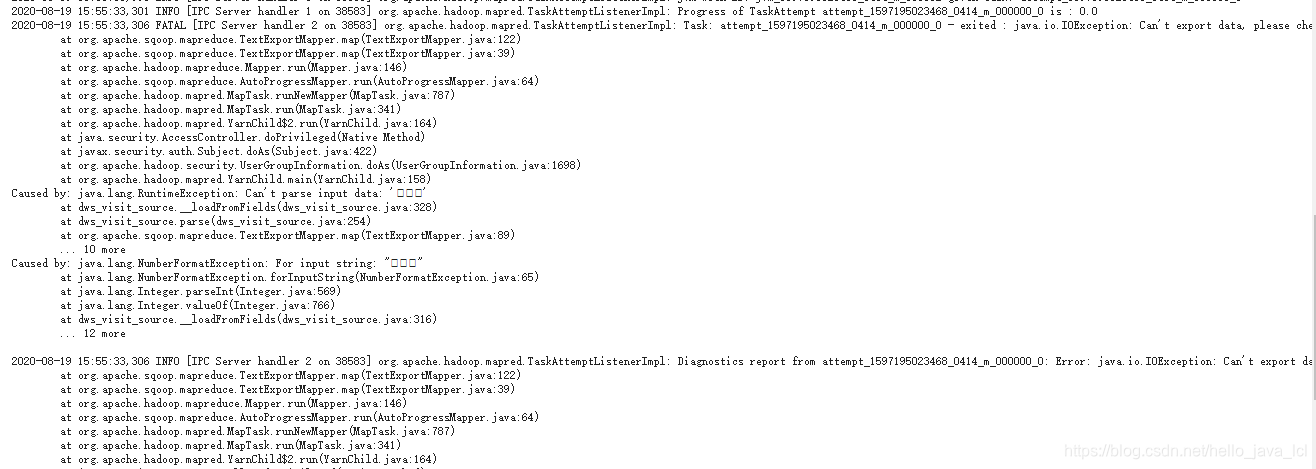
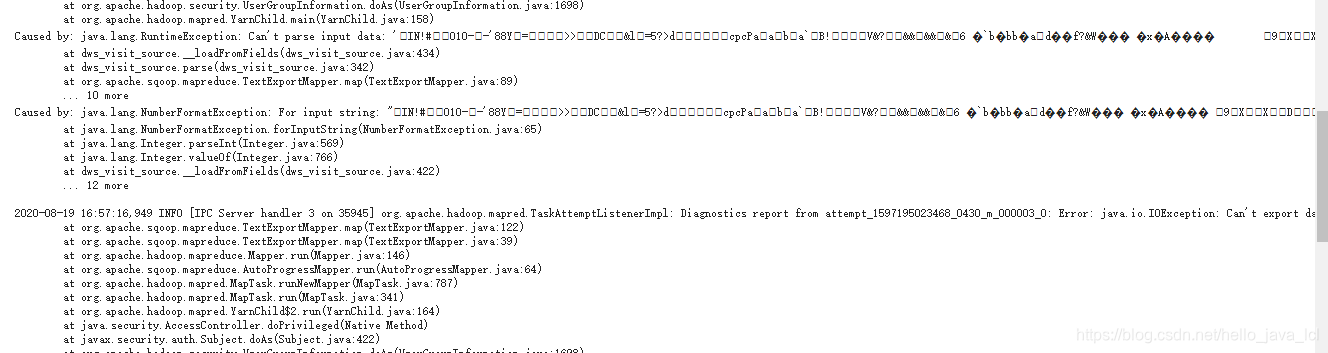
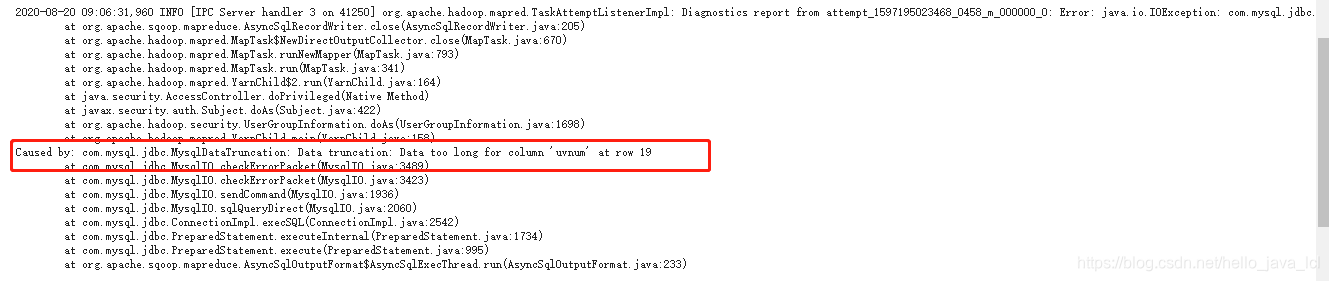
检查位置:
最先检查的一点:hive的文件存储格式!Sqoop 从hdfs 同步数据到mysql,hive 中的表 必须是textfile 。我就是这个问题,一开始设置的orc,导出找问题改改改,一天以后,发现的这个,然后成功导入数据╮(╯▽╰)╭ |
| sqoop导出脚本中的--input-fields-terminated-by和创建hive表时的fields terminated by '^A'是不是一致的分隔符! |
| sqoop export 中是否设置了--input-null-string '\\N' \ 和 --input-null-non-string '\\N' \ |
| sqoop export导出字段是否和mysql字段存在错位,如果有错位,可能报错数据转换异常或数据太长异常 |
| 如果导入数据了,但是mysql中中文乱码,加 useUnicode=true&characterEncoding=utf-8" \ |
| 注意 ^A 一定是手动 Ctrl+v+A 敲上去的,刚刚试验了,复制的都偶尔不好使。╮(╯▽╰)╭ |
create table if not exists dws_visit_source(
days string,
visitSourceType string,
visitSource string
)
partitioned by (everyday string)
row format delimited
fields terminated by '^A'
lines terminated by '\n'
stored as textfile;--注意,很重要
/home/huser/sqoop-1.4.7/bin/sqoop export --connect "jdbc:mysql://localhost:3306/analysis?useUnicode=true&characterEncoding=utf-8" \
--username mysql \
--password Pass2020 \
--table tmp_dws_visit_source \
--columns days,visitSourceType,visitSource \
--input-fields-terminated-by '^A' \
--input-lines-terminated-by '\n' \
--input-null-string '\\N' \
--input-null-non-string '\\N' \
--export-dir "hdfs://hadooprt:9000/user/hive/warehouse/rt1.db/dws_visit_source/everyday=2020-08-06/" \
-m 1;

















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









