




 本文详细介绍了如何使用pandas在Python中进行DataFrame的纵向(axis=0)和横向(axis=1)合并,以及通过join参数实现外连接和内连接。此外,还讲解了ignore_index和keys选项的作用,以及在keys和levels使用场景。
本文详细介绍了如何使用pandas在Python中进行DataFrame的纵向(axis=0)和横向(axis=1)合并,以及通过join参数实现外连接和内连接。此外,还讲解了ignore_index和keys选项的作用,以及在keys和levels使用场景。
import pandas as pd
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
index=[4, 5, 6, 7],
)
df3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
},
index=[8, 9, 10, 11],
)
df4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)

参数
#ALL default
data = pd.concat([df1, df2],
axis = 0,
join = "outer",
ignore_index = False,
keys = None,
levels = None,
names = None,
verify_integrity = False,
copy = True
)
axis = 0 纵向合并
df4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)
pd.concat([df1, df4], axis=0)
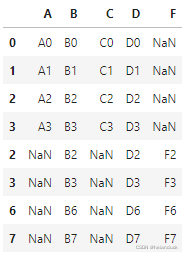
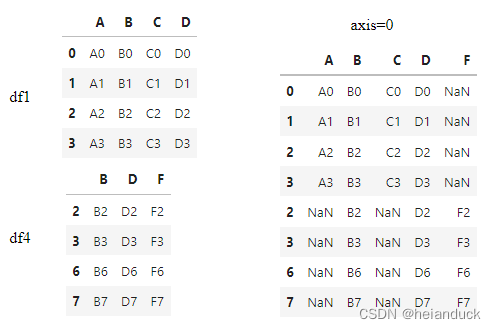
axis = 1 横向合并
df4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)
pd.concat([df1, df4], axis=1)
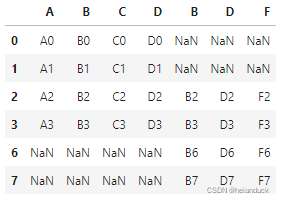
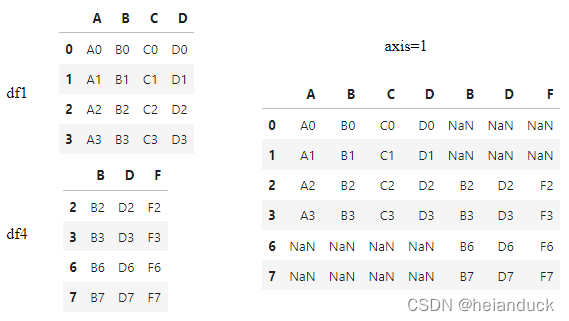
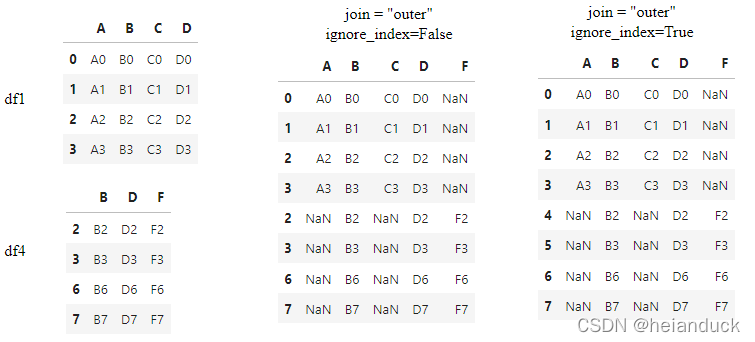
join = "outer" 纵向取并集
pd.concat([df1, df4], axis=0, join="outer")
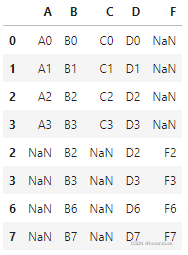

join = "inner" 纵向取交集
#保留相同的列索引。
pd.concat([df1, df4], axis=0, join="inner")


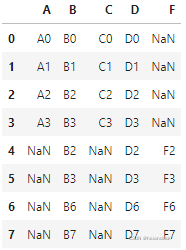
ignore_index=True
False可查看join = "outer" 纵向取并集
# True代表,两个dataframe合并之后,index不再使用各自的,而是相当于全体重置
pd.concat([df1,df4], axis=0, join="outer",ignore_index=True)
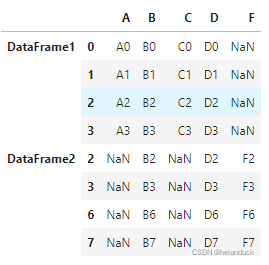
keys 嗯,有点难以用语言表达,找个头头?
#可以用list
pd.concat([df1, df4], axis=0, join="outer",\
ignore_index=False,keys=["DataFrame1","DataFrame2"])
#也可以用tuple
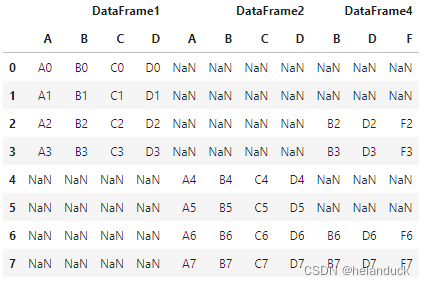
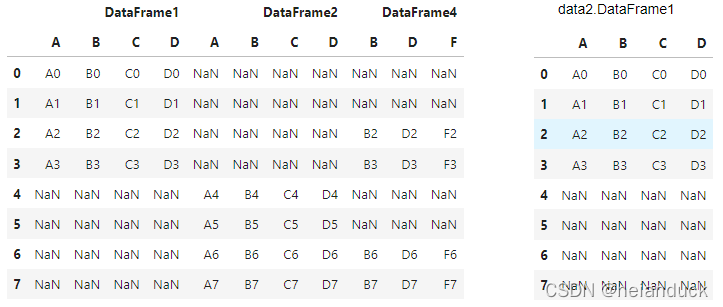
data2 = pd.concat([df1, df2, df4], axis=1, \
join="outer",ignore_index=False,keys=\
("DataFrame1","DataFrame2","DataFrame4"))
data2.DataFrame1
#当keys有重复时,使用verify_interity 就护报错。
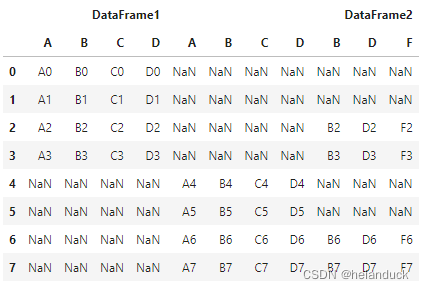
pd.concat([df1, df2, df4], axis=1, \
join="outer",keys=("DataFrame1","DataFrame2",\
'DataFrame2'),verify_integrity = True)
levels 我感觉没什么大用处,就没测(实际是测了也不知道有啥用)
names 用他前提是用levels,我跳
#当keys有重复时,使用verify_interity 就护报错。
pd.concat([df1, df2, df4], axis=1, \
join="outer",keys=("DataFrame1","DataFrame2",\
'DataFrame2'),verify_integrity = True)



















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











