






总结
- 单例对象一般会被多线程访问,所以单例对象中的数据在访问的时候最好加锁
多线程访问同一个变量
多个线程在执行任务的时候,每个线程都有一个锁,如果锁被一个线程拿到了,另一个就会被阻塞等待,直到锁被释放了,突然意识到忙等锁才行
多线程数据竞争
假如有一个变量shared_variable被10个线程共享,每个线程在循环中对shared_variable进行 1000 次累加操作,我们期望最终值为10000。
#include <iostream>
#include <thread>
#include <vector>
int shared_variable = 0; // 共享变量
void thread_function() {
for (int i = 0; i < 1000; ++i) {
// 模拟长延迟,增加竞争机会
std::this_thread::sleep_for(std::chrono::milliseconds(1));
shared_variable++;
}
}
int main() {
const int num_threads = 10;
std::vector<std::thread> threads;
// 创建多个线程
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back(thread_function);
}
// 等待所有线程完成
for (auto& t : threads) {
t.join();
}
std::cout << "Final value: " << shared_variable << std::endl; // 输出最终结果
return 0;
}
实际运行我们发现,shared_variable值通常会小于 10000,并且每次运行结果不同。这是因为多个线程同时读取和修改shared_variable,导致其值被错误覆盖。++shared_variable是一个非原子操作,包含三步:
- 读取当前值。
- 加 1。
- 写回新值。
在多线程环境中,这三步之间可能会被其他线程打断,导致结果不一致。例如:
- 线程 A 读取到值 100,准备加 1。
- 线程 B 同时读取到值 100,也准备加 1。
- 线程 A 写回值 101。
- 线程 B 写回值 101(假设线程 B 未看到线程 A 的修改)。
期望的值应为 102,但实际上变为 101,导致错误。这就是在多线程编程中不使用锁导致数据竞争的典型问题。
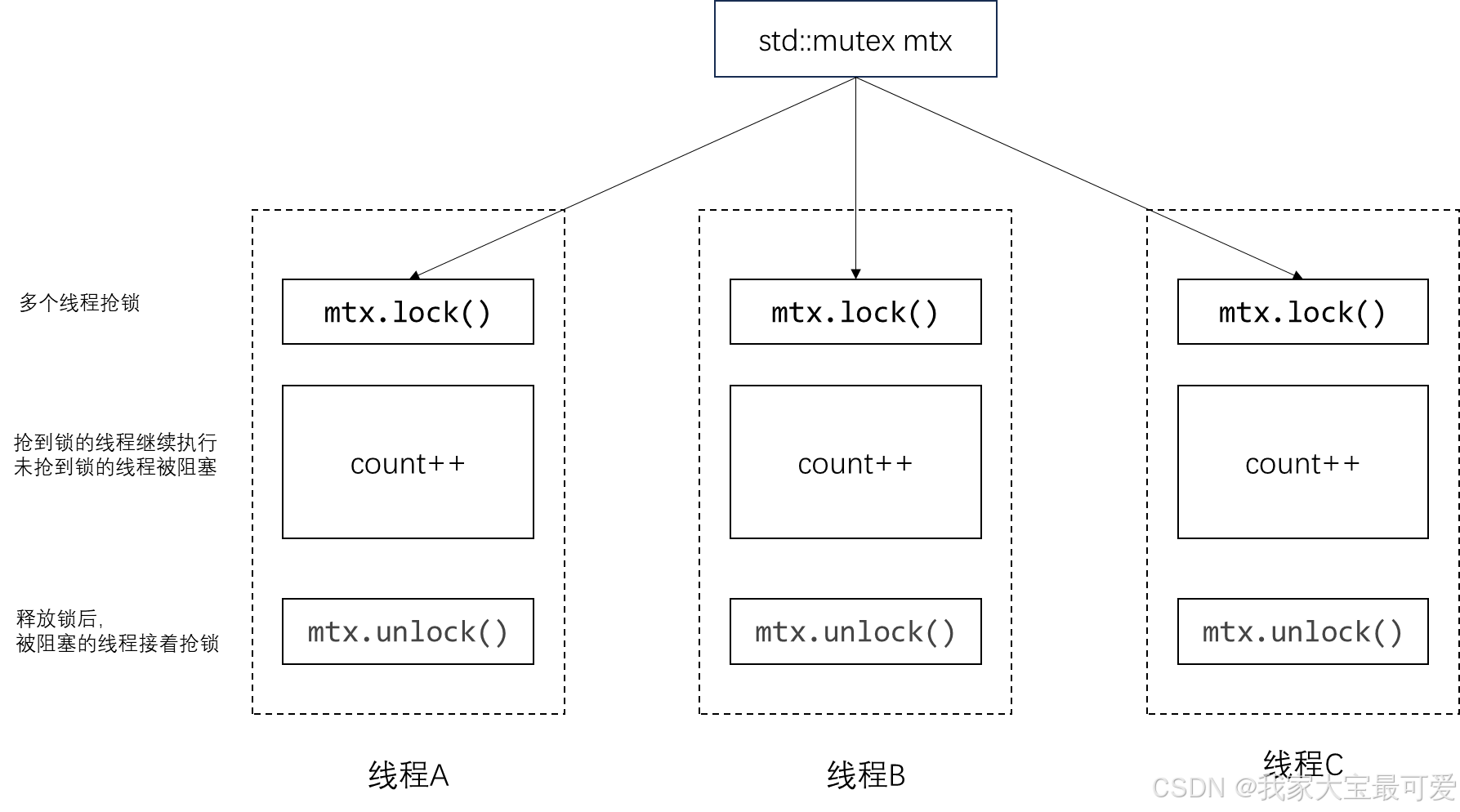
使用锁同步
锁是一种同步机制,用于协调多个线程对共享资源的访问。它类似于现实生活中的锁,可以确保一次只有一线程能访问特定的资源,其他线程必须等待锁被释放才能继续执行。在多线程编程中,锁的主要作用是防止数据竞争和一致性问题,确保对共享数据的正确操作和访问顺序。
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
std::mutex mtx; // 互斥锁
int shared_variable = 0; // 共享变量
void thread_function() {
for (int i = 0; i < 1000; ++i) {
std::lock_guard<std::mutex> lock(mtx); // 获取锁
shared_variable++;
// 模拟长延迟,增加竞争机会
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
}
int main() {
const int num_threads = 10;
std::vector<std::thread> threads;
// 创建多个线程
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back(thread_function);
}
// 等待所有线程完成
for (auto& t : threads) {
t.join();
}
std::cout << "Final value: " << shared_variable << std::endl; // 输出最终结果
return 0;
}
复合操作中的竞争条件问题
当shared_vector正在被一个线程修改时,另一个线程可能读取了无效的内存地址,导致内存越界和段错误。例如当多个线程同时执行复合操作时(例如,先检查 size() 再访问元素),仍然需要外部同步,因为复合操作本身不是原子的。
if (vec.size() > 0) { // 操作1:检查条件
int value = vec.at(0); // 操作2:访问元素
}
具体的例子如下所示
#include <iostream>
#include <vector>
#include <thread>
#include <chrono>
std::vector<int> shared_vector; // 共享的 vector
// 写线程,不断向 vector 中添加元素
void writer_thread()
{
for (int i = 0; i < 1000000; ++i) {
shared_vector.push_back(i); // 1. 线程A添加一个元素,vector不为空
std::this_thread::sleep_for(std::chrono::nanoseconds(1)); // 模拟延迟
shared_vector.clear(); // 3. 清空 vector
}
}
// 操作线程,不断清空 vector 并访问最后一个元素
void reader_thread()
{
while (true) {
if (!shared_vector.empty()) { // 2. 线程B对vector判空
std::this_thread::sleep_for(std::chrono::nanoseconds(1)); // 模拟延迟
int last_element = shared_vector.at(0); // 4. 尝试访问第一个元素,可能导致越界访问
std::cout << "Last element: " << last_element << std::endl;
}
}
}
int main()
{
std::thread t1(writer_thread);
std::thread t2(reader_thread);
t1.join();
t2.join();
return 0;
}
这种情况还比较好分析,vector在添加元素超过某个size的时候会重新申请一块地址,如果另一个线程还在访问之前的地址,就会造成非法访问的问题
解决方案就是通过锁来保证复合操作的
std::mutex mtx;
std::vector<int> vec;
if (mtx.lock()) {
if (vec.size() > 0) {
int value = vec.at(0);
// 处理 value
}
mtx.unlock();
}

















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









