







 超级会员免费看
超级会员免费看
最新大语言的模型,很多都是支持多模态的,通过以下链接查看你使用的模型是否支持多模态。
https://python.langchain.com/docs/integrations/chat/
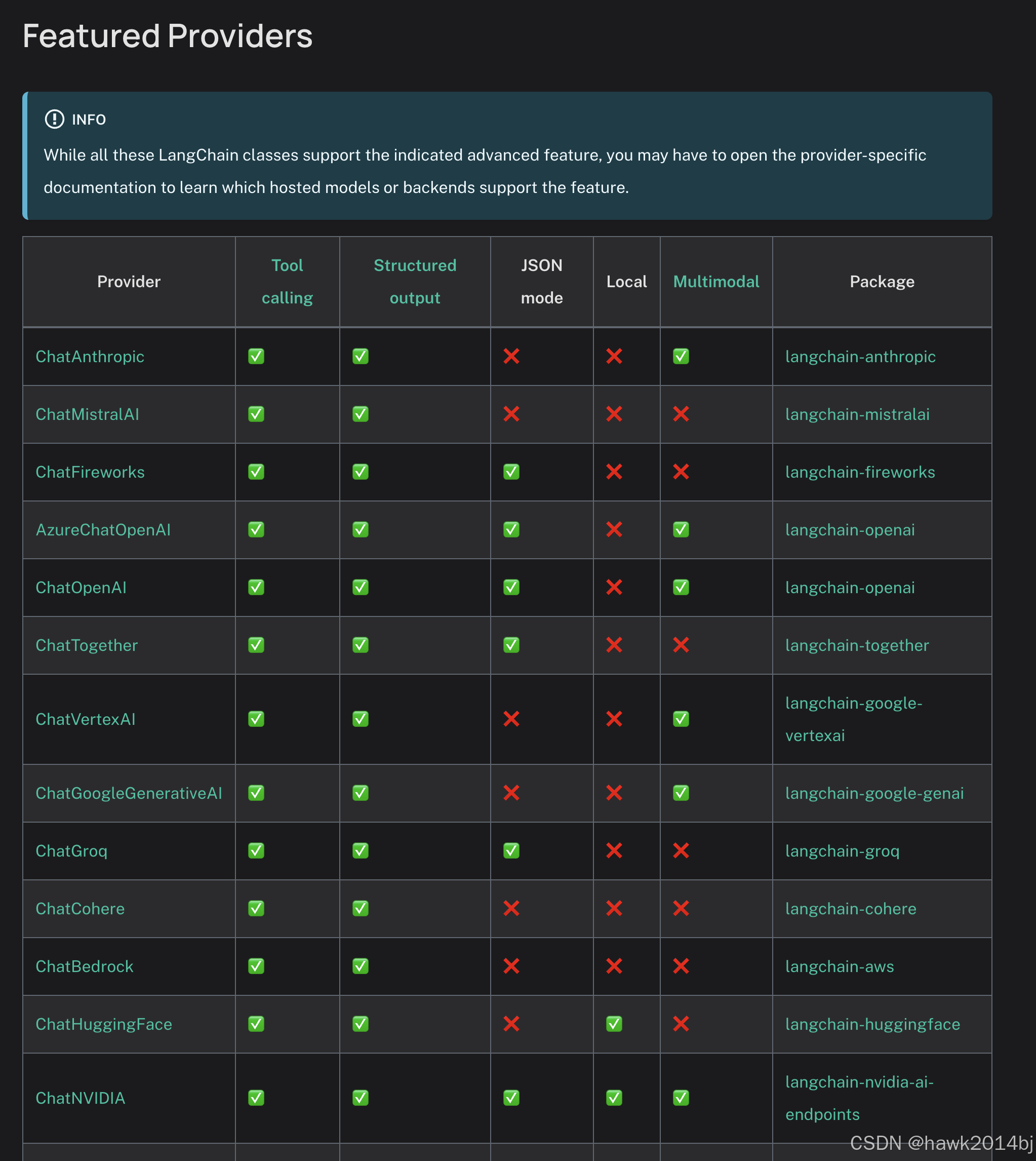
在Langchain 中,如果你使用的模型是支持多模态的,Langchain 已经进行了抽象,只需要将图片作为提示词的一个参数即可。
使用网络图片
将网络图片地址传给模型进行解析。
## Gemini
from langchain_google_genai import ChatGoogleGenerativeAI
import base64
model = ChatGoogleGenerativeAI(model="gemini-2.0-flash-exp")
image_url = "https://jiucaigongshe.oss-cn-beijing.aliyuncs.com/merchant/1737530260886dac0b4bf93c598c340ef604f443c2eca.png?x-oss-process=image/auto-orient,1/resize,w_1280/watermark,type_ZmFuZ3poZW5naGVpdGk,size_42,text_6Z-t56C
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









