









 本文深入解析了RDN(Residual Dense Network)超分辨率网络结构,对比了其与DenseNet、SRDenseNet及MemNet的区别,详细介绍了网络组成部分,包括SFFNet、RDBs、DFF及UPNet,并提供了PyTorch代码实现。
本文深入解析了RDN(Residual Dense Network)超分辨率网络结构,对比了其与DenseNet、SRDenseNet及MemNet的区别,详细介绍了网络组成部分,包括SFFNet、RDBs、DFF及UPNet,并提供了PyTorch代码实现。
【文章阅读】【超解像】–Residual Dense Network for Image Super-Resolution
论文链接:https://arxiv.org/pdf/1802.08797.pdf
code:https://github.com/yulunzhang/RDN
1.主要贡献
本文作者结合Residual Black和Dense Black提出了RDN(Residual Dense Network)网络结构,网络主要由RDB(Residual Dense block)网络组成,网络的结构图如下:
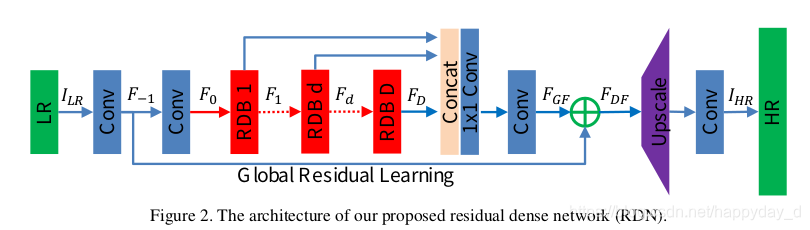

2.论文分析
如上图,网络主要由四部分构成:
(1) SFFNet(shallow feature extraction net)
上图中的前两个卷基层组成了SFFNet,上图中的 F 0 = H S F E 2 ( F − 1 ) F _ { 0 } = H _ { S F E 2 } \left( F _ { - 1 } \right) F0=HSFE2(F−1), F − 1 = H S F E 1 ( I L R ) F _ { - 1 } = H _ { S F E 1 } \left( I _ { L R } \right) F−1=HSFE1(ILR) F 0 F_0 F0为SFFNet输出.
(2) RDBs(redidual dense blocks)
上图中
F
1
,
F
d
F_1,Fd
F1,Fd表示该模块的中间模块输出,根据之前的输入获得:
F
d
=
H
R
D
B
,
d
(
F
d
−
1
)
=
H
R
D
B
,
d
(
H
R
D
B
,
d
−
1
(
⋯
(
H
R
D
B
,
1
(
F
0
)
)
⋯
 
)
)
\begin{aligned} F _ { d } & = H _ { R D B , d } \left( F _ { d - 1 } \right) \\ & = H _ { R D B , d } \left( H _ { R D B , d - 1 } \left( \cdots \left( H _ { R D B , 1 } \left( F _ { 0 } \right) \right) \cdots \right) \right) \end{aligned}
Fd=HRDB,d(Fd−1)=HRDB,d(HRDB,d−1(⋯(HRDB,1(F0))⋯))
该模块的结构图为:
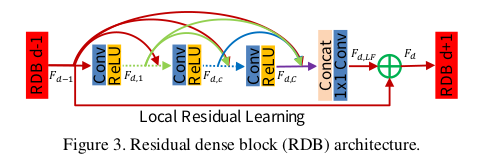
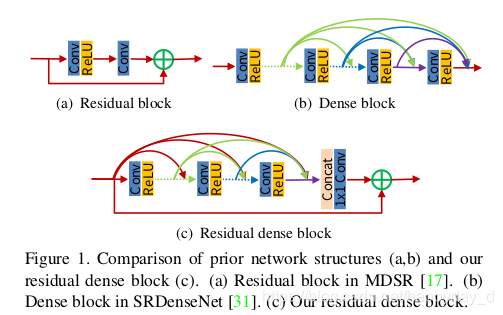
该模块将残差模块Residual block和dense block模块进行了整合,三个模块的区别如下:
RDB模块的输入是
F
d
−
1
F_{d-1}
Fd−1,输出
F
d
F_d
Fd,
G
0
G_0
G0表示
F
d
−
1
F_{d-1}
Fd−1和
F
d
F_{d}
Fd的特征向量数,RDB中间某层输出为:
F
d
,
c
=
σ
(
W
d
,
c
[
F
d
−
1
,
F
d
,
1
,
⋯
 
,
F
d
,
c
−
1
]
)
F _ { d , c } = \sigma \left( W _ { d , c } \left[ F _ { d - 1 } , F _ { d , 1 } , \cdots , F _ { d , c - 1 } \right] \right)
Fd,c=σ(Wd,c[Fd−1,Fd,1,⋯,Fd,c−1])
假设
F
d
,
c
F_{d,c}
Fd,c包含
G
G
G个特征图(
G
G
G也被称为增长率);
RDB模块中主要包含3个部分内容:
-
Contiguous memory
该模块将 F d − 1 , F d , 1 , F d , c , F d C F_{d-1},F_{d,1},F_{d,c},F_{dC} Fd−1,Fd,1,Fd,c,FdC的特征都结合起来;
-
Local feature fusion
该模块是concat之后的 1 ∗ 1 1*1 1∗1卷积操作,该操作的作用是CM后非常多的feature map不易于模型训练,利用该模块对输出的维度进行了压缩.
-
Local residual learning
该模块表示将 F d − 1 F_{d-1} Fd−1和 F d , L F F_{d,LF} Fd,LF的特征进行融合,该操作有助于提升模型的表达能力;
F d = F d − 1 + F d , L F F _ { d } = F _ { d - 1 } + F _ { d , L F } Fd=Fd−1+Fd,LF
(3) DFF(Dense feature fusion)
该模块主要包含两个模块,Global feature fusion和Global Residual learning,其中Global feature fusion模块的作用是将 F 1 , F 2 , . . . . . . F D F_1,F_2,......FD F1,F2,......FD联合起来 F G F = H G F F ( [ F 1 , ⋯   , F D ] ) F _ { G F } = H _ { G F F } \left( \left[ F _ { 1 } , \cdots , F _ { D } \right] \right) FGF=HGFF([F1,⋯,FD]),Global Residual learning表示将 F − 1 F_{-1} F−1和 F G F F_{GF} FGF相加得到 F D F F_{DF} FDF输出, F D F = F − 1 + F G F F _ { D F } = F _ { - 1 } + F _ { G F } FDF=F−1+FGF.该操作和RDB操作一样.
(4) UPNet(Up-sampleing net)
该模块在网络的最后利用上采样和卷积实现图像的放大.
RDN与DenseNet区别:
- RDN中去掉了DenseNet中的BN和pooling模块;
- DenseNet中只有每一个dense block的输出是concat起来的,而RDB中的利用局部特征融合将RDB中的各层信息都进行了融合;
- RDN利用全局特征融合将各个RDB模块中的信息都concat起来,并利用了最开始的特征;
RDN与SRDenseNet的区别:
- RDN加入了contiguous memory,使得先前的RDB模块和当前的模块信息直接融合,利用LFF,RDB模块可以利用更大的增长率;RDB中的LRF的应用增加了信息和梯度的流动;
- RDB内部没有密集连接.
- RDB使用了L1 loss,而SRDenseNet使用了L2 loss;
RDN与MemNet区别:
- MemNet需要对原图使用Bicubic插值方式对低分辨率图像进行上采样,RDN直接使用低分辨率图像进行处理,减少了计算量和提高效率;
- Memnet中包含逆向和门限单元模块,不接受先前模块的输入,而RDB的各个模块之间是有信息交流的;
- MemNet没有全部利用中间的特征信息,而RDN利用GRL将所有的信息都利用起来;
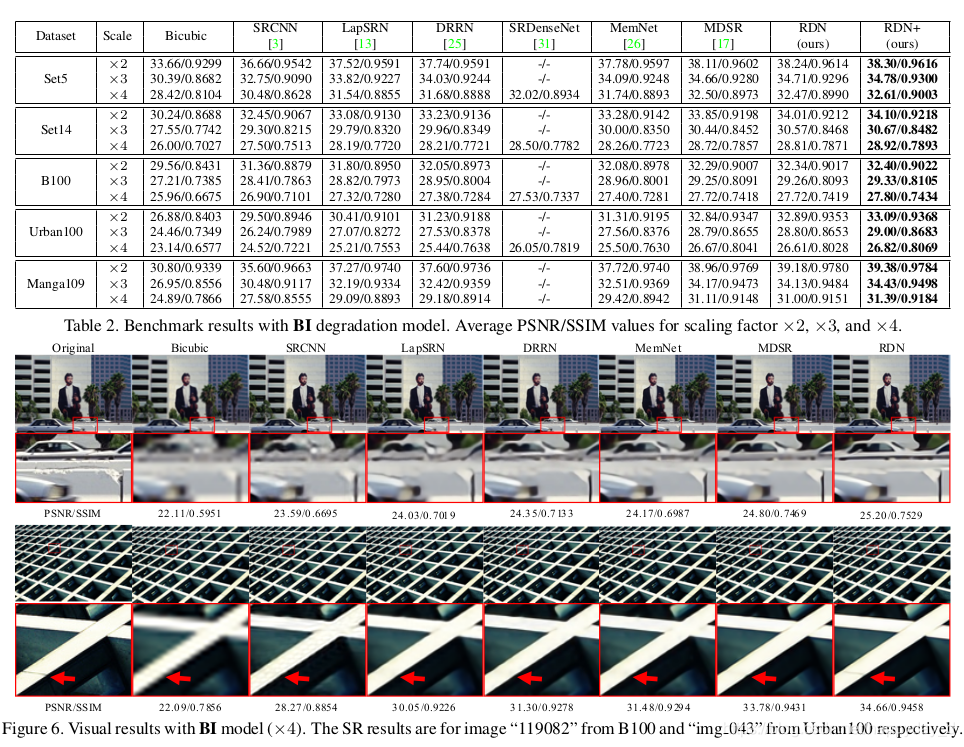
3.结果分析
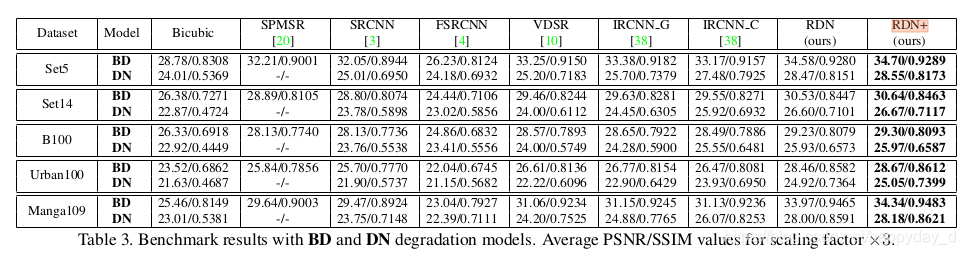
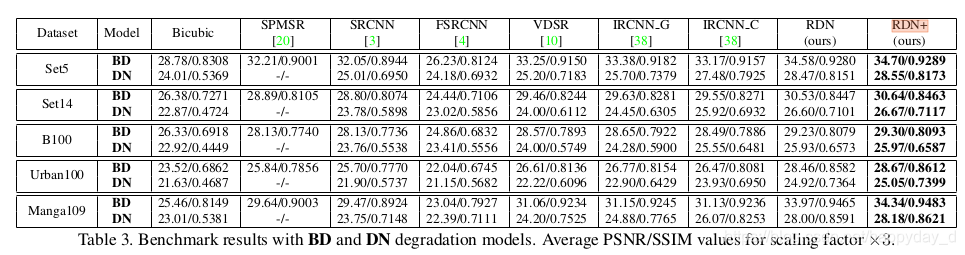
训练数据集:利用DIV2K进行训练,进行如下3种处理:
(1) BI方式:通过Bicubic对图像进行下采样,缩小比例为x2,x3,x4;
(2)BD方式:先对原图进行( 7 ∗ 7 7*7 7∗7卷积,方差为1.6)的高斯滤波,再对滤波后的图像进行下采样;
(3)DN方法:先做Bicubic下采样,再加上30%的高斯噪声;



4.参考
1.https://blog.youkuaiyun.com/qq_14845119/article/details/81459859
5.附录
RDB的Pytorch代码实现如下:
class RDB_Conv(nn.Module):
def __init__(self, inChannels, growRate, kSize=3):
super(RDB_Conv, self).__init__()
Cin = inChannels
G = growRate
self.conv = nn.Sequential(*[
nn.Conv2d(Cin, G, kSize, padding=(kSize-1)//2, stride=1),
nn.ReLU()
])
def forward(self, x):
out = self.conv(x)
return torch.cat((x, out), 1)
class RDB(nn.Module):
def __init__(self, growRate0, growRate, nConvLayers, kSize=3):
super(RDB, self).__init__()
G0 = growRate0
G = growRate
C = nConvLayers
convs = []
for c in range(C):
convs.append(RDB_Conv(G0 + c*G, G))
self.convs = nn.Sequential(*convs)
# Local Feature Fusion
self.LFF = nn.Conv2d(G0 + C*G, G0, 1, padding=0, stride=1)
def forward(self, x):
return self.LFF(self.convs(x)) + x
RDN的Pytorch代码如下:
class RDN(nn.Module):
def __init__(self, args):
super(RDN, self).__init__()
r = args.scale[0]
G0 = args.G0
kSize = args.RDNkSize
# number of RDB blocks, conv layers, out channels
self.D, C, G = {
'A': (20, 6, 32),
'B': (16, 8, 64),
}[args.RDNconfig]
# Shallow feature extraction net
self.SFENet1 = nn.Conv2d(args.n_colors, G0, kSize, padding=(kSize-1)//2, stride=1)
self.SFENet2 = nn.Conv2d(G0, G0, kSize, padding=(kSize-1)//2, stride=1)
# Redidual dense blocks and dense feature fusion
self.RDBs = nn.ModuleList()
for i in range(self.D):
self.RDBs.append(
RDB(growRate0 = G0, growRate = G, nConvLayers = C)
)
# Global Feature Fusion
self.GFF = nn.Sequential(*[
nn.Conv2d(self.D * G0, G0, 1, padding=0, stride=1),
nn.Conv2d(G0, G0, kSize, padding=(kSize-1)//2, stride=1)
])
# Up-sampling net
if r == 2 or r == 3:
self.UPNet = nn.Sequential(*[
nn.Conv2d(G0, G * r * r, kSize, padding=(kSize-1)//2, stride=1),
nn.PixelShuffle(r),
nn.Conv2d(G, args.n_colors, kSize, padding=(kSize-1)//2, stride=1)
])
elif r == 4:
self.UPNet = nn.Sequential(*[
nn.Conv2d(G0, G * 4, kSize, padding=(kSize-1)//2, stride=1),
nn.PixelShuffle(2),
nn.Conv2d(G, G * 4, kSize, padding=(kSize-1)//2, stride=1),
nn.PixelShuffle(2),
nn.Conv2d(G, args.n_colors, kSize, padding=(kSize-1)//2, stride=1)
])
else:
raise ValueError("scale must be 2 or 3 or 4.")
def forward(self, x):
f__1 = self.SFENet1(x)
x = self.SFENet2(f__1)
RDBs_out = []
for i in range(self.D):
x = self.RDBs[i](x)
RDBs_out.append(x)
x = self.GFF(torch.cat(RDBs_out,1))
x += f__1
return self.UPNet(x)
论文个人理解,如有问题,烦请指正,谢谢!

















 6804
6804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









