







 XGBoost是一种高效的GBDT实现,以其速度和性能优势在机器学习领域广泛应用。本文深入探讨XGBoost的基本思路和原理,包括目标函数、损失函数的泰勒展开、树的构建策略等,旨在揭示其逐步优化预测值与真实值差异的机制。此外,还介绍了XGBoost的一些优化点,如快速停止和步长收缩。
XGBoost是一种高效的GBDT实现,以其速度和性能优势在机器学习领域广泛应用。本文深入探讨XGBoost的基本思路和原理,包括目标函数、损失函数的泰勒展开、树的构建策略等,旨在揭示其逐步优化预测值与真实值差异的机制。此外,还介绍了XGBoost的一些优化点,如快速停止和步长收缩。
引言
XGBoost 自诞生以来,就屡次在国际机器学习大赛中摘取桂冠,风头隐隐有超过深度学习之势,堪称机器学习的"大杀器"。今天我们就来揭开 XGBoost 的神秘面纱,瞧瞧它的庐山真面目。
一、XGBoost 简介
XGBoost 跟上一篇的 AdaBoost 都属于集成学习的范畴,即利用多个弱学习器组成最终的强学习器。
说到 XGBoost 不得不提 GBDT(Gradient Boosting Decision Tree), XGBoost 是 GBDT 思想的一种实现,把速度和性能提升到了极致,所以XGBoost 的 “X” 是 “Extreme” 的意思。
二、XGBoost 的基本思路
回想决策树中,我们用不同的属性划分分支,最终每个样本都会到达叶子节点,所以叶子节点代表了样本的分类结果。
我们知道决策树不仅可以解决分类问题(叶子节点代表一个类别), 也可以解决回归问题(叶子节点代表样本的分值),但总体思路是一样的。
举个例子,比如我们要预测某个人是否喜欢玩游戏,可以建立如下这样一棵决策树。
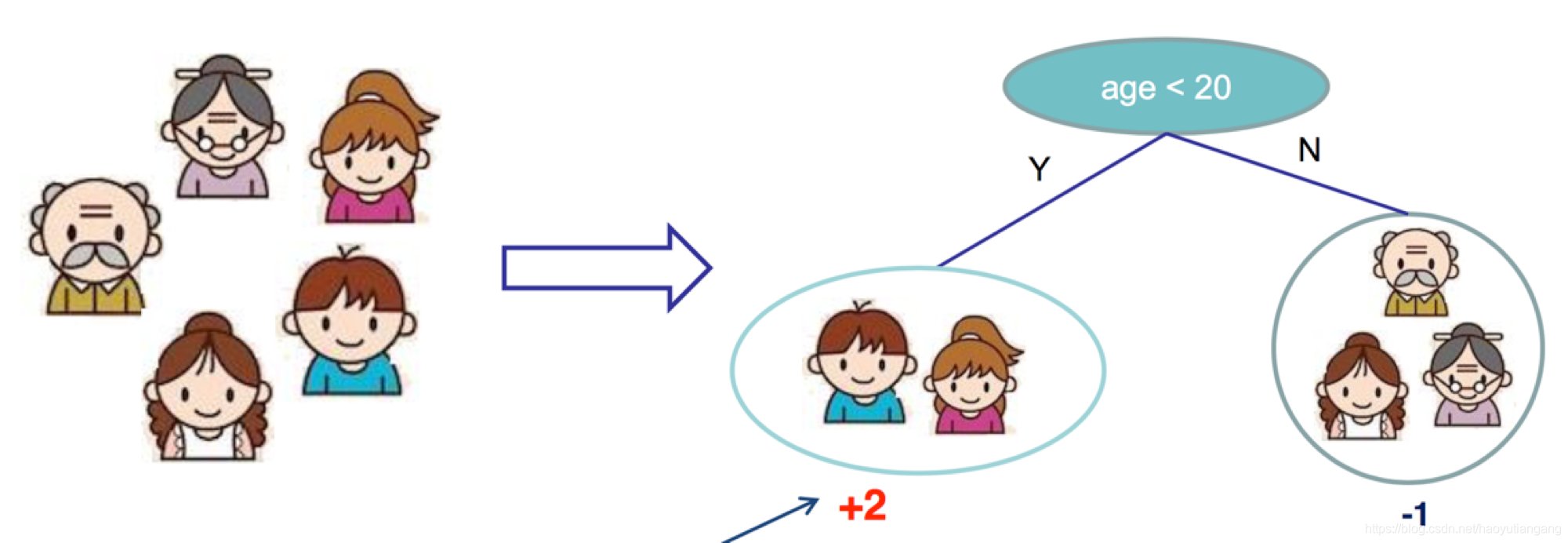
这是一个回归问题,每个样本的分值等于其所在叶子节点的分值,分值正负表示是否喜欢玩游戏,分值大小表示喜欢玩游戏的程度。
上图中我们用 “年龄” 属性建立了决策树,得出了 “age < 20” 的人喜欢玩游戏程度为 “+2”, “age >= 20” 的人喜欢玩游戏的程度为 “-1”。
但是只用一个属性建立的决策树太片面了,所以我们又用 “是否每天用电脑” 建立了第二棵决策树。
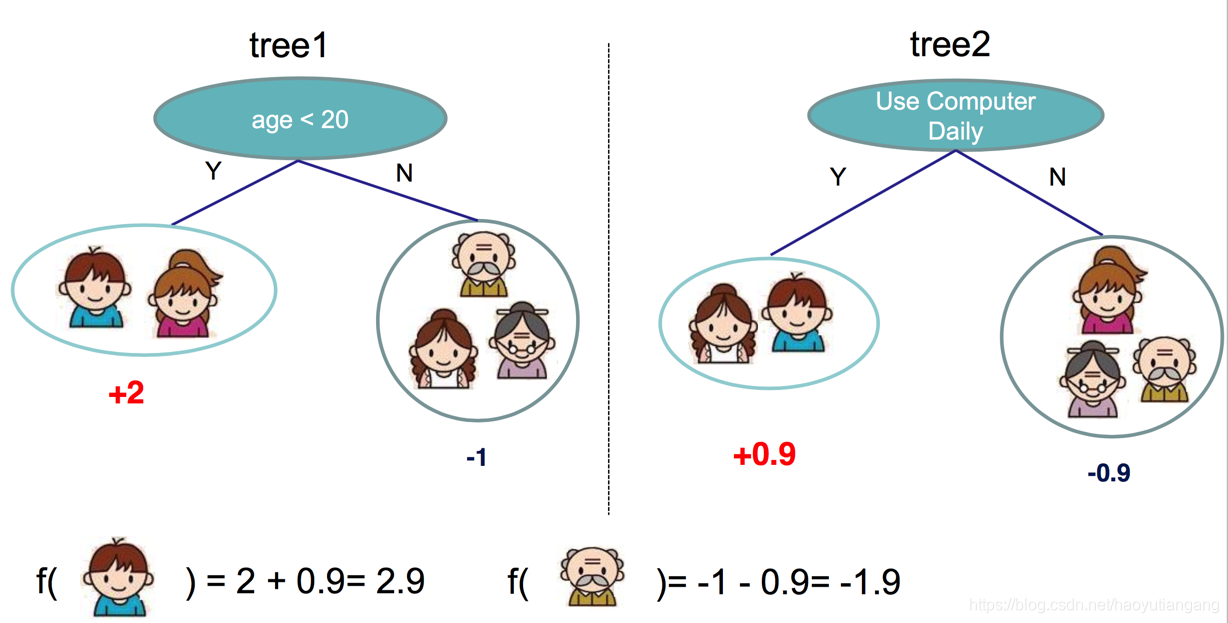
最后,我们把样本在两棵决策树中分值加起来表示样本的最后分值,例如图中小朋友的分值为 2 + 0.9 = 2.9,老爷爷的分值为 -1 + (-0.9) = -1.9
总结一下,如果我们建立 K 棵树,每个样本 x i x_i xi 的预测分值 y ^ i \hat{y}_i y^i 为该样本在每棵决策树叶子节点的分值之和。
y ^ i = ∑ t = 1 K f t ( x i ) \hat{y}_i = \sum_{t=1}^{K} f_t(x_i) y^i=t=1∑Kft(xi)
其中 f t ( x i ) f_t(x_i) ft(xi) 表示样本 x i x_i xi 第 t 棵树中所在叶子的分值。
好了,现在思考一下:每次添加一棵新树时,如何评判新添加的树对总体而言是好的还是不好的?
评判标准就是:样本 x i x_i xi 的预测值 y ^ i \hat{y}_i y^i 与样本真实值 y i y_i yi 之间的差异是否越来越小了。
举个例子:在贷款额度评估模型中,样本小王的真实贷款额度为30万, 我们看看什么是好的建树过程。
- 第一棵树:小王所在叶子分值为 20万, 此时差异 ∣ y ^ ( 1 ) − y ∣ = ∣ f 1 ( x ) − y ∣ = 10 万 |\hat{y}^{(1)} - y| = |f_1(x) - y| = 10万 ∣y^(1)−y∣=∣f1(x)−y∣=10万
- 第二棵树:小王所在叶子分值为 15万, 此时差异 ∣ y ^ ( 2 ) − y ∣ = ∣ f 1 ( x ) + f 2 ( x ) − y ∣ = 5 万 |\hat{y}^{(2)} - y| = |f_1(x) + f_2(x) - y| = 5万 ∣y^(2)−y∣=∣f1(x)+f2(x)−y∣=5万
- 第三棵树:小王所在叶子分值为 -3万, 此时差异 ∣ y ^ ( 3 ) − y ∣ = ∣ f 1 ( x ) + f 2 ( x ) + f 3 ( x ) − y ∣ = 2 万 |\hat{y}^{(3)} - y| = |f_1(x) + f_2(x) + f_3(x) - y| = 2万 ∣y^(3)−y∣=∣f1(x)+f2(x)+f3(x)−y∣=2万
可以看出,每添加一棵树,样本分值的和 y ^ ( t ) = ∑ t = 1 K f t ( x ) \hat y^{(t)} = \sum_{t=1}^K f_t(x) y^(t)=∑t=1Kft(x) 与真实值 y y y 之间的差异都在变小。换言之,每棵新树分值 f t ( x ) f_t(x) ft(x) 的目标不是 y y y 本身, 而是为了弥补之前剩下的差异 ∣ y ^ ( t − 1 ) − y ∣ |\hat y^{(t-1)} - y| ∣y^(t−1)−y∣ 。
可以看到,预测值 y ^ \hat y y^ 等于所有决策树的分值总和,每棵新树 t 都在上一次分值之和 y ^ ( t − 1 ) \hat y^{(t-1)} y^(t−1) 的基础上加上自己的分值 f t f_t ft,构成新的预测值。
书归正传,XGBoost 就是用的这种思路,每棵新树都在逐步弥补预测值与真实值之间的差异。
现在目标清楚了,问题在于 XGBoost 是如何添加新树使得新树可以逐步弥补样本差异的呢?
三、XGBoost 的原理探究
3.1 提出目标函数
现在再总结一下刚才的过程:
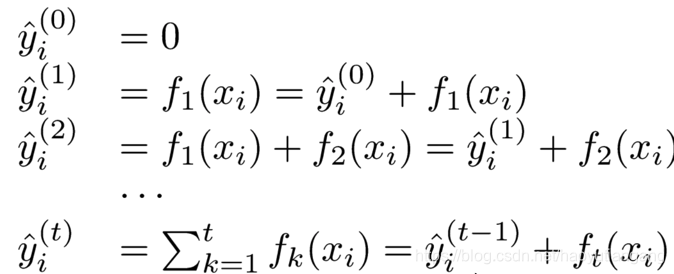
- 最初没有树,预测值 y ^ ( 0 ) \hat y^{(0)} y^(0) 为 0
- 每添加一棵树 f t f_t ft, 预测值 y ^ i ( t ) \hat y_i^{(t)} y^i(t) 为之前的预测值 y ^ i ( t − 1 ) \hat y_i^{(t-1)} y^i(t−1) 与 新树分值 f t ( x i ) f_t(x_i) ft(xi) 之和
这是一个递归加和的过程, 希望大家能够理解。
有了预测值 y ^ \hat y y^,想求 f t f_t ft,需要给出我们的目标函数。
一方面,我们想让预测值 y ^ \hat y y^ 和 真实值 y y y 之间的差异 loss 最小,这里不同算法评估差异的方式不同。比如:
- 线性回归: l o s s ( y i , y ^ i ) = ( y i − y ^ i ) 2 loss(y_i,\hat y_i) = (y_i - \hat y_i)^2 loss(yi,y^i)=(yi−y^i)2
- 逻辑回归: l o s s ( y i , y ^ i ) = y i l n ( 1 + e − y ^ i ) + ( 1 − y i ) l n ( 1 + e y ^ i ) loss(y_i,\hat y_i) = y_i\,ln(1+e^{- \hat y_i}) + (1 - y_i)\,ln(1+e^{\hat y_i}) loss(yi,y^i)=yiln(1+e−y^i)+(1−yi)ln(1+ey^i)
其他算法的 loss 计算方式可能又有不同,真正用哪种方式应该根据解决的具体问题而定,这里统称为 l ( y i , y ^ i ) l(y_i,\hat y_i) l(yi,y^i)。
另一方面,为了防止过拟合和决策树过于复杂,我们需要为每棵树添加惩罚项 Ω \Omega Ω,常用的惩罚项有以下几种:
- L1 正则化: Ω = λ ∣ ∣ w ∣ ∣ 1 = λ ∑ i = 1 n ∣ w i ∣ \Omega = \lambda\,||w||_1 = \lambda\,\sum_{i=1}^n |w_i| Ω=λ∣∣w∣∣1=λ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









