









大家好,这里是Goodnote(好评笔记)。本文是SD 模型微调方法 ControlNet详细的介绍,包括数据集准备,模型微调过程,推理过程,优缺点等。

热门专栏
机器学习
深度学习
论文
Adding Conditional Control to Text-to-Image Diffusion Models
ControlNet 是一种用于增强扩散模型可控性的模型架构,允许用户通过条件信息(如边缘图、深度图、关键点等)精确控制生成图像的内容和布局。
概念
ControlNet 的核心概念是:通过在扩散模型中添加一条控制分支,使模型能够根据特定的条件信息生成符合特定结构的图像。该条件输入可以是草图、人体姿态关键点、边缘图或深度图等。这种机制使模型在生成过程中能够参考结构化信息,从而提升图像生成的可控性。
原理
ControlNet 的原理是基于条件扩散模型(Conditional Diffusion Model),在扩散过程的每一步将条件信息与图像潜在特征 结合 ,逐步生成符合输入条件的内容。
在 ControlNet 中,通过引入条件信息,模型不再仅依赖随机噪声来生成图像,而是加入了条件信息的控制。为了实现这一点,ControlNet 引入了条件分支(Control Branch),用于对输入的条件信息(如边缘图)进行特征提取,并在扩散过程的每一层通过残差连接将条件信息与主网络的生成特征融合。
架构
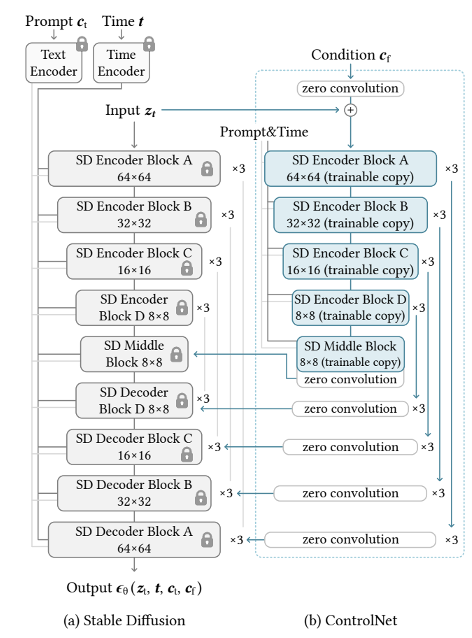
ControlNet 的架构包括一个基础扩散模型(如 SD)和一个额外的控制分支。
-
基础扩散网络(Base Diffusion Network):预训练模型,如SD,负责将噪声图像逐步去噪至最终的生成图像。
-
控制分支(Control Branch):ControlNet 增加了一个并行的控制分支,控制分支负责处理条件信息(如边缘图、姿态等),生成的特征在每一层通过残差连接与基础扩散网络融合。控制分支的特征提取网络通常由卷积层构成,以提取条件输入的高层语义信息。
-
特征融合:在每一步的扩散过程中,将用户提供的条件信息嵌入到模型生成特征中。常见的融合方式有:
| 融合方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 特征加和 | 简单高效,快速注入条件信息 | 对尺度敏感,可能会引入噪声 | 同质条件输入(如边缘图) |
| 特征拼接 | 保留完整信息,融合灵活 | 增加特征维度和计算开销 | 异质条件输入(如深度图) |
| 残差连接 | 保留生成特征结构,同时柔和引入条件特征 | 需要调节缩放系数 | 条件信息影响需可控(如姿态关键点) |
| 注意力机制 | 选择性引入条件信息,自动学习条件信息重要性 | 计算开销较大,需额外资源 | 细粒度控制(如语义分割图、多模态数据) |
详细解释如下:
1) 特征加和(Additive Fusion)
- 实现方式:将条件特征和生成特征逐像素相加。假设生成特征为 F gen F_{\text{gen}} Fgen ,条件特征为 F cond F_{\text{cond}} Fcond,则融合结果为: F fused = F gen F cond F_{\text{fused}} = F_{\text{gen}} F_{\text{cond}} Ffused=FgenFcond
- 优点:
- 简单高效,不需要额外参数。
- 在保持原始特征的基础上,轻松引入条件信息。
- 缺点:
- 如果条件特征和生成特征的尺度差异大,可能会导致信息失衡或产生噪声。
- 适用场景:适合条件特征与生成特征同质、同尺度的情况,如边缘图控制生成图像的边缘轮廓。
2) 特征拼接(Concatenation Fusion)
- 实现方式:将条件特征和生成特征在通道维度上拼接,然后通过一个卷积层或线性层进行进一步的组合。假设生成特征 F gen F_{\text{gen}} Fgen 和条件特征 F cond F_{\text{cond}} Fcond 有相同的空间维度,则拼接操作为:
F fused = Conv ( Concat ( F gen , F cond ) ) F_{\text{fused}} = \text{Conv}(\text{Concat}(F_{\text{gen}}, F_{\text{cond}})) Ffused=Conv(Concat(Fgen,Fcond))
- 优点:
- 能够保留生成特征和条件特征的全部信息。
- 融合效果更灵活,卷积层可以学习如何结合这两种特征。
- 缺点:
- 拼接会增加特征维度,增加计算开销。
- 适用场景:适合条件特征和生成特征异质的情况,如深度图和 RGB 图像的融合。
3) 残差连接(Residual Connection)
- 实现方式:类似于特征加和,但引入了权重调整。通过残差连接将条件特征注入到主生成特征中,以获得更平滑的融合。假设生成特征为
F
gen
F_{\text{gen}}
Fgen ,条件特征为
F
cond
F_{\text{cond}}
Fcond,公式如下:
F
fused
=
F
gen
α
⋅
F
cond
F_{\text{fused}} = F_{\text{gen}} \alpha \cdot F_{\text{cond}}
Ffused=Fgenα⋅Fcond
- 其中 α 是一个缩放系数,用于调整条件特征的强度。
- 优点:
- 保留主生成特征的原始结构信息,同时轻松引入条件特征。
- 缩放系数可以调节条件信息的权重,适应不同强度的条件控制。
- 缺点:
- 需要确定适当的缩放系数,否则可能导致条件信息过强或过弱。
- 适用场景:适用于需要细致控制条件信息的情况,例如姿态关键点控制人物动作的生成。
4) 注意力机制融合(Attention-Based Fusion)
- 实现方式:使用注意力机制(如自注意力或交叉注意力)对条件特征和生成特征进行融合。条件特征可以作为 Query(Q),生成特征作为 Key(K)和 Value(V),通过注意力权重引导条件信息的引入: Attention ( Q , K , V ) = softmax ( Q K T d ) \text{Attention}(Q, K, V) = \text{softmax} \left( \frac{Q K^T}{\sqrt{d}} \right) Attention(Q,K,V)=softmax(dQKT)
- 优点:
- 选择性地引入条件特征,允许模型自动学习条件特征在生成特征中的位置和重要性。
- 适合复杂的条件控制,如复杂场景中的语义分割图控制。
- 缺点:
- 计算开销较大,尤其在大尺寸特征图时可能需要更多资源。
- 适用场景:适用于需要细粒度控制的场景,如复杂场景布局或多条件信息(如分割图、多模态数据)。
训练过程
数据集准备
在训练 ControlNet 时,数据集通常需要包含:
- 原始图像(Target Image)
- 文本描述(Text Description)
- 条件信息(Conditioning Information)
原始图像(Target Image)
- 用途:原始图像是 ControlNet 用于学习生成的目标,模型需要基于这些图像及其条件信息来学习生成过程。
- 格式:通常是 RGB 图像,分辨率根据任务需求而定(如 256x256、512x512 或更高)。
文本描述(Text Description)
- 用途:有时数据集还会包含与图像内容相关的文本描述,用于条件生成或跨模态生成任务(如从文本生成符合描述的图像)。
- 格式:通常是短文本,可以描述图像的内容、主题、场景等。
条件信息(Conditioning Information)
-
用途:条件信息是 ControlNet 用于控制生成内容的指导信息,可以是图像的边缘、深度、姿态或语义分割等。
-
类型:根据任务需求,条件信息可以包括以下几种常见的类型:
-
边缘图(Edge Map)
-
生成方式:通常通过边缘检测算法(如 Canny 边缘检测)从原始图像中提取。
-
用途:边缘图用于定义图像的主要轮廓和结构,适合用于图像轮廓控制任务,例如基于草图生成图像。
-
-
深度图(Depth Map)
-
生成方式:可以使用深度估计算法(如 MiDaS)从原始图像中生成深度图。
-
用途:深度图表示图像中不同区域的深度信息,使模型能够生成具有三维空间感的图像,适用于场景重建或空间结构生成。
-
-
姿态关键点(Pose Keypoints)
-
生成方式:使用姿态检测算法(如 OpenPose)从人物图像中提取关节点。
-
用途:姿态关键点用于控制人物的动作和姿势,非常适用于人物生成、动画角色设计等任务。
-
-
语义分割图(Semantic Segmentation Map)
-
生成方式:使用语义分割模型(如 DeepLab)对图像进行分割,得到每个像素的类别标签。
-
用途:语义分割图用于控制图像的布局和组成部分(如天空、建筑物、树木等),适用于复杂场景生成。
-
-
手绘草图(Sketch)
-
生成方式:可以通过用户手绘或自动生成算法将图像转换为草图。
-
用途:草图可用于控制生成图像的大致形状和内容布局,适合艺术创作或草图到图像的生成任务。
-
-
其他结构化条件(如颜色分布图、深度层次图等)
- 用途:用于更精细或特定的控制需求,例如控制颜色区域、物体分层结构等。
训练过程包括前向传播、计算损失和反向传播:
前向传播(Forward Pass)
在前向传播过程中,ControlNet 逐步将条件信息注入到扩散模型的生成过程,使得生成特征可以在去噪过程的每一步参考条件信息。假设我们在使用 Stable Diffusion 作为基础模型,前向传播过程的关键步骤如下:
初始化输入
- 噪声图像输入:扩散模型通常从一个随机噪声图像(如高斯噪声图像)开始生成过程,逐步去噪生成目标图像。
- 条件输入:ControlNet 还接收一个条件信息(如边缘图、深度图或姿态关键点等),并将其传递给控制分支。
条件分支特征提取
- 条件输入会首先通过 控制分支(Control Branch),该分支通常由多层卷积层组成,用于提取条件信息的特征。假设条件输入为边缘图,则控制分支会**提取出边缘特征 F cond F_{\text{cond}} Fcond
主分支的特征表示
- 与条件分支并行,主扩散模型的生成分支(通常为 U-Net)接收噪声图像并开始逐层去噪。扩散模型在每一层中计算生成特征 F gen F_{\text{gen}} Fgen,这些生成特征在每一步都代表了当前的去噪状态。
特征融合
- 在扩散模型的每一层,将条件特征 F cond F_{\text{cond}} Fcond 与生成特征 F gen F_{\text{gen}} Fgen 进行融合得到 F fused F_{\text{fused}} Ffused。特征融合方式根据设计可以是特征加和、拼接、残差连接或注意力机制(参考上面架构中的融合方式)。
逐步去噪
- 融合后的特征 F fused F_{\text{fused}} Ffused 传递到下一层,模型继续逐步去噪。在扩散模型的每一层,都会重复特征融合的过程,使条件特征在整个生成过程中持续影响生成内容。
- 经过 T 次去噪步长,模型生成出符合条件输入的图像。
损失计算
在前向传播结束后,计算生成结果与目标图像之间的损失。总损失函数表示为去噪损失和一致性损失的加权和:
L
=
λ
diffusion
L
diffusion
+
λ
consistency
L
consistency
L = \lambda_{\text{diffusion}} L_{\text{diffusion}} + \lambda_{\text{consistency}} L_{\text{consistency}}
L=λdiffusionLdiffusion+λconsistencyLconsistency
- 其中, λ diffusion \lambda_{\text{diffusion}} λdiffusion 和 λ consistency \lambda_{\text{consistency}} λconsistency 是控制损失的权重。
去噪损失(Diffusion Loss):如同其他扩散模型,ControlNet 在每一步的损失通常是去噪误差,主要作用于主生成分支(扩散模型的 U-Net 结构)。
L diffusion = E x 0 , y , t , ϵ [ ∥ ϵ − ϵ θ ( x t , y , t ) ∥ 2 ] L_{\text{diffusion}} = \mathbb{E}_{x_0, y, t, \epsilon} [ \| \epsilon - \epsilon_{\theta}(x_t, y, t) \|^2 ] Ldiffusion=Ex0,y,t,ϵ[∥ϵ−ϵθ(xt,y,t)∥2]
其中:
- x 0 x_0 x0:目标图像,即我们希望模型生成的真实图像。
- x t x_t xt:在步骤 t t t 时的噪声图像。该图像是在 x 0 x_0 x0 上加入噪声生成的,以模拟扩散模型的生成过程。
- y y y:条件输入,如边缘图、深度图、姿态关键点等。
- ϵ \epsilon ϵ:实际添加到图像上的噪声,表示原始图像与噪声图像之间的差距。
- ϵ θ ( x t , y , t ) \epsilon_{\theta}(x_t, y, t) ϵθ(xt,y,t):模型在步骤 t t t 时预测的噪声,即模型希望去除的噪声。
一致性损失(Consistency Loss)(可选):是 ControlNet 特有的损失项,用于确保生成图像符合输入条件的结构化信息。通过一致性损失,可以让模型在生成图像时更好地遵循条件输入的布局或结构。这个损失主要作用于控制分支。
一致性损失的公式视具体的条件输入类型而定。例如,对于边缘图控制的任务,一致性损失可以是生成图像边缘与输入边缘图之间的均方误差(MSE):
L consistency = E x 0 , y [ ∥ f ( x 0 ) − y ∥ 2 ] L_{\text{consistency}} = \mathbb{E}_{x_0, y} [ \| f(x_0) - y \|^2 ] Lconsistency=Ex0,y[∥f(x0)−y∥2]
其中:
- x 0 x_0 x0:生成的目标图像。
- y y y:条件输入的特征表示(如边缘图、深度图、姿态关键点等)。
- f ( x 0 ) f(x_0) f(x0):生成图像提取的条件特征。比如,如果条件输入是边缘图,则 f ( x 0 ) f(x_0) f(x0)表示生成图像的边缘图,通常通过边缘检测算法从生成图像中提取。
特征表示
特征表示是一个多维的特征图(feature map),包含丰富的空间信息和通道信息,通常是一个多维张量。这个张量捕捉了图像或条件输入的结构特征和语义信息。以下是关于特征表示的详细解释:
特征表示的结构
在深度学习模型中,特征表示通常是一个三维或四维张量。对于 ControlNet 中的条件输入和生成图像的特征表示,这些特征图结构通常如下:
- 大小:特征图的大小通常是 H×W×C的张量。
- H 和 W:表示特征图的高度和宽度。
- C:表示特征图的通道数(通常包含语义信息)。
例如,假设某一层的特征图大小为 64×64×128,其中:
- 64×64 表示特征图的空间分辨率。
- 128 表示通道数,每个通道可以视作捕捉了图像的一种特定模式或结构信息。
特征表示的生成
-
条件输入的特征表示 y:
- 条件输入(如边缘图或姿态图)通过控制分支(通常是卷积网络)提取特征,生成一个包含结构化信息的特征图。
- 例如,对于输入的姿态关键点图,控制分支可能生成一个 64×64×128的特征图。这个特征图会包含姿态图的布局和关键点信息。
-
生成图像的特征表示 f(x):
- 生成图像在扩散过程中逐步去噪,生成特征图表示当前生成图像的状态。
- 在与控制分支融合时,我们通常会选择生成分支中间层的特征图(如 64×64×128)来对比结构信息,以确保一致性。
特征表示对比与一致性损失计算
在计算一致性损失时,生成分支和控制分支的特征图会逐元素进行比较,因此损失计算的实际操作是将两个特征图进行逐像素、逐通道的差异计算。例如:
L consistency = 1 H × W × C ∑ i , j , k ( f ( x ) i , j , k − y i , j , k ) 2 L_{\text{consistency}} = \frac{1}{H \times W \times C} \sum_{i,j,k} (f(x)_ {i,j,k} - y_{i,j,k})^2 Lconsistency=H×W×C1i,j,k∑(f(x)i,j,k−yi,j,k)2
- 其中 f ( x ) i , j , k f(x)_ {i,j,k} f(x)i,j,k 和 y i , j , k y_{i,j,k} yi,j,k 分别表示生成特征和条件特征在 ( i , j ) (i, j) (i,j) 位置和第 k k k 个通道上的值。
- 通过对整个特征图的逐元素均方误差(MSE)进行计算,模型可以评估生成图像与条件输入结构的一致性,并在训练中逐步优化这一结构匹配。
反向传播(Backward Pass)
在反向传播过程中,模型通过梯度下降算法更新 控制分支和主扩散分支的参数,使得生成结果逐步符合条件信息并逼近目标图像。
计算损失的梯度
- 损失梯度计算:根据损失函数 L 计算每个参数的梯度。对于扩散损失 L diffusion L_{\text{diffusion}} Ldiffusion 和一致性损失 L consistency L_{\text{consistency}} Lconsistency,使用链式法则逐层计算梯度。
- 对于主生成分支的权重
W
gen
W_{\text{gen}}
Wgen,计算梯度为:
∂ L ∂ W gen \frac{\partial L}{\partial W_{\text{gen}}} ∂Wgen∂L - 对于控制分支的权重
W
cond
W_{\text{cond}}
Wcond,计算梯度为:
∂ L ∂ W cond \frac{\partial L}{\partial W_{\text{cond}}} ∂Wcond∂L
反向传播通过特征融合层
- 在特征融合层中,控制分支和生成分支的梯度会分别反向传播:
- 主扩散分支/生成分支的梯度:主扩散分支的梯度会在每一层通过特征融合层向前传递,使得主扩散分支能够更好地学习去噪和生成结构。
- 控制分支的梯度:控制分支的梯度通过融合层向控制分支反向传播,调整控制分支的特征提取权重,以使条件特征更准确。
参数更新
- 使用优化算法(如 Adam 或 SGD)更新模型的权重。更新后的权重反映了条件输入对生成过程的控制:
-
生成分支权重更新:
W gen = W gen − η ∂ L ∂ W gen W_{\text{gen}} = W_{\text{gen}} - \eta \frac{\partial L}{\partial W_{\text{gen}}} Wgen=Wgen−η∂Wgen∂L -
控制分支权重更新:
W cond = W cond − η ∂ L ∂ W cond W_{\text{cond}} = W_{\text{cond}} - \eta \frac{\partial L}{\partial W_{\text{cond}}} Wcond=Wcond−η∂Wcond∂L
- 其中, η \eta η 是学习率。
迭代训练
- 重复前向传播和反向传播步骤,直到损失函数收敛。随着训练的进行,模型会逐步学会在生成过程中利用条件输入生成符合目标的图像。
推理过程
在 ControlNet 微调后 Stable Diffusion 模型的 推理过程 中,流程与训练过程中的前向传播非常相似,但存在一些关键区别。在推理中,不会有损失计算和反向传播的参数更新。


















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









