




 本文介绍了一种名为正交策略梯度的算法,该算法通过使策略梯度向量与Q-Value向量正交,实现了奖励函数的极大化。通过在智能自动驾驶场景中的应用,展示了该方法在实时逼近最优值上的有效性。
本文介绍了一种名为正交策略梯度的算法,该算法通过使策略梯度向量与Q-Value向量正交,实现了奖励函数的极大化。通过在智能自动驾驶场景中的应用,展示了该方法在实时逼近最优值上的有效性。
【讲义】正交策略梯度法和自动驾驶应用
本文是论文Orthogonal Policy Gradient and Autonomous Driving Application的讲解讲义,本文中我们从一个关于奖励函数的回报梯度定理出发,证明了"当策略梯度向量和Q-Value向量正交时,奖励函数值为极大值",由此得出了一种实时逼近最优值的方法,并实现了这种方法且应用在了智能自动驾驶上.
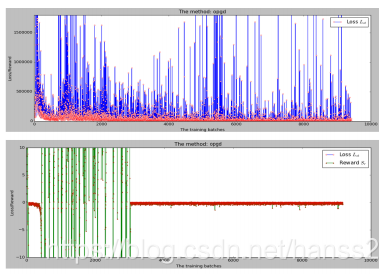
关于奖励函数的回报梯度的定理
在此先证这个定理:在MDP(Markov Decision Process)中: 平均回报函数ρ\rhoρ和策略π\piπ及Q函数QπQ^{\pi}Qπ满足:
∂ρ∂θ=∑adπ(s)∑a∂π(s,a)∂θQπ(s,a)\frac{\partial \rho}{\partial \theta} = \sum_{a}d^\pi(s) \sum_a \frac{\partial \pi(s,a)}{\partial \theta} Q^\pi(s,a)∂θ∂ρ=a∑dπ(s)a∑∂θ∂π(s,a)Qπ(s,a)
证明:
累计奖励可写作:Vπ(s)=∑aπ(s,a)Qπ(s,a)V^{\pi}(s) = \sum_a \pi(s,a) Q^\pi(s,a) Vπ(s)=a∑π(s,a)Qπ(s,a)
可得:
∂Vπ(s)∂θ=∂∂θ∑aπ(s,a)Qπ(s,a)\frac{\partial V^{\pi}(s)}{\partial \theta} =\frac{\partial}{\partial \theta} \sum_a \pi(s,a) Q^\pi(s,a) ∂θ∂Vπ(s)=∂θ∂a∑π(s,a)Qπ(s,a)
=∑a(∂π(s,a)∂θQπ(s,a)+π(s,a)∂Qπ(s,a)∂θ) =\sum_a (\frac{\partial \pi(s,a)}{\partial \theta} Q^\pi(s,a) + \pi(s,a)\frac{\partial Q^\pi(s,a)}{\partial \theta} ) =a∑(∂θ∂π(s,a)Qπ(s,a)+π(s,a)∂θ∂Qπ(s,a))
=∑a(∂π(s,a)∂θQπ(s,a)+π(s,a)∂∂θ(Ras−ρ(π)+∑s′Pss′aVπ(s′)))=\sum_a (\frac{\partial \pi(s,a)}{\partial \theta} Q^\pi(s,a) + \pi(s,a)\frac{\partial }{\partial \theta}(R^s_a-\rho(\pi)+\sum_{s'}P^a_{ss'} V^\pi(s')) ) =a∑(∂θ∂π(s,a)Qπ(s,a)+π(s,a)∂θ∂(Ras−ρ(π)+s′∑Pss′aVπ(s′)))
=∑a(∂π(s,a)∂θQπ(s,a)+π(s,a)(−∂ρ∂θ+∑s′Pss′a∂Vπ(s′)∂θ))=\sum_a (\frac{\partial \pi(s,a)}{\partial \theta} Q^\pi(s,a) + \pi(s,a)(-\frac{\partial \rho}{\partial \theta}+\sum_{s'}P^a_{ss'} \frac{\partial V^\pi(s')}{\partial \theta}) )=a∑(∂θ∂π(s,a)Qπ(s,a)+π(s,a)(−∂θ∂ρ+s′∑Pss′a∂θ∂Vπ(s′)))
由dπd^\pidπ项累加可得:
∑sdπ(s)∂ρ∂θ=∑sdπ(s)∑a∂π(s,a)∂θQπ(s,a)+∑sdπ(s)∑aπ(s,a)∑s′Pss′a∂Vπ(s′)∂θ)−∑sdπ(s)∂Vπ(s)∂θ\sum_s d^\pi(s) \frac{\partial \rho}{\partial \theta} = \sum_s d^\pi(s) \sum_a \frac{\partial \pi(s,a)}{\partial \theta} Q^\pi(s,a) + \sum_s d^\pi(s) \sum_a \pi(s,a) \sum_{s'}P^a_{ss'} \frac{\partial V^\pi(s')}{\partial \theta}) - \sum_s d^\pi(s) \frac{\partial V^{\pi}(s)}{\partial \theta}s∑dπ(s)∂θ∂ρ=s∑dπ(s)a∑∂θ∂π(s,a)Qπ(s,a)+s∑dπ(s)a∑π(s,a)s′∑Pss′a∂θ∂Vπ(s′))−s∑dπ(s)∂θ∂Vπ(s)
再由dπd^\pidπ的恒定性我们可得:
∑sdπ(s)∂ρ∂θ=∑sdπ(s)∑a∂π(s,a)∂θQπ(s,a)+∑s′∈Sdπ(s′)∂Vπ(s′)∂θ−∑s∈Sdπ(s)∂Vπ(s)∂θ\sum_s d^\pi(s) \frac{\partial \rho}{\partial \theta} = \sum_s d^\pi(s) \sum_a \frac{\partial \pi(s,a)}{\partial \theta} Q^\pi(s,a) + \sum_{s' \in S} d^\pi(s') \frac{\partial V^{\pi}(s')}{\partial \theta} - \sum_{s \in S} d^\pi(s) \frac{\partial V^{\pi}(s)}{\partial \theta}s∑dπ(s)∂θ∂ρ=s∑dπ(s)a∑∂θ∂π(s,a)Qπ(s,a)+s′∈S∑dπ(s′)∂θ∂Vπ(s′)−s∈S∑dπ(s)∂θ∂Vπ(s)
⇒∂ρ∂θ=∑adπ(s)∑a∂π(s,a)∂θQπ(s,a)\Rightarrow \frac{\partial \rho}{\partial \theta} = \sum_{a}d^\pi(s) \sum_a \frac{\partial \pi(s,a)}{\partial \theta} Q^\pi(s,a)⇒∂θ∂ρ=a∑dπ(s)a∑∂θ∂π(s,a)Qπ(s,a)
得证.
有了这个定理我们不难发现,
∑a∂π(s,a)∂θQπ(s,a)=∂π∂θ⃗⊙Q⃗\sum_a \frac{\partial \pi(s,a)}{\partial \theta} Q^\pi(s,a) =\vec{ \frac{\partial \pi}{\partial \theta}} \odot \vec{Q}a∑∂θ∂π(s,a)Qπ(s,a)=∂θ∂π⊙Q
这意味着只需要使∣∣∂π∂θ⃗⊙Q⃗∣∣=0||\vec{ \frac{\partial \pi}{\partial \theta}} \odot \vec{Q}||=0∣∣∂θ∂π⊙Q∣∣=0即正交即可满足达到极值点。
用于自动驾驶
我们的实验环境是Torcs.《The Open Racing Car Simulator》(TORCS)是一款开源3D赛车模拟游戏.是在Linux操作系统上广受欢迎的赛车游戏.有50种车辆和20条赛道,简单的视觉效果.用C和C++写成,释放在GPL协议下.
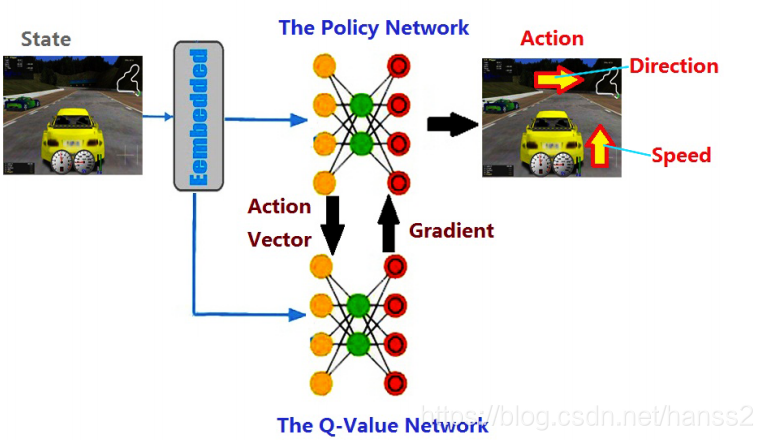
整体架构是,由策略网络负责给出具体的驾驶操作,由Q值网络负责给出对驾驶操作达到的效果做预期评估.(这和人类的智能行为类似,是标准的Deep Reinforcement learning套路:行动能力和思考能力兼备).

















 3839
3839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









