




 本文介绍如何利用OpenCV库中的背景消除方法处理视频和图片序列,并提供了完整的示例代码。通过cv::BackgroundSubtractor类创建背景模型并更新,同时展示如何获取前景掩码。
本文介绍如何利用OpenCV库中的背景消除方法处理视频和图片序列,并提供了完整的示例代码。通过cv::BackgroundSubtractor类创建背景模型并更新,同时展示如何获取前景掩码。
方法的任务就是
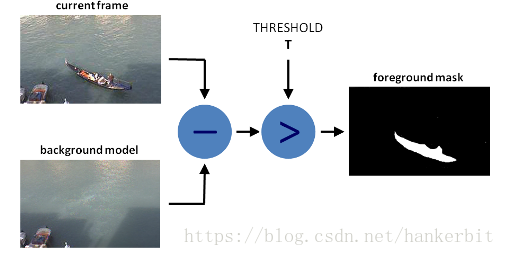
核心函数
- Read data from videos by using cv::VideoCapture or image sequences by using cv::imread ;
- Create and update the background model by using cv::BackgroundSubtractor class;
- Get and show the foreground mask by using cv::imshow ;
- Save the output by using cv::imwrite to quantitatively evaluate the results.
示例代码
//opencv
#include "opencv2/imgcodecs.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/videoio.hpp"
#include <opencv2/highgui.hpp>
#include <opencv2/video.hpp>
//C
#include <stdio.h>
//C++
#include <iostream>
#include <sstream>
using namespace cv;
using namespace std;
// Global variables
Mat frame; //current frame
Mat fgMaskMOG2; //fg mask fg mask generated by MOG2 method
Ptr<BackgroundSubtractor> pMOG2; //MOG2 Background subtractor
char keyboard; //input from keyboard
void help();
void processVideo(char* videoFilename);
void processImages(char* firstFrameFilename);
void help()
{
cout
<< "--------------------------------------------------------------------------" << endl
<< "This program shows how to use background subtraction methods provided by " << endl
<< " OpenCV. You can process both videos (-vid) and images (-img)." << endl
<< endl
<< "Usage:" << endl
<< "./bg_sub {-vid <video filename>|-img <image filename>}" << endl
<< "for example: ./bg_sub -vid video.avi" << endl
<< "or: ./bg_sub -img /data/images/1.png" << endl
<< "--------------------------------------------------------------------------" << endl
<< endl;
}
int main(int argc, char* argv[])
{
//print help information
help();
//check for the input parameter correctness
if(argc != 3) {
cerr <<"Incorret input list" << endl;
cerr <<"exiting..." << endl;
return EXIT_FAILURE;
}
//create GUI windows
namedWindow("Frame");
namedWindow("FG Mask MOG 2");
//create Background Subtractor objects
pMOG2 = createBackgroundSubtractorMOG2(); //MOG2 approach
if(strcmp(argv[1], "-vid") == 0) {
//input data coming from a video
processVideo(argv[2]);
}
else if(strcmp(argv[1], "-img") == 0) {
//input data coming from a sequence of images
processImages(argv[2]);
}
else {
//error in reading input parameters
cerr <<"Please, check the input parameters." << endl;
cerr <<"Exiting..." << endl;
return EXIT_FAILURE;
}
//destroy GUI windows
destroyAllWindows();
return EXIT_SUCCESS;
}
void processVideo(char* videoFilename) {
//create the capture object
VideoCapture capture(videoFilename);
if(!capture.isOpened()){
//error in opening the video input
cerr << "Unable to open video file: " << videoFilename << endl;
exit(EXIT_FAILURE);
}
//read input data. ESC or 'q' for quitting
keyboard = 0;
while( keyboard != 'q' && keyboard != 27 ){
//read the current frame
if(!capture.read(frame)) {
cerr << "Unable to read next frame." << endl;
cerr << "Exiting..." << endl;
exit(EXIT_FAILURE);
}
//update the background model
pMOG2->apply(frame, fgMaskMOG2);
//get the frame number and write it on the current frame
stringstream ss;
rectangle(frame, cv::Point(10, 2), cv::Point(100,20),
cv::Scalar(255,255,255), -1);
ss << capture.get(CAP_PROP_POS_FRAMES);
string frameNumberString = ss.str();
putText(frame, frameNumberString.c_str(), cv::Point(15, 15),
FONT_HERSHEY_SIMPLEX, 0.5 , cv::Scalar(0,0,0));
//show the current frame and the fg masks
imshow("Frame", frame);
imshow("FG Mask MOG 2", fgMaskMOG2);
//get the input from the keyboard
keyboard = (char)waitKey( 30 );
}
//delete capture object
capture.release();
}
void processImages(char* fistFrameFilename) {
//read the first file of the sequence
frame = imread(fistFrameFilename);
if(frame.empty()){
//error in opening the first image
cerr << "Unable to open first image frame: " << fistFrameFilename << endl;
exit(EXIT_FAILURE);
}
//current image filename
string fn(fistFrameFilename);
//read input data. ESC or 'q' for quitting
keyboard = 0;
while( keyboard != 'q' && keyboard != 27 ){
//update the background model
pMOG2->apply(frame, fgMaskMOG2);
//get the frame number and write it on the current frame
size_t index = fn.find_last_of("/");
if(index == string::npos) {
index = fn.find_last_of("\\");
}
size_t index2 = fn.find_last_of(".");
string prefix = fn.substr(0,index+1);
string suffix = fn.substr(index2);
string frameNumberString = fn.substr(index+1, index2-index-1);
istringstream iss(frameNumberString);
int frameNumber = 0;
iss >> frameNumber;
rectangle(frame, cv::Point(10, 2), cv::Point(100,20),
cv::Scalar(255,255,255), -1);
putText(frame, frameNumberString.c_str(), cv::Point(15, 15),
FONT_HERSHEY_SIMPLEX, 0.5 , cv::Scalar(0,0,0));
//show the current frame and the fg masks
imshow("Frame", frame);
imshow("FG Mask MOG 2", fgMaskMOG2);
//get the input from the keyboard
keyboard = (char)waitKey( 30 );
//search for the next image in the sequence
ostringstream oss;
oss << (frameNumber + 1);
string nextFrameNumberString = oss.str();
string nextFrameFilename = prefix + nextFrameNumberString + suffix;
//read the next frame
frame = imread(nextFrameFilename);
if(frame.empty()){
//error in opening the next image in the sequence
cerr << "Unable to open image frame: " << nextFrameFilename << endl;
exit(EXIT_FAILURE);
}
//update the path of the current frame
fn.assign(nextFrameFilename);
}
}

















 3031
3031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









