




 本文详细介绍了Picoc编译器的脚本运行模式,从系统头文件处理到脚本的解析与执行。在脚本模式下,Picoc首先处理系统头文件,然后解析并执行用户指定的脚本文件。解析过程中涉及词法分析、函数定义、表达式处理等多个环节,通过PicocParse()函数实现脚本的解释和执行。文章深入探讨了关键函数如ParseStatement()的工作原理,涵盖了条件语句、循环语句等控制结构的处理流程。
本文详细介绍了Picoc编译器的脚本运行模式,从系统头文件处理到脚本的解析与执行。在脚本模式下,Picoc首先处理系统头文件,然后解析并执行用户指定的脚本文件。解析过程中涉及词法分析、函数定义、表达式处理等多个环节,通过PicocParse()函数实现脚本的解释和执行。文章深入探讨了关键函数如ParseStatement()的工作原理,涵盖了条件语句、循环语句等控制结构的处理流程。
Picoc编译器支持程序、脚本和终端三种运行模式。这篇文章主要对picoc的脚本解析和运行流程做一个整理,对其中涉及到的知识点做一些简要的解释和分析。
一、脚本运行模式
脚本模式的启动方式是通过-s参数实现。
./picoc -s test.c
该模式首先调用PicocIncludeAllSystemHeaders()函数进行系统头文件处理,然后进入到执行脚本文件处理函数PicocPlatformScanFile()的for循环,直至所有指定脚本执行完毕。所有脚本执行完毕后会调用PicocCleanup()执行清理并退出。
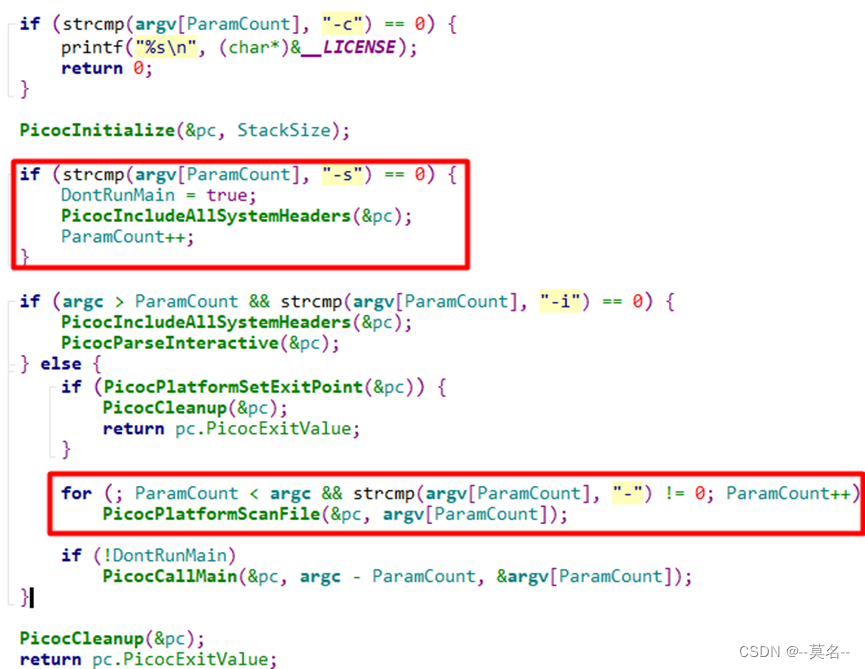
二、系统头文件处理
这里主要是调用IncludeFile()函数对初始化时包含的所有头文件(#include表达式)进行处理,即遍历Parser的包含文件列表IncludeLibList(预定义的库或实际的文件内容),并重复进行以下工作:
a.检查头文件是否已定义,未定义则进行注册,否则跳过。避免重复包含相同的库文件。
b.检查头文件是否需要运行自己的启动函数,需要则执行。
c.检查头文件中是否存在类型定义等,并调用PicocParse()进行处理。
d.检查头文件中是否存在库函数FuncList,调用LibraryAdd()对所有库函数进行处理。
LexAnalyse()àLexTokenize():对库函数进行词法分析,生成令牌并分配栈空间。返回值Tokens为指向令牌存储的栈地址。
LexInitParser()将函数信息存储到Parser结构中。
TypeParse()对库函数的类型进行解析,包含标识符的完整声明。
ParseFunctionDefinition()解析函数定义并保存。
三、脚本解释及执行
系统头文件处理完成后,调用PicocPlatformScanFile()函数对用户指定的每一个脚本文件进行解析和执行,主要工作包括:
(1)读取指定的脚本文件PlatformReadFile()。
该函数打开用户指定的脚本文件,并读取到临时分配的内存ReadText中。这里用到了C语言的stat()和fread函数,整个文件按文件大小的字节数读取到ReadText中,并在内存的结尾处加了’\0’,因此ReadText的大小是文件字节数加1。
读取完成后将ReadText中的开头的注释部分“#!”去掉(以空格字符代替)。
后续代码会将读到的文件中的“#”和“!”用“/”代替。这里实际上存在重复处理,两段代码有一段就可以了。
(2)调用PicocParse()对读取到的脚本文件进行解析和执行。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









